我们常常在武侠小说中看到一位内力精深的高手在学习新的招式的时候修炼速度异常惊人,我心目中最经典的片段就是倚天屠龙记中张无忌学习乾坤大挪移和太极拳的时候了,他能在极短的时间内领会常人数十年所不能掌握的东西,即使拍了很多版本,每次看到这,我都大呼过瘾,仍然看的津津有味~
数据结构和算法对于程序员来说就像是武侠世界中江湖人士的内功心法,其重要程度不言而喻,而开启数据结构与算法历练之路大门的钥匙则是复杂度的分析,这里的复杂度主要指的就是时间复杂度。
数据结构与算法需要掌握的知识很多,后来经过大牛们的归纳总结提炼出图中 10 种数据结构与 10 种常用的算法,只需要掌握下面这张图我们日常工作中就可以游刃有余了:
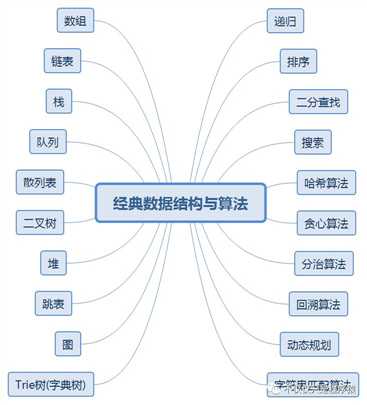
聪明的同学会发现其实图中知识点还是很多的,看着少是因为没有展开脑图而已 ,要掌握的知识多是好事,说明我们进步的空间很大,学习之路可能很远,没关系,慢慢来,我们来日方长~
铺垫了这么多,相信大家对数据结构与算法也有了一些认识,我目前也是一名小白,期望通过每次的分享能够在数据结构与算法的道路上走的更远一些。
下面我们开始入门第一课 :时间复杂度的分析
主要包括以下 4 点:
-
大O复杂度表示法
-
常用的时间复杂度表示
-
最好、最坏、平均、均摊时间复杂度
-
空间复杂度
在一些面试题当中经常会出现对某一算法进行时间复杂度分析,在给出的选项中会有类似 O(1),O(n),O(logn)....的写法,那么像这样的O()的写法是什么意思呢?
这就要提到时间复杂度分析常用的 大O复杂度表示法。
-
大O复杂度
大O复杂度实际上并不具体代表代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,也叫渐进时间复杂度,简称为时间复杂度。
看下面一个例子:
int sum(int n) { int sum = 0; int i = 1; int j = 1; for (; i <= n; ++i) { j = 1; for (; j <= n; ++j) { sum = sum + i * j; } }}
对上述代码而言,假设每一行代码的执行时间都是相同的记为 time(time 为常量),第2-4 行代码都是执行一次,各消耗时间为 time,第5、6行代码各执行 n 次,各消耗时间为 n * time,第7、8 行代码码各执行 n*n 次,各消耗时间为 n*n * time,所以上述代码的总消耗时间为:
2*n*n*time + 2*n*time+3*time = (2n²+2n+3)*time
用大 O 表示法则记为 O((2n²+2n+3)* time), 由于 time为常量,n为变量,即原式可以化简为 O(2n²+2n+3)。
当n很大时,甚至可以认为它趋近于无穷大时,根据极限的知识我们可以认为 O(2n²+2n+3) 中低阶、常量、系数三部分并不左右增长趋势,所以可以忽略,只用记录最高阶就可以了,即 O(2n²+2n+3) 可以写成 O(n²),这也就是上述代码的时间渐进复杂度,简称时间复杂度。
由上面的例子可以看出,其实在分析时间复杂度的时候,我们只要关心阶数最高或者说是循环次数最多的一段代码就可以了,因为我们一般会忽略低阶、常量、系数这三部分。
时间复杂度常用到的另外2个法则是:加法法则和乘法法则,都比较简单,这里就不在多说了。
-
常用的时间复杂度表示
O(1) , O(logn) , O(n) , O(nlogn) , O(n²),O(n³),O(2^n) ,O(n!),从左到右时间复杂度依次递增。
-
O(1)
O(1) 表示常量阶,并不是说只执行了一行代码,只要代码的执行时间不随着 n 的增大而增大就可以定为常量阶,哪怕有成千上万行代码。另外如果有循环次数是常量的循环也定义常量阶。
-
O(logn) 、O(nlogn)
这种对数阶时间复杂度也是比较常见的。
int i = 1;while(i <= n){ i = i * 2;}
从代码中可以看出 i 是成倍往上增长的,当 i 大于 n 时,循环就会结束,这其实是一道很简单的对数题:
2^x = n, 求 x 的值
我们都知道 x = log2 n (以 2 为底 n 的对数),那时间复杂度为什么不写成 O(log2 n )呢?
其实写成O(log2 n )也并没有错,如果我们把上述代码第4行 改成 i = i * 3,那是不是要写成 O(log3 n )了,显然不是,这样写虽然不错但是太麻烦了。
由我们仅存的高中数学知识可知,对数是可以相互转化的 :
log3n = log32 * log2n,log32为常数
那么,O(log3n) = O (log32 * log2n)= O(log2n),所以在对数时间复杂度中,就可以忽略对数的底,统一标识为 O(logn)。
而 nO(logn) 就显而易见了,根据乘法法则,在外层再套一层时间复杂度为 O (n)的循环,上述代码复杂度就是 nO(logn) 了。
归并排序、快速排序的时间复杂度都是O(nlogn)。
-
最好、最坏、平均、均摊时间复杂度
在了解常用的复杂度后,我们在深入一层,之前的代码都比较简单,不需要考虑相应的情况,下面我们看一个比较复杂的例子:
//数组中查找变量 target 的位置,有则返回下标,没有则返回1int find(int[] array, int n, int target) { int i = 0; int pos = -1; for (; i < n; ++i) { // n表示数组array的长度 if (array[i] == target) { pos = i; break; } } return pos;}
上面这段代码的时间复杂度是多少呢?
这个时候我们可能会有这样的疑问:
目标值在不在数组中,如果不在怎么办,如果在,那具体在哪个位置呢?
这里我们如果再用之前的方法分析,结果就会有偏差了,因为代码中的循环是有可能被中断的(当找到目标值后 break)此时引入最好时间复杂度、最坏时间复杂度、平均时间复杂度的概念了。
顾名思义,最好时间复杂度就是最理想的情况下,也就是目标值就是数组的第一个元素,此时对应的时间复杂度为 O(1)
最坏时间复杂度就是最差的情况下,也就是说目标值不在数组中(或目标值在数组的末尾),此时需要循环n次中才能知道目标值是否在数组中,对应时间复杂度为O(n)。
-
平均时间复杂度
最好和最坏时间复杂度其实都是极特殊的情况,为了更好的解释平均时间复杂度需要引入一个概念:平均情况时间复杂度,后面简称为平均时间复杂度。
所谓的平均情况与求平均值类似,上述的寻找目标值在数组中的位置,一共有n+1 中情况,包括在数组 0 ~ n-1 的任一下标上 和不在数组中的情况,把需要查找元素的个数累加起来,再除以 n+1 ,就可以得到遍历元素的平均值:
(1+2+3+4……+n+n)/(n+1) = n(n+3)/2(n+1)
将O (n(n+3)/2(n+1)) 根据上述规则转换后,可以得出平均时间复杂度为 O(n)。
-
加权平均时间复杂度
我们虽然得出了结果,但是仔细一想这个结果好像并不准确,原因在于 这 n+1 种情况出现的概率其实是不同的,而且目标值出现在数组中某一位置的概率也是不同的。
为了方便计算,我们假定目标值出现在数组中与不在数组中的概率是相等的,都为 1/2 ;目标值出现在数组中某一位置的概率也是相等的,都为 1/n,根据乘法法则,我们要找的目标值出现在数组中的概率应该为 (1/2) * (1/n), 1/(2n)。
所以前面的计算最大的问题是没有考虑概率问题,将概率添加上的算式为:
((1+2+3+4……+n)*(1/2n)+ n*(1/2) ) = (3n+1)/4
这个值就是概率论中的加权平均值,也叫作期望值,所以平均时间复杂度的全称应该叫加权平均时间复杂度或者期望时间复杂度。
实际上一般情况下我们并不区分最好、最差、平均时间复杂度这三种情况。使用最开始的一个复杂度就可以满足需求了。
如果出现一块代码在不同情况下,时间复杂度有重量级差距,才会使用这三种复杂度来区分。
-
均摊时间复杂度
均摊时间复杂度应用场景比较特殊,所以我们并不会经常用到。
均摊时间复杂度的主要思想是:
对一个数据结构进行一组连续操作中,大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高,而且这些操作之间存在前后连贯的时序关系,这个时候,我们就可以将这一组操作放在一块儿分析,看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上。而且,在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度 。
-
空间复杂度
在了解了时间复杂度后,最后再补充一下空间复杂度,其实空间复杂度很简单,它表示算法的存储空间与时间的增长关系。
一般重用的空间复杂度就是 O(1)、 O(n)、 O(n2 ),像O(logn)、 O(nlogn)这样的对数阶复杂度平时都用不到。
通过今天的分享,我们主要了解了数据结构与算法的重要性,与时间复杂度相关的一些知识,之后我们会继续学习数据结构与算法相关的知识,一起修炼内功,成为“江湖中的大侠”。