解题报告 smoj 2019初二创新班(2019.3.17)
Posted longlongzhu123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解题报告 smoj 2019初二创新班(2019.3.17)相关的知识,希望对你有一定的参考价值。
目录
解题报告 smoj 2019初二创新班(2019.3.17)
时间:2019.3.21
T1:找玩具
题目描述
在游戏开始之前,游戏大师在房间的某些地方隐藏了N个玩具。玩具编号为1到N。您的任务是尽可能多地找到这些玩具。
你没有任何辅助信息就能找到第i个玩具的概率是p[i]%。您每找到一个玩具后,有可能可以得到一些辅助信息,这些辅助信息是告诉您其他某些玩具所在的位置。如果您已经知道玩具的位置,您一定会找到它。
给出二维数组clue[1..N][1..N],其中clue[i][j]=‘Y’表示若找到第i个玩具则会告诉您第j个玩具的具体位置;clue[i][j]=‘N’表示第i个玩具没有第j个玩具位置的辅助信息;
你的任务是计算您在游戏中找到的玩具数量的期望值。
题意转化
这里有一步很重要的转化:将“找到玩具数量的期望值”转化为“每个玩具被找到的概率总和”。
这样,我们单独计算每个玩具被找到的概率即可。
另外,还要用到另一个常见套路:求补集
分析
我们把玩具A->根据玩具A找到的玩具当成图上的边。
首先,根据题目我们可以知道:找到一个玩具后,它能走到的所有玩具都能被找到。
那么不妨将原图建出来吧!图中的环(强连通分量)中的玩具可以互相找到,因此我们可以缩点,将图变成一个DAG。拓扑排序后进行DP即可。
DP过程:\\(玩具A能被找到的概率 = 1 - \\displaystyle \\prod _ {B能找到A} (玩具B不能被找到的概率)\\)
直接按照拓扑顺序求就行了
代码
代码有点丑。时间复杂度:\\(O(n +m)\\),这里\\(n\\)、\\(m\\)分别是点数、边数。
np(not-prob)2就是答案
#include <bits/stdc++.h>
using namespace std;
const int kMaxN = 50 + 10;
int T;
int n;
double p[kMaxN];
char str[kMaxN][kMaxN];
int node_cnt[kMaxN];
struct Graph {
vector<int> lis[kMaxN];
bool used[kMaxN][kMaxN];
void clear() {
for (int i = 1; i < kMaxN; i++) lis[i].clear();
memset(used, false, sizeof(used));
}
void Add(int u, int v) {
lis[u].push_back(v);
used[u][v] = true;
}
};
Graph G;
int dfn_cnt, color_cnt;
int dfn[kMaxN], low[kMaxN], color[kMaxN];
bool in[kMaxN];
stack<int> S;
double np[kMaxN];
double np2[kMaxN];
void Tarjan(int u) {
dfn[u] = low[u] = ++dfn_cnt;
S.push(u);
in[u] = true;
for (int i = 0; i < G.lis[u].size(); i++) {
int v = G.lis[u][i];
if (!dfn[v]) {
Tarjan(v);
low[u] = min(low[u], low[v]);
} else if (in[v]) {
low[u] = min(low[u], dfn[v]);
}
}
if (low[u] == dfn[u]) {
color_cnt++;
np[color_cnt] = 1.0;
node_cnt[color_cnt] = 0;
while (S.top() != u) {
int v = S.top();
S.pop();
color[v] = color_cnt;
in[v] = false;
np[color_cnt] *= 1.0 - p[v];
node_cnt[color_cnt]++;
}
S.pop();
color[u] = color_cnt;
in[u] = false;
np[color_cnt] *= 1.0 - p[u];
node_cnt[color_cnt]++;
np2[color_cnt] = np[color_cnt];
}
}
Graph scc;
int cnt_in[kMaxN];
vector<int> vec;
void TopoSort() {
vec.clear();
int end = 0;
for (int i = 1; i <= color_cnt; i++) {
if (!cnt_in[i]) vec.push_back(i);
}
while (end != vec.size()) {
int u = vec[end++];
for (int i = 0; i < scc.lis[u].size(); i++) {
int v = scc.lis[u][i];
cnt_in[v]--;
if (!cnt_in[v]) vec.push_back(v);
}
}
}
int main() {
freopen("2823.in", "r", stdin);
freopen("2823.out", "w", stdout);
scanf("%d", &T);
while (T--) {
G.clear();
scc.clear();
memset(dfn, 0, sizeof(dfn));
memset(low, 0, sizeof(low));
memset(in, false, sizeof(in));
memset(color, 0, sizeof(color));
dfn_cnt = color_cnt = 0;
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
int p1;
scanf("%d", &p1);
p[i] = 1.0 * p1 / 100;
}
for (int i = 1; i <= n; i++) {
scanf("%s", str[i] + 1);
for (int j = 1; j <= n; j++) {
if (str[i][j] == 'Y') {
G.Add(i, j);
}
}
}
for (int i = 1; i <= n; i++)
if (!dfn[i])
Tarjan(i);
memset(cnt_in, 0, sizeof(cnt_in));
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
if (str[i][j] == 'Y' && color[i] != color[j]
&& !scc.used[color[i]][color[j]]) {
scc.Add(color[i], color[j]);
cnt_in[color[j]]++;
}
TopoSort();
for (int vec_i = 0; vec_i < vec.size(); vec_i++) {
int u = vec[vec_i];
for (int i = 0; i < scc.lis[u].size(); i++) {
int v = scc.lis[u][i];
np2[v] *= np[u];
}
}
double ans = 0;
for (int i = 1; i <= color_cnt; i++) {
ans += (1.0 - np2[i]) * node_cnt[i];
}
printf("%lf\\n", ans);
}
return 0;
}优化(代码复杂度)
好吧其实并不用这么复杂...
直接DFS判联通就好了嘛OvO
#include <bits/stdc++.h>
using namespace std;
const int kMaxN = 50 + 10;
int T;
int n;
double np[kMaxN]; // not-prob
char str[kMaxN][kMaxN];
bool vis[kMaxN];
bool CanReach(int u, int v) {
if (vis[u]) {
return false;
} else if (u == v) {
return true;
} else {
vis[u] = true;
for (int i = 1; i <= n; i++) {
if (str[u][i] == 'Y') {
if (CanReach(i, v)) return true;
}
}
return false;
}
}
int main() {
freopen("2823.in", "r", stdin);
freopen("2823.out", "w", stdout);
scanf("%d", &T);
while (T--) {
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
int a;
scanf("%d", &a);
np[i] = 1.0 - 1.0 * a / 100.0;
}
for (int i = 1; i <= n; i++) {
scanf("%s", str[i] + 1);
}
double ans = 0;
for (int i = 1; i <= n; i++) {
double prob = 1;
for (int j = 1; j <= n; j++) {
memset(vis, false, sizeof(vis));
if (CanReach(j, i)) prob *= np[j];
}
ans += 1 - prob;
}
printf("%lf\\n", ans);
}
return 0;
}T2:闯关游戏
题目描述
艾伦正在闯关,总共有\\(N\\)个关卡,编号从\\(1\\)到\\(N\\)。
每当艾伦尝试闯第\\(i\\)关时,他要么顺利通过,要么“挂掉”。他完成该关卡的概率总是\\(\\dfrac{prob[i]}{1000}\\)(他总是尽力完成每个关卡)。在关卡\\(i\\)的末尾有一个宝箱,其中包含价值 \\(value[i]\\)单位的金币。当艾伦完成关卡时,他从拿起该关卡的金币。
艾伦从第1级关卡开始,艾伦没有金币。对于每个有效的i,每当Allen完成关卡i时,他就会继续进行关卡i + 1,一旦完成第N个关卡,游戏就会结束。
每当艾伦“挂掉”时,下面4件事情会按顺序发生:
- 除了艾伦携带的金币,其他金币都被从游戏中移除。
- 艾伦目前所携带的所有金币都“坠落”,“坠落”的地点就是艾伦“挂掉”的那个关卡的开头处。一旦艾伦以后再次达到这个关卡,即使在尝试闯该关卡之前,他也能够再次“捡起”上次“坠落”到这个地方的金币。(请注意,如果他在到达这个关卡之前再次“挂掉”,这些金币将永远消失。)
- 所有箱子都添加了新的金币,各个箱子金币的量就是它们最初所含的量(相当于初始化各个箱子的金币量)。
- 艾伦回到了第1级的开头,且他没有携带金币。艾伦有无限条“生命”,“挂掉”后可以重新开始游戏。
通过上面的规则可以发现,艾伦“挂掉”后,最多只有一堆金币不在宝箱中,这一堆金币的位置就是艾伦最近“挂掉”所在的关卡的开头处。
分析
可以发现,每次艾伦挂掉时只有两种情况:
- 他在挂掉之前拿到了上次坠落的金币!
- 他
太非了没有拿到上次坠落的金币。上次的金币消失。
由此可见,坠落的金币数量要么不断叠加,位置不断往后;要么直接消失。
假设他不停闯关,最终通关后统计数据如下:
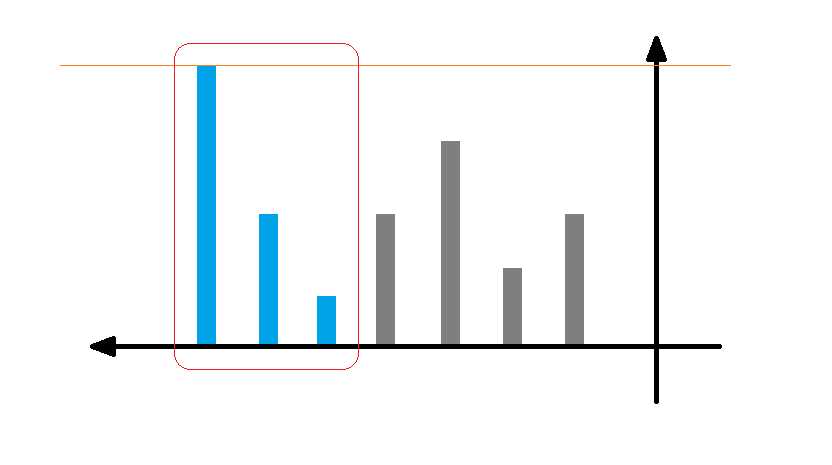
其中横轴表示闯关的次数,纵轴表示该次闯关到达的关数。用橙色标出了终点的位置,最后一次闯关直接通关。
可以发现,只有红框框出的蓝色部分(高度单调不下降),才能对答案产生贡献,且可以把蓝色部分的“面积”看做是答案。
考虑DP。设\\(F(i)\\)表示最后一次闯关通过第\\(i\\)关后,手上金币数量的期望。
也就是当最后一条蓝柱的高度为\\(i\\)时,前面所有蓝柱的期望总“面积”
设\\(G(i)\\)为一次性通过前\\(i\\)关,并在第\\(i+1\\)关前挂掉的概率。即\\(G(i) = (1 - prob _ {i + 1}) \\times \\displaystyle \\prod _ {1 \\le j \\le i} ^ i prob_j\\)
转移很显然:\\(F(i) = \\displaystyle \\sum _ {1 \\le j \\le i} value_j + \\displaystyle \\sum _ {1 \\le j \\le i} F(j)G(j)\\)
等式两边都有\\(F(i)\\)一项,移一下项即可。
\\[
F(i) = \\dfrac
{ \\displaystyle \\sum _ {1 \\le j \\le i} value_j + \\displaystyle \\sum _ {1 \\le j \\le i - 1} F(j)G(j) }
{1 - G(i)}
\\]
代码
也可以把\\(F(j)G(j)\\)理解为在第\\(j\\)关后期望掉落的金币数量。代码很短。
#include <bits/stdc++.h>
using namespace std;
const int kMaxN = 1000 + 10;
int T;
int n;
double prob[kMaxN], g[kMaxN], f[kMaxN];
long long value[kMaxN];
int main() {
freopen("2827.in", "r", stdin);
freopen("2827.out", "w", stdout);
scanf("%d", &T);
while (T--) {
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
int p;
scanf("%d", &p);
prob[i] = 1.0 * p / 1000;
}
prob[n + 1] = 1.0;
for (int i = 1; i <= n; i++) {
scanf("%lld", &value[i]);
}
double pi = 1;
for (int i = 1; i <= n; i++) {
pi *= prob[i];
g[i] = pi * (1 - prob[i + 1]);
}
for (int i = 1; i <= n; i++) {
f[i] = 0;
for (int j = 1; j <= i - 1; j++) {
f[i] += f[j] * g[j] + value[j];
}
f[i] += value[i];
f[i] /= 1 - g[i];
}
printf("%lf\\n", f[n]);
}
return 0;
}T3:子数组有主元素
题目描述
给出一个长为\\(N\\)的数组(\\(N \\le 10^5, a[i] \\le 50\\)),求该数组中含有主元素的子序列个数。数据保证随机。
分析
由于数字的范围很小,所以可以枚举主元素,并统计答案。(主元素对答案的贡献是不会有重复的)
设当前枚举的数字是\\(m\\),可以将数组中等于\\(m\\)的位置看成\\(+1\\),其他看成\\(-1\\),并做一遍前缀和。
m = 0的情况:
原数组:[0, 0, 1, 2, 0, 0, 0, 1, 2, 1, 0, 1]
+ + - - + + + - - - + -
前缀和:[1, 2, 1, 0, 1, 2, 3, 2, 1, 0, 1, 0]可以发现前缀和其实就是前缀m的个数与非m的个数的差值。而区间有主元素的条件就是这段区间的部分和>0。
枚举区间开头\\(i\\),对答案的贡献就是后缀\\(sum[j] >sum[i - 1]\\)的\\(j\\)的个数。
可以用主席树或树状数组解决。
代码(\\(O(nm\\log n)\\))
代码中为了方便,前缀和变成了后缀和,枚举开头变成枚举结尾。其他部分一样。
#include <bits/stdc++.h>
using namespace std;
const int kMaxN = 100000 + 10;
#define lowbit(X) ((X) & -(X))
struct FenwickTree {
int n;
int tree[kMaxN << 1]; // 有偏差值,所以要开两倍
void Clear() {
for (int i = 1; i <= n * 2; i++) tree[i] = 0;
}
void Update(int pos) {
pos += n;
for (; pos <= n * 2; pos += lowbit(pos)) tree[pos]++;
}
int Query(int pos) {
pos += n;
int ans = 0;
for (; pos; pos -= lowbit(pos)) ans += tree[pos];
return ans;
}
};
int n, seed, m;
FenwickTree T;
int a[kMaxN];
int suf_sum[kMaxN];
int GenRand() {
int ans = (seed >> 16) % m;
seed = (1ll * seed * 1103515245ll + 12345) % (1ll << 31);
return ans;
}
int main() {
freopen("2828.in", "r", stdin);
freopen("2828.out", "w", stdout);
scanf("%d %d %d", &n, &seed, &m);
T.n = n + 1;
for (int i = 1; i <= n; i++) {
a[i] = GenRand();
}
long long ans = 0;
// 枚举主元素
for (int num = 0; num < m; num++) {
T.Clear();
for (int i = n; i >= 1; i--) {
suf_sum[i] = suf_sum[i + 1] + (a[i] == num ? +1 : -1);
}
for (int i = 1; i <= n; i++) {
T.Update(suf_sum[i]);
ans += i - T.Query(suf_sum[i + 1]);
}
}
printf("%lld\\n", ans);
return 0;
}优化
思考树状数组的本质:
维护一个数据结构,支持:
- 插入一个数
- 查询一个数的排名
每次插入/查询的值相差不超过2
我们发现每次插入/查询的值相差不超过2,也就是说可以利用这个性质,减小数据结构的复杂度。
将树状数组改成类似莫队的指针跳跃,直接将复杂度降到\\(O(nm)\\)
代码(\\(O(nm)\\))
#include <bits/stdc++.h>
using namespace std;
const int kMaxN = 100000 + 10;
struct DataStructure {
int n;
int cnt[kMaxN << 1];
int cur, rank;
void Clear() {
for (int i = 1; i <= n * 2; i++) cnt[i] = 0;
cur = rank = 0;
}
void Insert(int val) {
val += n;
while (cur < val) rank += cnt[++cur];
while (cur > val) rank -= cnt[cur--];
cnt[cur]++;
rank++;
}
int Query(int val) {
val += n;
while (cur < val) rank += cnt[++cur];
while (cur > val) rank -= cnt[cur--];
return rank;
}
};
int n, seed, m;
DataStructure T;
int a[kMaxN];
int suf_sum[kMaxN];
int GenRand() {
int ans = (seed >> 16) % m;
seed = (1ll * seed * 1103515245ll + 12345) % (1ll << 31);
return ans;
}
int main() {
freopen("2828.in", "r", stdin);
freopen("2828.out", "w", stdout);
scanf("%d %d %d", &n, &seed, &m);
T.n = n + 1;
for (int i = 1; i <= n; i++) {
a[i] = GenRand();
}
long long ans = 0;
// 枚举主元素
for (int num = 0; num < m; num++) {
T.Clear();
for (int i = n; i >= 1; i--) {
suf_sum[i] = suf_sum[i + 1] + (a[i] == num ? +1 : -1);
}
for (int i = 1; i <= n; i++) {
T.Insert(suf_sum[i]);
ans += i - T.Query(suf_sum[i + 1]);
}
}
printf("%lld\\n", ans);
return 0;
}以上是关于解题报告 smoj 2019初二创新班(2019.3.17)的主要内容,如果未能解决你的问题,请参考以下文章