Hadoop 完全分布式部署(三节点)
Posted luomeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop 完全分布式部署(三节点)相关的知识,希望对你有一定的参考价值。
用来测试,我在VMware下用Centos7搭起一个三节点的Hadoop完全分布式集群。其中NameNode和DataNode在同一台机器上,如果有条件建议大家把NameNode单独放在一台机器上,因为NameNode是集群的核心承载压力是很大的。hadoop版本:Hadoop-2.7.4;
|
hadoopo1 |
hadoopo2 |
hadoopo3 |
| Namenode | ResourceManage | SecondaryNamenode |
| Datanode | Datanode | Datanode |
| NodeManage | NodeManage | NodeManage |
一、准备环境
- 准备三台节点(机器),要求:yum源挂载成功、网络设置可用(ip在同一网段,连接Xshell)、已安装Oracle8.0及以上版本JDK;
-
hadoop-2.7.4.tar.gz,hadoop2.x安装包;
二、部署集群
- 创建Hadoop用户(三节点);
su - root
useradd hadoop
passwd hadoop - 在Hadoop用户家目录下创建安装目录(三节点);
mkdir /home/hadoop/install (安装目录)
mkdir /home/hadoop/soft (存放安装包) - 解压hadoop安装包,通过Xshell等工具将安装包上传到~/soft目录中(hadoop01节点);
tar –zxvf /home/hadoop/soft/hadoop-2.7.4.tar.gz -C /home/hadoop/install/
三、修改配置文件(hadoop01节点)
- cd到hadoop配置文件目录;
su - hadoop
cd /home/hadoop/install/hadoop-2.7.4/etc/hadoop - core-site.xml设置
vim core-site.xml
//在<configuration> 之间添加如下配置
<property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> <!-- hadoop01:主机名,9000:端口 --> </property> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/tmp</value> </property> - hadoop-env.sh,JDK配置;
vim hadoop-env.sh
//修改等号后面的值
//使用echo $JAVA_HOME 查看JDK安装路径
export JAVA_HOME=/usr/local/jdk - HDFS相关配置;
vim hdfs-site.xml
//在<configuration> 之间添加如下配置
<!-- secondaryNamenode地址 --> <property> <name>dfs.secondary.http.address</name> <value>hadoop03:50090</value> </property> <!-- 数据块冗余份数--> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- edtis文件存放地址--> <property> <name>dfs.namenode.edits.dir</name> <value>/data/hadoop/namenode/name</value> </property> <!-- datanode数据目录存放地址--> <property> <name>dfs.datanode.data.dir</name> <value>/data/hadoop/datanode/data</value> </property> <!-- checkpoint数据目录存放地址--> <property> <name>dfs.namenode.checkpoint.dir</name> <value>/data/hadoop/namenode/namesecondary</value> </property> - mapred-env.sh
vim mapred-env.sh
//修改export JAVA_HOME=/usr/local/jdk - MR相关配置
vim mapred-env.sh
//修改export JAVA_HOME=/usr/local/jdk
cp mapred-site.xml.template ./mapred-site.xml
vim mapred-site.xml
//在<configuration> 之间添加如下配置
<!-- 集群调度框架为YARN--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 注意:"hadoop01"替换为NameNode所在主机名--> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop01:19888</value> </property>
- YARN相关配置;
vim yarn-site.xml
//在<configuration> 之间添加如下配置
<!--resourcemanager主机名 --> <!-- 注意:"hadoop02"替换为resourcemanager所在主机名--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop02</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>hadoop02:8088</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>3000</value> </property> <!--nodemanager最多分配cpu虚拟核心个数 --> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> <!--nodemanager最多内存大小 --> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>3000</value> </property> <!--作业调度过程中 作业单个内存最少内存大小 --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>500</value> </property> <!--作业调度过程中 作业单个最多的cpu分配 --> <property> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>4</value> </property>
- 启动脚本配置;
在调用脚本的过程中,start-dfs.sh和start-yarn.sh会使用该脚本进行datanode和ndoemanager的启动。
vim slaves
//将三台主机名写入后保存
hadoop01 hadoop02 hadoop03
四、创建数据目录
- 创建Datanode节点数据目录(三节点);
su – root
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/datanode/data
chown hadoop:hadoop -R /data/hadoop - 创建Namenode节点数据目录(hadoop01节点);
su – root
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/namenode/name
mkdir -p /data/hadoop/datanode/data
mkdir -p /data/hadoop/namenode/namesecondary
chown hadoop:hadoop -R /data/hadoop
五、配置hadoop环境变量(三节点)
su – root
vim /etc/profile
//在文件末尾添加如下设置
//最后更新环境变量(root/hadoop)
source /etc/profile
HADOOP_HOME=/home/hadoop/install/hadoop-2.7.4 PATH=$PATH:$HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
六、配置SSH互信(三节点)
- 将三台节点ip添加到Hosts文件中;su – root
vim /etc/hosts
//加入三台节点的ip映射
192.168.1.10 hadoop01 192.168.1.11 hadoop02 192.168.1.12 hadoop03
- 在hadoop用户下,生成密钥对(三节点);
su – hadoop
ssh-keygen

- 查看密钥,并将公钥发给三个个节点;
cd /home/hadoop/.ssh/
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]

七、分发hadoop安装目录(hadoop01)
scp –r ~/install [email protected]:~/install
scp –r ~/install [email protected]:~/install
八、格式化并且启动HDFS(重点)
- 在hadoop用户下,namenode节点上;
su – hadoop
hdfs namenode -format
C$AWBT5A5")

九、启动集群
- 启动HDFS(hadoop01上);
su – hadoop
start-dfs.sh - 启动YARN(hadoop02上);
su – hadoop
start-yarn.sh - 查看进程(jps);

H$576_F4")
NW")
- 管理页面
进入HDFS管理页面:http://192.168.1.10:50070,查看DataNode节点信息;
查看yarn框架管理:http://192.168.1.11:8088,查看NodeManager节点;


十、关闭集群
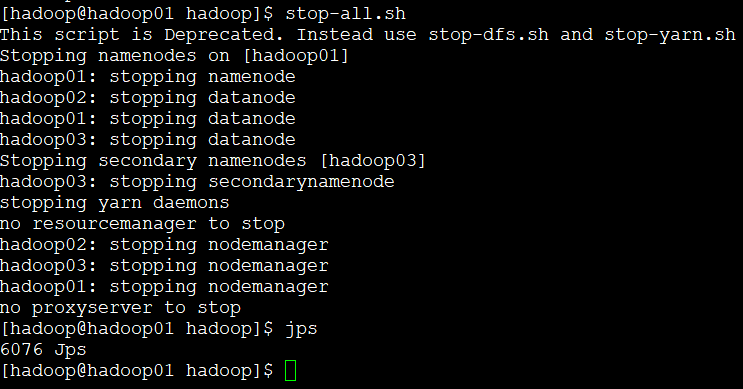{kind=link}
以上是关于Hadoop 完全分布式部署(三节点)的主要内容,如果未能解决你的问题,请参考以下文章