自然语言处理——实现机器翻译Seq2Seq完整经过
Posted lyjun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理——实现机器翻译Seq2Seq完整经过相关的知识,希望对你有一定的参考价值。
参考书
《TensorFlow:实战Google深度学习框架》(第2版)
我只能说这本书太烂了,看完这本书中关于自然语言处理的内容,代码全部敲了一遍,感觉学的很绝望,代码也运行不了。
具体原因,我也写过一篇博客diss过这本书。可是既然学了,就要好好学呀。为了搞懂自然语言处理,我毅然决然的学习了网上的各位小伙伴的博客。这里是我学习的简要过程,和代码,以及运行结果。大家共勉。
参考链接:
学习过程:
0. 数据准备
我用的数据就是参考链接里面的数据。即一个TED 演讲的中英字幕。
下载地址:
https://wit3.fbk.eu/mt.php?release=2015-01
1. 数据切片
简单来说,就是,我们得到的文件里面都是自然语言,“今天天气很好。”这样的句子。我们首先要做的就是要将这些句子里的每一个字以及标点符号,用空格隔开。所以第一步就是利用工具进行文本切片。(具体方法看链接,这里不赘述)
我们要进行处理的文件是下面两个。
![]() ?
?
但是在这两个文件里面除了演讲内容中英文之外,还有关于演讲主题的一些信息,如下图。
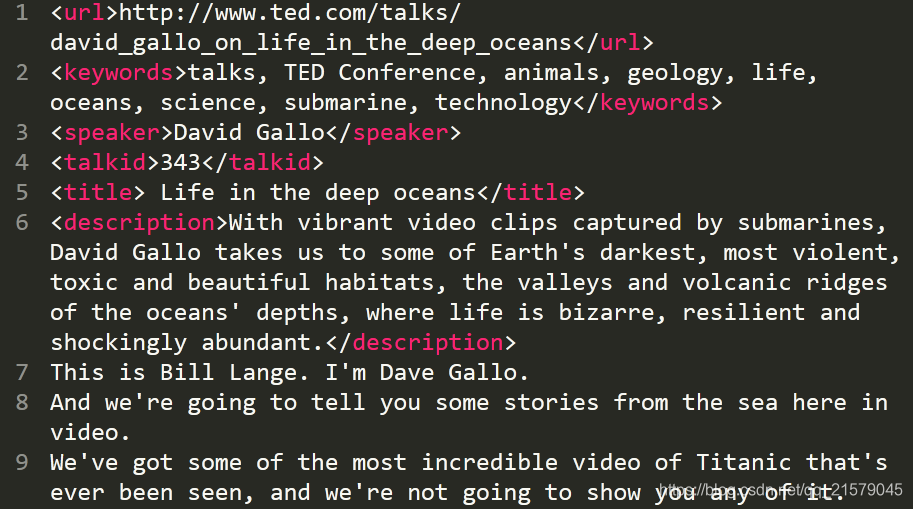
![]() ?
?
我用正则表达式的方法(现百度现用)去除了这些介绍部分的文字。英文和中文只需要改变名字和路径就行了,下面贴代码:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: [email protected]
@software: pycharm
@file: file_deal.py
@time: 2019/3/19 11:05
@desc: 对两个文件进行处理,将两个文件中的表头信息清除
"""
import re
def txt_clean(x):
pattern = re.compile(r‘<\w*>|</\w*>‘)
result = pattern.search(x)
return result
def main():
path = ‘D:/Python3Space/Seq2SeqLearning/en-zh/‘
# file = ‘train.tags.en-zh.en‘
# save_path = ‘D:/Python3Space/Seq2SeqLearning/train.en‘
file = ‘train.tags.en-zh.zh‘
save_path = ‘D:/Python3Space/Seq2SeqLearning/train.zh‘
path1 = path + file
output = open(save_path, ‘w‘, encoding=‘utf-8‘)
with open(path1, ‘r‘, encoding=‘utf-8‘) as f:
x = f.readlines()
for y in x:
result = txt_clean(y)
# print(result)
if result is None:
# print(y)
output.write(y)
output.close()
if __name__ == ‘__main__‘:
main()运行这个程序就能得到两个文件,分别是去除了介绍文字部分的英文和中文翻译:

![]() ?
?
内容如下(我不知道为什么截图之后图片变窄了,很难受):
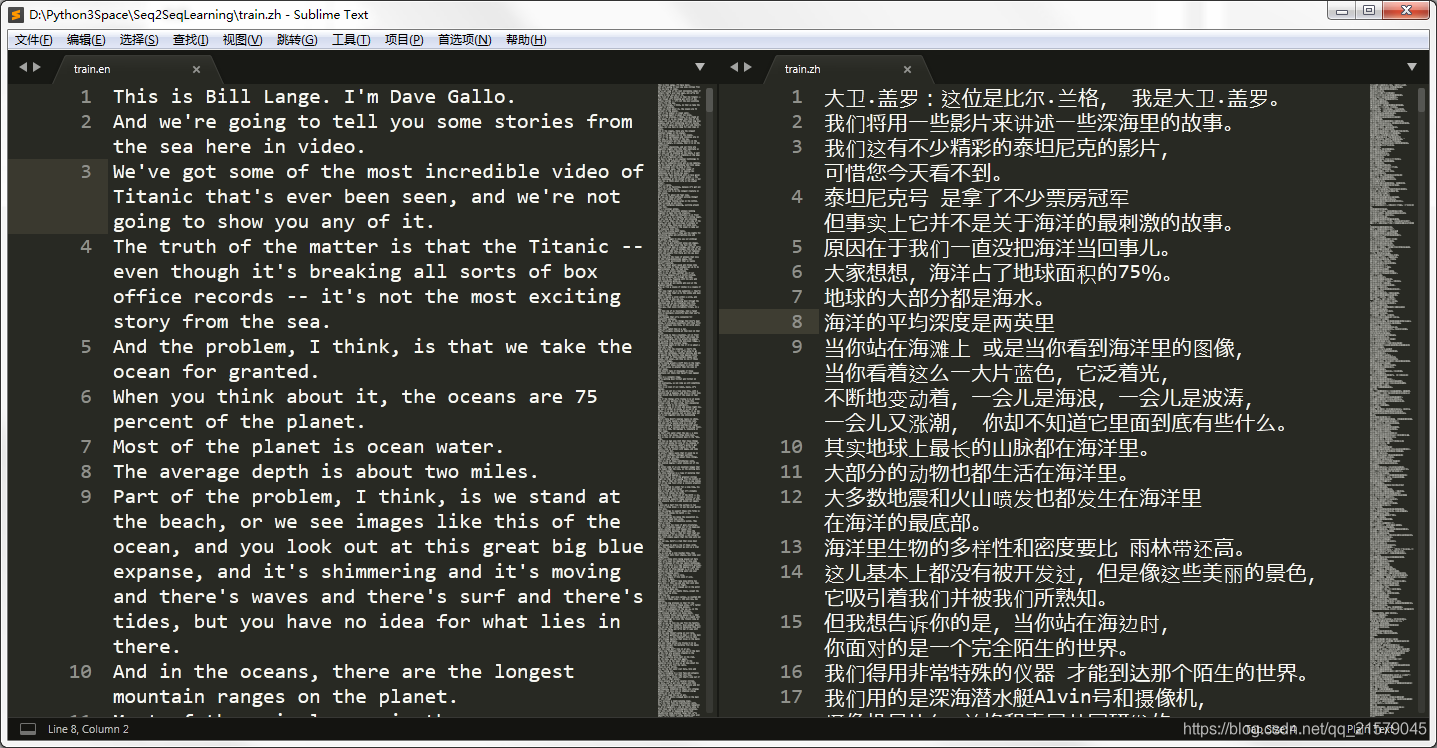
![]() ?
?
接下来我们需要有那种每个元素都是由空格所分开的(包括所有符号)。在这里,我选取的中文和英文的分词工具都是stanfordcorenlp,相关知识请参考这篇博客。
很绝望的是,我安装过程中Python还报错了:
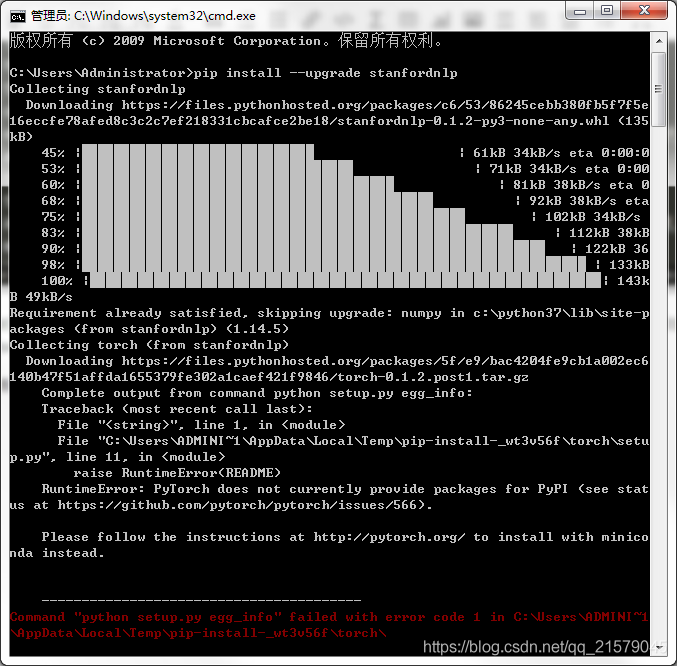
![]() ?
?
所以我借鉴知乎上面的回答解决了这个问题。
为什么要选用斯坦福的工具???
明明可以用nltk来对英文进行分词,用jieba对中文进行分词,可是当我搜到斯坦福这个自然语言处理工具的时候,我想了想,天啦,这个名字也太酷炫了吧,一看就很复杂啊,中英文用同一个库进行分词应该要比较好吧,我要搞定它。然后按照网上的教程,真的很容易的就安装了,然后很容易的就是实现对英文的分词了。可是!真的有毒吧!对中文进行分词的时候,我特么输出的是[‘‘, ‘‘, ‘‘, ‘‘]这种空值,无论怎么解决都没有办法,我真的要崩溃了。还好我看到了这篇文章。嗯。。。写的非常不错,竟然有我各种百度都没找到的解决办法,简直是太开心了好吗!可是!
里面写的 corenlp.py 到底在哪儿阿喂!
我哭了真的!
![]() ?
?
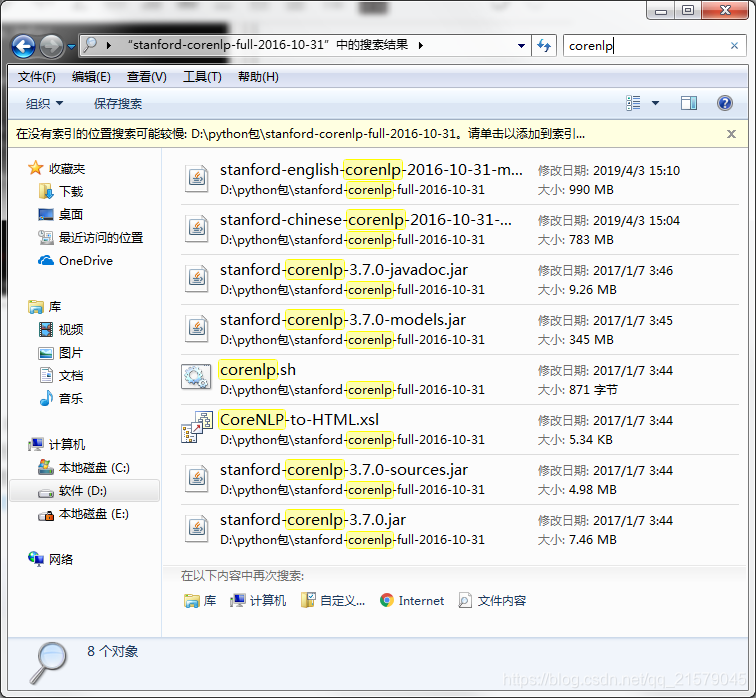
你们看,里面明明就只有一个叫corenlp.sh的文件好吗?打开之后里面也并不是知乎里面所说的内容啊!
在这个令人绝望的关头!我灵光一闪。。。.py!.py!莫不是在python库文件里面。。。然后我就立马去python3目录下找。

![]() ?
?
我是真的快乐,真的。。。特别是竟然出现了两个corenlp.py(虽然其中一个是nltk的啦,nltk是可以调用斯坦福的模块的,所以如果你百度的话,是可以查到如何用nlkt调用Stanfordcorenlp进行中文分词啊,语义解析啊等等的。我瞄了一眼一看就觉得不适合我哈哈!)
然后就顺利的根据上面知乎里的解决办法,替换了corenlp.py文件里面的某些关键字(具体内容点开上面的链接就知道啦)。
下面是我写的中英文分词的demo。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: [email protected]
@software: pycharm
@file: seperate_word.py
@time: 2019/4/1 14:34
@desc: 对处理好的中英文数据进行分词操作(demo)
"""
from stanfordcorenlp import StanfordCoreNLP
sentence1 = "大家想想,海洋占了地球面积的75%。"
sentence2 = "When you think about it, the oceans are 75 percent of the planet."
nlp = StanfordCoreNLP(‘D:/python包/stanford-corenlp-full-2016-10-31‘, lang=‘zh‘)
nlp2 = StanfordCoreNLP(‘D:/python包/stanford-corenlp-full-2016-10-31‘, lang=‘en‘)
print(nlp.word_tokenize(sentence1))
print(nlp2.word_tokenize(sentence2))运行之后得到:
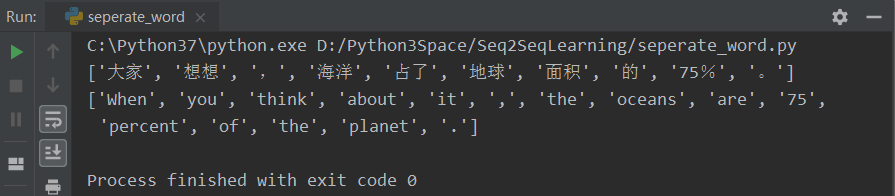
![]() ?
?
我现在是真的快乐!真的!真的是万事开头难,中间难,结尾难!
什么?你竟然不相信我会用jieba和nltk。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8
"""
@author: Li Tian
@contact: [email protected]
@software: pycharm
@file: seperate_word.py
@time: 2019/4/1 14:34
@desc: 对处理好的中英文数据进行分词操作(demo)
"""
from stanfordcorenlp import StanfordCoreNLP
import jieba
import nltk
# nltk.download("punkt")
sentence1 = "大家想想,海洋占了地球面积的75%。"
sentence2 = "When you think about it, the oceans are 75 percent of the planet."
# nlp = StanfordCoreNLP(‘D:/python包/stanford-corenlp-full-2016-10-31‘, lang=‘zh‘)
# nlp2 = StanfordCoreNLP(‘D:/python包/stanford-corenlp-full-2016-10-31‘, lang=‘en‘)
# print(nlp.word_tokenize(sentence1))
# print(nlp2.word_tokenize(sentence2))
seg_list = jieba.cut(sentence1, cut_all=False)
tokens = nltk.word_tokenize(sentence2)
print(list(seg_list))
print(tokens)运行之后得到:

![]() ?
?
要记得在使用nltk工具包的时候,要下载对应的语言包,不然就会报错。也可以预先下载好所有的语言包,可是速度也太慢了吧,我还是用啥下啥好了。真的是巨慢。。。(下载完所有的好像得3、4个G)
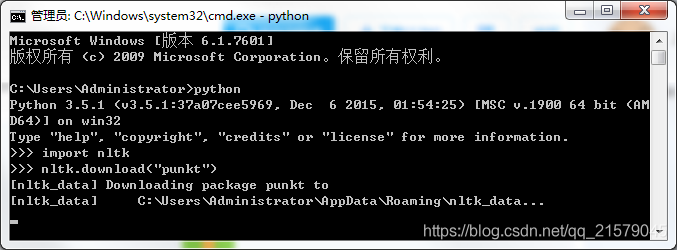
![]() ?
?
那我给出大佬的解决办法,大家自行下载呀。(这里是punkt库)
如果想要所有的库,可以去官网下载,离线解压就完事儿了。
未完待续。。。
以上是关于自然语言处理——实现机器翻译Seq2Seq完整经过的主要内容,如果未能解决你的问题,请参考以下文章