吴裕雄 python 机器学习——K均值聚类KMeans模型
Posted tszr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴裕雄 python 机器学习——K均值聚类KMeans模型相关的知识,希望对你有一定的参考价值。
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics import adjusted_rand_score from sklearn.datasets.samples_generator import make_blobs def create_data(centers,num=100,std=0.7): X, labels_true = make_blobs(n_samples=num, centers=centers, cluster_std=std) return X,labels_true # 用于产生聚类的中心点 centers=[[1,1],[2,2],[1,2],[10,20]] # 产生用于聚类的数据集 X,labels_true=create_data(centers,1000,0.5) #K-MEANS聚类模型 def test_Kmeans(*data): X,labels_true=data clst=cluster.KMeans() clst.fit(X) predicted_labels=clst.predict(X) print("ARI:%s"% adjusted_rand_score(labels_true,predicted_labels)) print("Sum center distance %s"%clst.inertia_) # 用于产生聚类的中心点 centers=[[1,1],[2,2],[1,2],[10,20]] # 产生用于聚类的数据集 X,labels_true=create_data(centers,1000,0.5) # 调用 test_Kmeans 函数 test_Kmeans(X,labels_true)

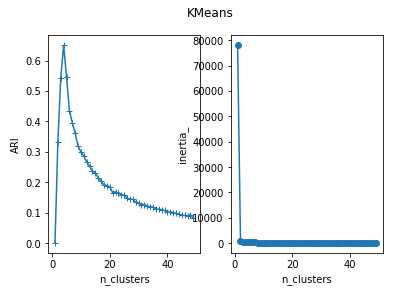
def test_Kmeans_nclusters(*data): ‘‘‘ 测试 KMeans 的聚类结果随 n_clusters 参数的影响 ‘‘‘ X,labels_true=data nums=range(1,50) ARIs=[] Distances=[] for num in nums: clst=cluster.KMeans(n_clusters=num) clst.fit(X) predicted_labels=clst.predict(X) ARIs.append(adjusted_rand_score(labels_true,predicted_labels)) Distances.append(clst.inertia_) ## 绘图 fig=plt.figure() ax=fig.add_subplot(1,2,1) ax.plot(nums,ARIs,marker="+") ax.set_xlabel("n_clusters") ax.set_ylabel("ARI") ax=fig.add_subplot(1,2,2) ax.plot(nums,Distances,marker=‘o‘) ax.set_xlabel("n_clusters") ax.set_ylabel("inertia_") fig.suptitle("KMeans") plt.show() test_Kmeans_nclusters(X,labels_true) # 调用 test_Kmeans_nclusters 函数
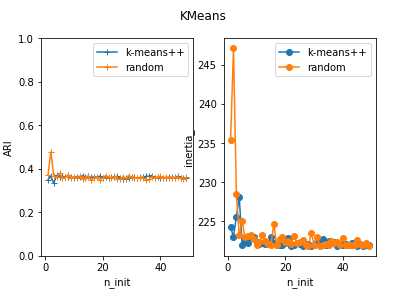
def test_Kmeans_n_init(*data): ‘‘‘ 测试 KMeans 的聚类结果随 n_init 和 init 参数的影响 ‘‘‘ X,labels_true=data nums=range(1,50) ## 绘图 fig=plt.figure() ARIs_k=[] Distances_k=[] ARIs_r=[] Distances_r=[] for num in nums: clst=cluster.KMeans(n_init=num,init=‘k-means++‘) clst.fit(X) predicted_labels=clst.predict(X) ARIs_k.append(adjusted_rand_score(labels_true,predicted_labels)) Distances_k.append(clst.inertia_) clst=cluster.KMeans(n_init=num,init=‘random‘) clst.fit(X) predicted_labels=clst.predict(X) ARIs_r.append(adjusted_rand_score(labels_true,predicted_labels)) Distances_r.append(clst.inertia_) ax=fig.add_subplot(1,2,1) ax.plot(nums,ARIs_k,marker="+",label="k-means++") ax.plot(nums,ARIs_r,marker="+",label="random") ax.set_xlabel("n_init") ax.set_ylabel("ARI") ax.set_ylim(0,1) ax.legend(loc=‘best‘) ax=fig.add_subplot(1,2,2) ax.plot(nums,Distances_k,marker=‘o‘,label="k-means++") ax.plot(nums,Distances_r,marker=‘o‘,label="random") ax.set_xlabel("n_init") ax.set_ylabel("inertia_") ax.legend(loc=‘best‘) fig.suptitle("KMeans") plt.show() test_Kmeans_n_init(X,labels_true) # 调用 test_Kmeans_n_init 函数
以上是关于吴裕雄 python 机器学习——K均值聚类KMeans模型的主要内容,如果未能解决你的问题,请参考以下文章