SQL SERVER BCP的用法
Posted gered
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL SERVER BCP的用法相关的知识,希望对你有一定的参考价值。
转自:https://www.cnblogs.com/fishparadise/p/4809014.html
前言
SQL SERVER提供多种不同的数据导出导入的工具,也可以编写SQL脚本,使用存储过程,生成所需的数据文件,甚至可以生成包含SQL语句和数据的脚本文件。各有优缺点,以适用不同的需求。下面介绍大容量数据导出导入的利器——BCP实用工具。同时在后面也介绍BULK INSERT导入大容量数据,以及BCP结合BULK INSERT做数据接口的实践(在SQL2008R2上实践)。
--打开高级选项 EXEC SP_CONFIGURE ‘show advanced options‘, 1; RECONFIGURE; --启用执行CMD命令 EXEC SP_CONFIGURE ‘xp_cmdshell‘, 1; RECONFIGURE; --指定导入目的和导入源 EXEC master..xp_cmdshell ‘BCP IMP_DATA.dbo.t_goods in E:\\report.txt -c -T‘ --导出基于查询 EXEC master..xp_cmdshell ‘EXEC master..xp_cmdshell ‘bcp "select * from db_tank..sys_users_goods where userid = 25324" queryout d:\\goods.txt -c -Uroadadmin -[email protected]#r53e%$k8(+-3 -S127.0.0.1,2433 ‘ --导出基于结果 EXEC master..xp_cmdshell ‘EXEC master..xp_cmdshell ‘bcp db_tank.dbo.msg out d:\\goods.txt -c -Uroadadmin [email protected]#r53e%$k8(+-3 -S127.0.0.1,2433 ‘ EXEC SP_CONFIGURE ‘xp_cmdshell‘, 0; RECONFIGURE; EXEC SP_CONFIGURE ‘show advanced options‘, 0; RECONFIGURE;
1. BCP的用法
BCP 实用工具可以在 Microsoft SQL Server 实例和用户指定格式的数据文件间大容量复制数据。使用 BCP实用工具可以将大量新行导入 SQL Server 表,或将表数据导入数据文件。除非与 queryout 选项一起使用,否则使用该实用工具不需要了解 Transact-SQL 知识。BCP既可以在CMD提示符下运行,也可以在SSMS下执行。

figure-1
语法:

bcp {[[database_name.][schema].]{table_name | view_name} | "query"}
{in | out | queryout | format} data_file
[-mmax_errors] [-fformat_file] [-x] [-eerr_file]
[-Ffirst_row] [-Llast_row] [-bbatch_size]
[-ddatabase_name] [-n] [-c] [-N] [-w] [-V (70 | 80 | 90 )]
[-q] [-C { ACP | OEM | RAW | code_page } ] [-tfield_term]
[-rrow_term] [-iinput_file] [-ooutput_file] [-apacket_size]
[-S [server_name[\\instance_name]]] [-Ulogin_id] [-Ppassword]
[-T] [-v] [-R] [-k] [-E] [-h"hint [,...n]"]
简单的导出例子1:

figure-2
简单的导出例子2:

figure-3
在SSMS上同时也可以执行:
EXEC [master]..xp_cmdshell ‘BCP TestDB_2005.dbo.T1 out E:\\T1_02.txt -c -T‘ GO
code-1

figure-4
EXEC [master]..xp_cmdshell ‘BCP "SELECT * FROM TestDB_2005.dbo.T1" queryout E:\\T1_03.txt -c -T‘ GO
code-2

figure-5
从个人来讲,我更喜欢使用第二种跟queryout选项一起使用的写法,因为这样可以更加灵活控制要导出的数据。如果执行BCP命令遇到这样的错误提示:
| Msg 15281, Level 16, State 1, Procedure xp_cmdshell, Line 1 SQL Server blocked access to procedure ‘sys.xp_cmdshell‘ of component ‘xp_cmdshell‘ because this component is turned off as part of the security configuration for this server. A system administrator can enable the use of ‘xp_cmdshell‘ by using sp_configure. For more information about enabling ‘xp_cmdshell‘, see "Surface Area Configuration" in SQL Server Books Online. |
基于安全的考虑,系统默认没有开启xp_cmdshell选项。使用下面语句开启此选项。
EXEC sp_configure ‘show advanced options‘, 1 RECONFIGURE WITH OVERRIDE; GO EXEC sp_configure ‘xp_cmdshell‘, 1 RECONFIGURE WITH OVERRIDE; GO
code-3
使用完之后,可以把sp_cmdshell关闭。
EXEC sp_configure ‘show advanced options‘, 1 RECONFIGURE WITH OVERRIDE; GO EXEC sp_configure ‘xp_cmdshell‘, 0 RECONFIGURE WITH OVERRIDE; GO
code-4
BCP导入数据
修改figure-2中的out为in即可,把数据导入。

figure-6

figure-7
使用BULK INSERT导入数据
BULK INSERT dbo.T1 FROM ‘E:\\T1.txt‘
WITH (
FIELDTERMINATOR = ‘\\t‘,
ROWTERMINATOR = ‘\\n‘
)
code-5

figure-8
关于BULK INSERT更详细的说明,参考:https://msdn.microsoft.com/zh-cn/library/ms188365%28v=sql.105%29.aspx
相比BCP的导入,BULK INSERT提供更灵活的选择。
BCP几个常用的参数说明:
| database_name | 指定的表或视图所在数据库的名称。如果未指定,则使用用户的默认数据库。 |
| in | out| queryout | format |
|
| -c | 使用字符数据类型执行该操作。此选项不提示输入每个字段;它使用 char 作为存储类型,不带前缀;使用 \\t(制表符)作为字段分隔符,使用 \\r\\n(换行符)作为行终止符。 |
| -w | 使用 Unicode 字符执行大容量复制操作。此选项不提示输入每个字段;它使用 nchar 作为存储类型,不带前缀;使用 \\t(制表符)作为字段分隔符,使用 \\n(换行符)作为行终止符。 |
| -tfield_term | 指定字段终止符。默认值为 \\t(制表符)。使用此参数可以替代默认字段终止符。 |
| -rrow_term | 指定行终止符。默认值为 \\n(换行符)。使用此参数可替代默认行终止符。 |
| -Sserver_name[ \\instance_name] | 指定要连接的 SQL Server 实例。如果未指定服务器,则 bcp 实用工具将连接到本地计算机上的默认 SQL Server 实例。如果从网络或本地命名实例上的远程计算机中运行 bcp 命令,则必须使用此选项。若要连接到服务器上的 SQL Server 默认实例,请仅指定 server_name。若要连接到 SQL Server 的命名实例,请指定 server_name\\instance_name。 |
| -Ulogin_id | 指定用于连接到 SQL Server 的登录 ID。 |
| -Ppassword | 指定登录 ID 的密码。如果未使用此选项,bcp 命令将提示输入密码。如果在命令提示符的末尾使用此选项,但不提供密码,则 bcp 将使用默认密码 (NULL)。 |
| -T | 指定 bcp 实用工具通过使用集成安全性的可信连接连接到 SQL Server。不需要网络用户的安全凭据、login_id 和 password。如果未指定 –T,则需要指定 –U 和 –P 才能成功登录。 |
更详细的参数,请参考:https://msdn.microsoft.com/zh-cn/library/ms162802%28v=sql.105%29.aspx
2. 实践
2.1 导出数据
介绍完BCP的导出导入,以及BULK INSERT的导入,下面进行一些实际的操作。为了接近实际环境,创建一张10个字段的表,包含有几种常用的数据类型,构造2000万的数据,包含中文和英文。为了更快插入测试数据,先不创建索引。在执行下面代码之前,请留意下数据库的日志恢复模式是否设置为大容量模式或简单模式,以及磁盘空间是否足够(我的实践中,数据生成后数据文件和日志文件大概需要40G的空间)。
USE AdventureWorks2008R2
GO
IF OBJECT_ID(N‘T1‘) IS NOT NULL
BEGIN
DROP TABLE T1
END
GO
CREATE TABLE T1 (
id_ INT,
col_1 NVARCHAR(50),
col_2 NVARCHAR(40),
col_3 NVARCHAR(40),
col_4 NVARCHAR(40),
col_5 INT,
col_6 FLOAT,
col_7 DECIMAL(18,8),
col_8 BIT,
input_date DATETIME DEFAULT(GETDATE())
)
GO
WITH CTE1 AS (
SELECT a.[object_id] FROM master.sys.all_objects AS a,master.sys.all_objects AS b,sys.databases AS c
WHERE c.database_id <= 5
)
,CTE2 AS (
SELECT ROW_NUMBER() OVER (ORDER BY [object_id]) as row_no FROM CTE1
)
INSERT INTO T1 (id_,col_1,col_2,col_3,col_4,col_5,col_6,col_7,col_8)
SELECT row_no,REPLICATE(N‘博客园 ‘,10),NEWID(),NEWID(),NEWID(),CAST(row_no * RAND() * 10 AS INT),row_no * RAND(),row_no * RAND(),CAST(row_no * RAND() AS INT) % 2
FROM CTE2 WHERE row_no <= 20000000
GO
code-6
过程要花上几分钟的时间才能完成,请耐心等待一下。关于数据的构造,可以参考我的另一篇博文:http://www.cnblogs.com/fishparadise/p/4781035.html
使用上面介绍的用法导出数据:
EXEC [master]..xp_cmdshell ‘BCP AdventureWorks2008R2.dbo.T1 out E:\\T1_04.txt -w -T -S KEN\\SQLSERVER08R2‘ GO
code-7
这里使用-w参数。BCP可以在CMD下导出数据,测试导出2000万条记录,我的笔记本使用了近8分钟左右的时间。BCP同时也可以在SSMS中执行,使用了6分多钟时间,比CMD下速度要快些,生成的文件大小一致,每个文件近5GB。

figure-9

figure-10
而对于复杂的大容量导入情况,通常都会需要格式化文件。在以下情况下,必须使用格式化文件:
-
具有不同架构的多个表使用同一数据文件作为数据源。
-
数据文件中的字段数不同于目标表中的列数;例如:
-
目标表中至少包含一个定义了默认值或允许为 NULL 的列。
-
用户不具有对目标表的一个或多个列的 SELECT/INSERT 权限。
-
具有不同架构的两个或多个表使用同一个数据文件。
-
-
数据文件和表的列顺序不同。
-
数据文件列的终止字符或前缀长度不同。
这里不使用格式化文件进行导出导入的演示了。详细介绍与使用,请参考联机丛书。
2.2 导入数据
使用BULK INSERT把数据导入到目标表数据。为提高性能,可临时删除索引,导完之后再重建索引等。请注意要预留足够的磁盘空间。这里大概花了15分钟导完。

figure-11
3. 扩展
3.1 数据导出导入自动化与数据接口
由于工作关系,有时要开发一些客户的数据接口,每天自动导入比较大量的数据。限制于应用程序等因素影响,所以考虑直接使用SQL SERVER的BULK INSERT每天自动去读取相关目录的中间文件。尽管目录是动态的,但由于中间文件是固定格式的,通过编写动态SQL,最后封装成存储过程,放到JOB中,配置运行的计划,即可完成自动化的工作。下面简单演示下过程:
3.1.1 编写导入脚本
CREATE PROCEDURE sp_import_data
AS
BEGIN
DECLARE @path NVARCHAR(500)
DECLARE @sql NVARCHAR(MAX)
/*S_PARAMETERS表是可以在应用程序上配置路径的*/
SELECT @path = value_ + CONVERT(NVARCHAR, getdate(), 23) + ‘.txt‘ FROM S_PARAMETERS WHERE [type] = ‘Import‘
/*T4是一张临时的中间表。先把数据从文件中读入到中间表,最后通过脚本把T4中间表的数据插入到实际的业务表中*/
SET @sql=N‘BULK INSERT T4 FROM ‘‘‘+ @path + ‘‘‘
WITH (
FIELDTERMINATOR = ‘‘*‘‘,
ROWTERMINATOR = ‘‘\\n‘‘
)‘
EXEC (@sql)
END
GO
code-8
3.1.2 配置JOB
首先要配置好的是SQL SERVER有权限读取相关目录和文件的权限。在Sql Server Configuration Manager --> SQL Server Services 选择相应的实例,右键选择属性,在Log On页签,使用有足够权限启动SQL SERVER和有权限读取相关目录的用户,比如读取网络盘。
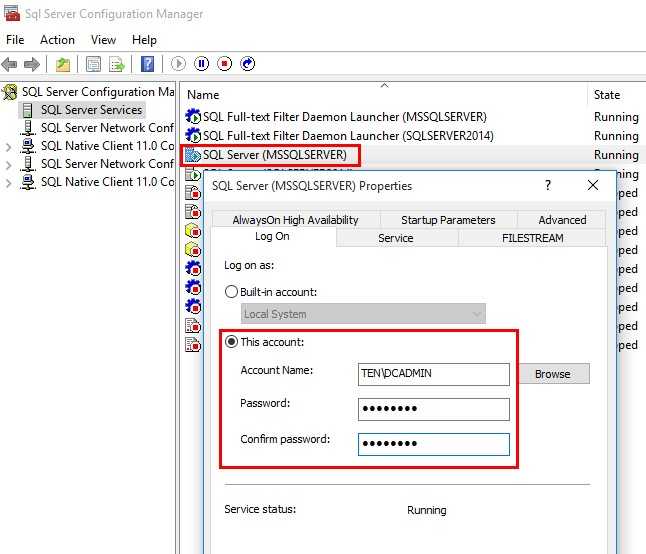
figure-12
在SQL Server Agent新建一个作业

figure-13
在General页,选择Owner,这里选择sa。

figure-14
在Steps页,在Command里执行写好的存储过程。

figure-15
在Schedules页,配置执行的时间和频率等。完成。

figure-16
3.2 高版本数据库降级到低版本
一般来说,从低版本备份的数据库可以直接在高版本的数据库中恢复的,比如SQL2000的备份可以在SQL2005或SQL2008中恢复,除非是跨度太大的之外。比如SQL2000的备份就不能直接在SQL2012中恢复,只能恢复到SQL2008,再从SQL2008备份出来,最后到SQL2012上恢复。
而高版本的备份一般不能在低版本中恢复,如SQL2008的备份不能在SQL2005或SQL2000中恢复。而实际中,却又会遇到这种需求。最好是通过高版本SSMS直接连接两个不同版本的数据库,通过数据库间的数据导出导入或写脚本,把高版本的数据导到低版本的数据库中。这是比较快速安全的方法。但是如果两个版本的数据库不能相连,只能是把数据导出来,再导入。对于数据量不大来说,使用SSMS的导出导入功能,或是生成包含数据的脚本即可(下图)。对于大数据来说,却是一个灾难,如前面有2000万数据的大表,生成数据的脚本也有几个G大,直接使用SSMS执行是不可能的了。只能是使用SQLCMD实用工具,在后台执行SQL脚本,或者借助BCP、BULK INSERT等这种大容量数据导出导入的工具。

figure-17
4. 总结
使用BCP并结合BULK INSERT可实现大容量数据的快速导出导入,并可以实现其自动化工作。对于少量数据来说,操作也不算很复杂。这是除了SSMS上的图形化工具之外,又一个非常实用的工具。
以上是关于SQL SERVER BCP的用法的主要内容,如果未能解决你的问题,请参考以下文章
在SQL Server中,如何快速删除大批量数据和进行大批量数据导入?