Python--re模块
Posted yx12138
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python--re模块相关的知识,希望对你有一定的参考价值。
正则表达式
正则表达式本身是一种小型的、高度专业化的编程语言,而在python中,通过内嵌集成re模块,程序员们可以直接调用来实现正则匹配。正则表达式模式被编译成一系列的字节码,然后由用C编写的匹配引擎执行。
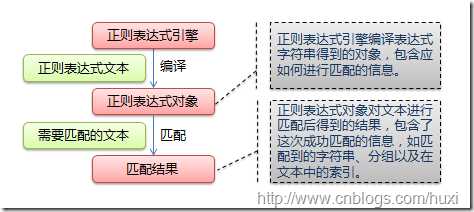
正则表达式是用来匹配处理字符串的 python 中使用正则表达式需要引入re模块
如:
import re #第一步,要引入re模块
a = re.findall("匹配规则", "要匹配的字符串") #第二步,调用模块函数
以列表形式返回匹配到的字符串
如:
 View Code
View Code
^元字符
字符串开始位置与匹配规则符合就匹配,否则不匹配
匹配字符串开头。在多行模式中匹配每一行的开头
^元字符如果写到[]字符集里就是反取
View Code[^a-z]反取,匹配出除字母外的字符,^元字符如果写到字符集里就是反取
View Code$元字符
字符串结束位置与匹配规则符合就匹配,否则不匹配
匹配字符串末尾,在多行模式中匹配每一行的末尾
View Code
*元字符
需要字符串里完全符合,匹配规则,就匹配,(规则里的*元字符)前面的一个字符可以是0个或多个原本字符
匹配前一个字符0或多次,贪婪匹配前导字符有多少个就匹配多少个很贪婪
如果规则里只有一个分组,尽量避免用*否则会有可能匹配出空字符串
View Code+元字符
需要字符串里完全符合,匹配规则,就匹配,(规则里的+元字符)前面的一个字符可以是1个或多个原本字符
匹配前一个字符1次或无限次,贪婪匹配前导字符有多少个就匹配多少个很贪婪
View Code?元字符,和防止贪婪匹配
需要字符串里完全符合,匹配规则,就匹配,(规则里的?元字符)前面的一个字符可以是0个或1个原本字符
匹配一个字符0次或1次
还有一个功能是可以防止贪婪匹配,详情见防贪婪匹配
View Code{}元字符,范围
需要字符串里完全符合,匹配规则,就匹配,(规则里的 {} 元字符)前面的一个字符,是自定义字符数,位数的原本字符
{m}匹配前一个字符m次,{m,n}匹配前一个字符m至n次,若省略n,则匹配m至无限次
{0,}匹配前一个字符0或多次,等同于*元字符
{+,}匹配前一个字符1次或无限次,等同于+元字符
{0,1}匹配前一个字符0次或1次,等同于?元字符
View Code[]元字符,字符集
需要字符串里完全符合,匹配规则,就匹配,(规则里的 [] 元字符)对应位置是[]里的任意一个字符就匹配
字符集。对应的位置可以是字符集中任意字符。字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c]。[^abc]表示取反,即非abc。
所有特殊字符在字符集中都失去其原有的特殊含义。用\\反斜杠转义恢复特殊字符的特殊含义。
View Code[^]非,反取,匹配出除[^]里面的字符,^元字符如果写到字符集里就是反取
View Code
反斜杠后边跟普通字符实现特殊功能;(即预定义字符)
预定义字符是在字符集和组里都是有用的
\\d匹配任何十进制数,它相当于类[0-9]
View Code\\d+如果需要匹配一位或者多位数的数字时用
View Code\\D匹配任何非数字字符,它相当于类[^0-9]
View Code\\s匹配任何空白字符,它相当于类[\\t\\n\\r\\f\\v]
View Code\\S匹配任何非空白字符,它相当于类[^\\t\\n\\r\\f\\v]
View Code\\w匹配包括下划线在内任何字母数字字符,它相当于类[a-zA-Z0-9_]
View Code\\W匹配非任何字母数字字符包括下划线在内,它相当于类[^a-zA-Z0-9_]
View Code()元字符,分组
也就是分组匹配,()里面的为一个组也可以理解成一个整体
如果()后面跟的是特殊元字符如 (adc)* 那么*控制的前导字符就是()里的整体内容,不再是前导一个字符
列1
View Code列2
View Code
|元字符,或
|或,或就是前后其中一个符合就匹配
View Code
r原生字符
将在python里有特殊意义的字符如\\b,转换成原生字符(就是去除它在python的特殊意义),不然会给正则表达式有冲突,为了避免这种冲突可以在规则前加原始字符r
re模块中常用功能函数
正则表达式有两种书写方式,一种是直接在函数里书写规则,
View Codematch()函数(以后常用)
match,从头匹配一个符合规则的字符串,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
match(pattern, string, flags=0)
# pattern: 正则模型
# string : 要匹配的字符串
# falgs : 匹配模式
注意:match()函数 与 search()函数基本是一样的功能,不一样的就是match()匹配字符串开始位置的一个符合规则的字符串,search()是在字符串全局匹配第一个合规则的字符串
View Code?P<n1> #?P<>定义组里匹配内容的key(键),<>里面写key名称,值就是匹配到的内容(只对正则函数返回对象的有用)
取出匹配对象方法
只对正则函数返回对象的有用
group() # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来,有参取匹配到的第几个如2
groups() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
groupdict() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
search()函数
search,浏览全部字符串,匹配第一符合规则的字符串,浏览整个字符串去匹配第一个,未匹配成功返回None
search(pattern, string, flags=0)
# pattern: 正则模型
# string : 要匹配的字符串
# falgs : 匹配模式
注意:match()函数 与 search()函数基本是一样的功能,不一样的就是match()匹配字符串开始位置的一个符合规则的字符串,search()是在字符串全局匹配第一个合规则的字符串
View Codefindall()函数(以后常用)
findall(pattern, string, flags=0)
# pattern: 正则模型
# string : 要匹配的字符串
# falgs : 匹配模式
浏览全部字符串,匹配所有合规则的字符串,匹配到的字符串放到一个列表中,未匹配成功返回空列表
注意:一旦匹配成,再次匹配,是从前一次匹配成功的,后面一位开始的,也可以理解为匹配成功的字符串,不在参与下次匹配
View Code注意:如果没写匹配规则,也就是空规则,返回的是一个比原始字符串多一位的,空字符串列表
View Code注意:正则匹配到空字符的情况,如果规则里只有一个组,而组后面是*就表示组里的内容可以是0个或者多过,这样组里就有了两个意思,一个意思是匹配组里的内容,二个意思是匹配组里0内容(即是空白)所以尽量避免用*否则会有可能匹配出空字符串
注意:正则只拿组里最后一位,如果规则里只有一个组,匹配到的字符串里在拿组内容是,拿的是匹配到的内容最后一位
View Code
无分组:匹配所有合规则的字符串,匹配到的字符串放到一个列表中
View Code有分组:只将匹配到的字符串里,组的部分放到列表里返回,相当于groups()方法
View Code多个分组:只将匹配到的字符串里,组的部分放到一个元组中,最后将所有元组放到一个列表里返
相当于在group()结果里再将组的部分,分别,拿出来放入一个元组,最后将所有元组放入一个列表返回
View Code分组中有分组:只将匹配到的字符串里,组的部分放到一个元组中,先将包含有组的组,看作一个整体也就是一个组,把这个整体组放入一个元组里,然后在把组里的组放入一个元组,最后将所有组放入一个列表返回
View Code?:在有分组的情况下findall()函数,不只拿分组里的字符串,拿所有匹配到的字符串,注意?:只用于不是返回正则对象的函数如findall()
View Code
split()函数
根据正则匹配分割字符串,返回分割后的一个列表
split(pattern, string, maxsplit=0, flags=0)
# pattern: 正则模型# string : 要匹配的字符串# maxsplit:指定分割个数# flags : 匹配模式 View Code将匹配到的字符串作为分割标准进行分割
View Codesub()函数
替换匹配成功的指定位置字符串
sub(pattern, repl, string, count=0, flags=0)
# pattern: 正则模型# repl : 要替换的字符串# string : 要匹配的字符串# count : 指定匹配个数# flags : 匹配模式 View Code
subn()函数
替换匹配成功的指定位置字符串,并且返回替换次数,可以用两个变量分别接受
subn(pattern, repl, string, count=0, flags=0)
# pattern: 正则模型# repl : 要替换的字符串# string : 要匹配的字符串# count : 指定匹配个数# flags : 匹配模式 View Code
元字符表
|
. |
需要字符串里完全符合,匹配规则,就匹配,(规则里的.元字符)可以是任何一个字符,匹配任意除换行符"\\n"外的字符(在DOTALL模式中也能匹配换行符) |
a.c |
abc |
|
\\ |
1.反斜杠后边跟元字符去除特殊功能;(即将特殊字符转义成普通字符),2.反斜杠后边跟普通字符实现特殊功能;(即预定义字符),3.\\2引用序号对应的字组 |
a\\.c;a\\\\c |
a.c;a\\c |
|
* |
需要字符串里完全符合,匹配规则,就匹配,(规则里的*元字符)前面的一个字符可以是0个或多个原本字符,匹配前一个字符0或多次,贪婪匹配前导字符有多少个就匹配多少个很贪婪,如果规则里只有一个分组,尽量避免用*否则会有可能匹配出空字符串 |
abc* |
ab;abccc |
|
+ |
需要字符串里完全符合,匹配规则,就匹配,(规则里的+元字符)前面的一个字符可以是1个或多个原本字符,匹配前一个字符1次或无限次,贪婪匹配前导字符有多少个就匹配多少个很贪婪 |
abc+ |
abc;abccc |
|
? |
需要字符串里完全符合,匹配规则,就匹配,(规则里的?元字符)前面的一个字符可以是0个或1个原本字符,匹配一个字符0次或1次,还有一个功能是可以防止贪婪匹配,详情见防贪婪匹配 |
abc? |
ab;abc |
|
^ |
字符串开始位置与匹配规则符合就匹配,否则不匹配,匹配字符串开头。在多行模式中匹配每一行的开头,^元字符如果写到[]字符集里就是反取 |
^abc |
abc |
|
$ |
字符串结束位置与匹配规则符合就匹配,否则不匹配,匹配字符串末尾,在多行模式中匹配每一行的末尾 |
abc$ |
abc |
|
| |
|或,或就是前后其中一个符合就匹配 |
abc|def |
abc def |
|
{} |
需要字符串里完全符合,匹配规则,就匹配,(规则里的 {} 元字符)前面的一个字符,是自定义字符数,位数的原本字符,{m}匹配前一个字符m次,{m,n}匹配前一个字符m至n次,若省略n,则匹配m至无限次,{0,}匹配前一个字符0或多次,等同于*元字符,{+,}匹配前一个字符1次或无限次,等同于+元字符,{0,1}匹配前一个字符0次或1次,等同于?元字符 |
ab{1,2}c |
abc abbc |
|
[] |
需要字符串里完全符合,匹配规则,就匹配,(规则里的 [] 元字符)对应位置是[]里的任意一个字符就匹配,字符集。对应的位置可以是字符集中任意字符。字符集中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c]。[^abc]表示取反,即非abc。所有特殊字符在字符集中都失去其原有的特殊含义。用\\反斜杠转义恢复特殊字符的特殊含义。 |
a[bcd]e |
abe ace ade
|
|
() |
也就是分组匹配,()里面的为一个组也可以理解成一个整体,如果()后面跟的是特殊元字符如 (adc)* 那么*控制的前导字符就是()里的整体内容,不再是前导一个字符 |
(abc){2} |
abcabc a456c |
预定义字符集表,可以写在字符集[...]中
|
\\d |
\\d匹配任何十进制数,它相当于类[0-9],\\d+如果需要匹配一位或者多位数的数字时用 |
a\\bc |
a1c |
|
\\D |
\\D匹配任何非数字字符,它相当于类[^0-9] |
a\\Dc |
abc |
|
\\s |
\\s匹配任何空白字符,它相当于类[\\t\\n\\r\\f\\v] |
a\\sc |
a c |
|
\\S |
\\S匹配任何非空白字符,它相当于类[^\\t\\n\\r\\f\\v] |
a\\Sc |
abc |
|
\\w |
\\w匹配包括下划线在内任何字母数字字符,它相当于类[a-zA-Z0-9_] |
a\\wc |
abc |
|
\\W |
\\W匹配非任何字母数字字符包括下划线在内,它相当于类[^a-zA-Z0-9_] |
a\\Wc |
a c |
|
\\A |
仅匹配字符串开头,同^ |
\\Aabc |
abc |
|
\\Z |
仅匹配字符串结尾,同$ |
abc\\Z |
abc |
|
\\b |
b匹配一个单词边界,也就是指单词和空格间的位置 |
\\babc\\b |
空格abc空格 |
|
\\B |
[^\\b] |
a\\Bbc |
abc |
特殊分组用法表:只对正则函数返回对象的有用
|
(?P<name>) |
?P<>定义组里匹配内容的key(键),<>里面写key名称,值就是匹配到的内容,在用groupdict()方法打印字符串 |
(?P<id>abc){2} |
abcabc |
|
(?P=name) |
引用别名为<name>的分组匹配到字符串 |
(?P<id>\\d)abc(?P=id) |
1abc1 5abc5 |
|
\\<number> |
引用编号为<number>的分组匹配到字符串 |
(\\d)abc\\1 |
1abc1 5abc5 |
正则匹配模式表
|
标志 |
含义 |
|
re.S(DOTALL) |
使.匹配包括换行在内的所有字符 |
|
re.I(IGNORECASE) |
使匹配对大小写不敏感 |
|
re.L(LOCALE) |
做本地化识别(locale-aware)匹配,法语等 |
|
re.M(MULTILINE) |
多行匹配,影响^和$ |
|
re.X(VERBOSE) |
该标志通过给予更灵活的格式以便将正则表达式写得更易于理解 |
|
re.U |
根据Unicode字符集解析字符,这个标志影响\\w,\\W,\\b,\\B |
正则表达式重点
一、
r原生字符
将在python里有特殊意义的字符如\\b,转换成原生字符(就是去除它在python的特殊意义),不然会给正则表达式有冲突,为了避免这种冲突可以在规则前加原始字符r
二、
正则表达式,返回类型为表达式对象的
如:<_sre.SRE_Match object; span=(6, 7), match=‘a‘>
返回对象的,需要用正则方法取字符串,
方法有
group() # 获取匹配到的所有结果,不管有没有分组将匹配到的全部拿出来,有参取匹配到的第几个如2
groups() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分的结果
groupdict() # 获取模型中匹配到的分组结果,只拿出匹配到的字符串中分组部分定义了key的组结果
三、
匹配到的字符串里出现空字符
注意:正则匹配到空字符的情况,如果规则里只有一个组,而组后面是*就表示组里的内容可以是0个或者多过,这样组里就有了两个意思,一个意思是匹配组里的内容,二个意思是匹配组里0内容(即是空白)所以尽量避免用*否则会有可能匹配出空字符串
四、
()分组
注意:分组的意义,就是在匹配成功的字符串中,在提取()里,组里面的字符串
五、
?:在有分组的情况下findall()函数,不只拿分组里的字符串,拿所有匹配到的字符串,注意?:只用于不是返回正则对象的函数如findall()
素材来源:https://www.cnblogs.com/zjltt/p/6955965.html
以上是关于Python--re模块的主要内容,如果未能解决你的问题,请参考以下文章