Dubbo系列dubbo的核心技术--RPC调用
Posted aoshicangqiong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Dubbo系列dubbo的核心技术--RPC调用相关的知识,希望对你有一定的参考价值。
dubbo的核心技术--RPC调用:分为俩部分RPC协议Protocol和方法调用Invoke;
一、RPC协议Protocol(Remote Procedure Call)远程过程调用协议
1、我们平时使用最多的http协议其实也属于RPC协议,下图分别是普通的传输层TCP和应用层http与dubbo优化后的TCP和dubbo协议进行对比。
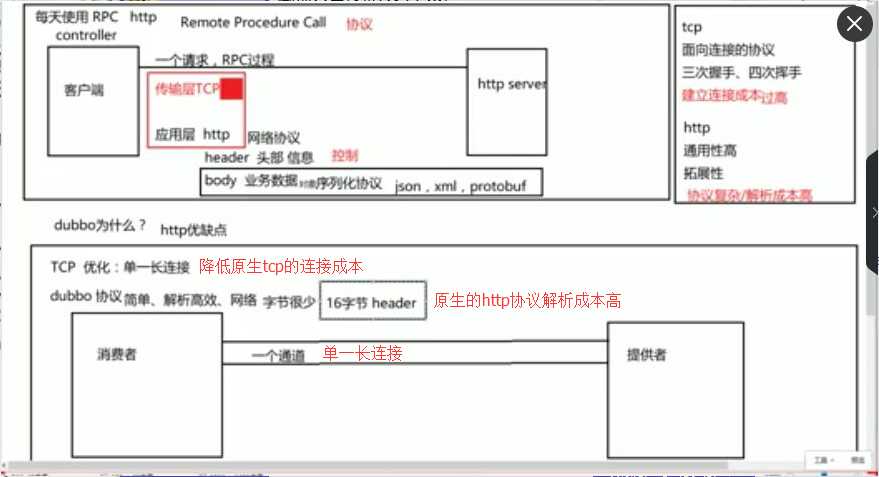
总结:
原生的传输层协议(TCP)需要网络三次握手和四次挥手,客户端与服务端的建立链接成本过高,dubbo对TCP进行优化,实现单一长连接,降低网络链接成本;
原生的应用层协议(http)通用性高、拓展性强,同时协议复杂解析成本高,dubbo消费者调用服务者时只需要传输很少字节,并且结构简单,便与解析;
2、dubbo远程同步调用原理分析:
Dubbo默认协议采用单一长连接和NIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。Dubbo缺省协议不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低。
dubbo缺省协议,使用基于mina1.1.7+hessian3.2.1的tbremoting交互。
- 连接个数:单连接
- 连接方式:长连接
- 传输协议:TCP
- 传输方式:NIO异步传输
- 序列化:Hessian二进制序列化
- 适用范围:传入传出参数数据包较小(建议小于100K),消费者比提供者个数多,单一消费者无法压满提供者,尽量不要用dubbo协议传输大文件或超大字符串
- 适用场景:常规远程服务方法调用
为什么采用异步单一长连接:因为服务的现状大都是服务提供者少,而服务的消费者多,通过单一长连接,保证单一消费者不会压死提供者,长连接减少连接握手验证,并使用异步IO,复用线程池,降低网络链接成本。
为什么要消费者比提供者个数多:因为dubbo协议采用单一长连接,假设网络为千兆网卡(1024Mbit=128MByte),根据测试经验数据每条连接最多只能压满7MByte(不同的网络环境可能不一样,仅供参考),理论上1个服务提供者需要20个服务消费者才能压满网卡。
为什么不能传大包:如果每次请求的数据包大小为500KByte,则单个服务提供者的TPS(每秒处理事务数)最大为:128Mbyte/500KByte=262. 单个消费者调用单个服务提供者的TPS(每秒处理事务数)最大为: 7MByte/500KByte = 14。可看出网络将成为瓶颈。
通常,一个典型的同步远程调用应该是这样的:

1、客户端线程调用远程接口,向服务端发送请求,同时当前线程应该处于“暂停“状态,即线程不能向后执行了,必需要拿到服务端给自己的结果后才能向后执行;
2、服务端接到客户端请求后,处理请求,将结果给客户端;
3、客户端收到结果,然后当前线程继续往后执行;
Dubbo底层使用Socket发送消息的形式进行数据传递,结合了mina框架,使用iosession.write()方法,这个方法调用后对于整个远程调用(从发出请求到接收到结果)来说是一个异步的,即对于当前线程来说,将请求发送出来,线程就可以往后执行了,至于服务端的结果,是服务端处理完成后,再以消息的形式发送给客户端的。----红字部分我没有搞明白!!
- 当前线程怎么让它“暂停”,等结果回来后,再向后执行?
- 正如前面所说,Socket通信是一个全双工的方式,如果有多个线程同时进行远程方法调用,这时建立在client server之间的socket连接上会有很多双方发送的消息传递,前后顺序也可能是乱七八糟的,server处理完结果后,将结果消息发送给client,client收到很多消息,怎么知道哪个消息结果是原先哪个线程调用的?
- 当前线程怎么让它“暂停”,等结果回来后,再向后执行?
- 正如前面所说,Socket通信是一个全双工的方式,如果有多个线程同时进行远程方法调用,这时建立在client server之间的socket连接上会有很多双方发送的消息传递,前后顺序也可能是乱七八糟的,server处理完结果后,将结果消息发送给client,client收到很多消息,怎么知道哪个消息结果是原先哪个线程调用的?
以上是关于Dubbo系列dubbo的核心技术--RPC调用的主要内容,如果未能解决你的问题,请参考以下文章