MapReduce编程模型
Posted pipiyan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce编程模型相关的知识,希望对你有一定的参考价值。
# 文本前期处理 strl_ist = str.replace(‘\\n‘, ‘‘).lower().split(‘ ‘) count_dict = {} # 如果字典里有该单词则加 1,否则添加入字典 for str in strl_ist: if str in count_dict.keys(): count_dict[str] = count_dict[str] + 1 else: count_dict[str] = 1
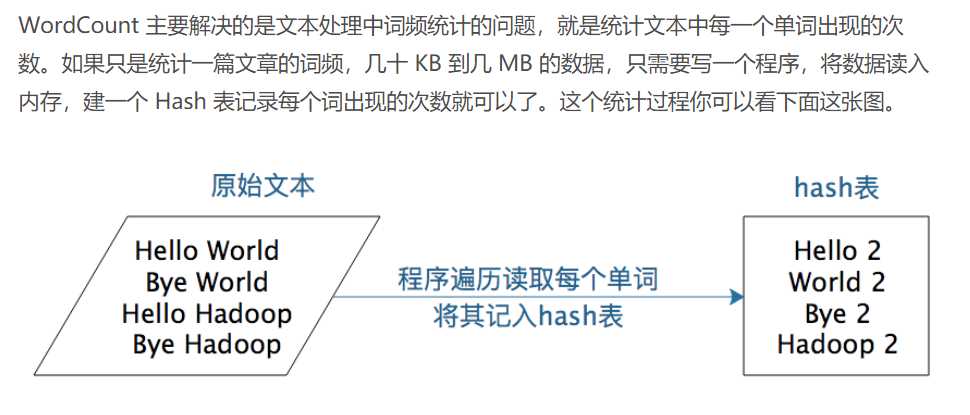
建一个hash表,将文本中的每个词都放在这个hash表里面,如果这个词第一次放入,就新建一个kry,Value对,key是这个词,Value是1;如果已经有这个词,那么给Value+1。
# Mapeduce 计算框架会将这些<word,1>收集起来,将相同的word放在一起,形成<word,<1,1,1,1,1,1…>>这样的<key,value集合>数据,然后将其输入给reduce函数
public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } }
reduce函数的计算过程:将这个集合中的1求和,再将单词(word)和这个和(sum)组成一个<key,Value>,也就是<word,sum>输出。
以上是关于MapReduce编程模型的主要内容,如果未能解决你的问题,请参考以下文章