Shell文本处理 - 分割合并与过滤
Posted 峰入云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Shell文本处理 - 分割合并与过滤相关的知识,希望对你有一定的参考价值。
sort分类操作
示例文件
Boys in Company C:HK:192:2192
Alien:HK:119:1982
The Hill:KL:63:2972
Aliens:HK:532:4892
Star Wars:HK:301:4102
A Few Good Men:KL:445:5851
Toy Story:HK:239:3972
sort的命令格式为:sort -cmu -o output_file [other options] +pos1 +pos2 input_files
对整行排序
可以使用-o选项保存,也可以使用重定向保存
sort video.txt > results.out
判断是否排序
sort -c video.txt
如果已经分类,则什么也不返回,状态码为1。
如果为-C,不分类也什么都不输出,状态码为1。
按:分割,对第2域之后的内容排序
sort -t : -k 2 video.txt
使用-t指定分隔符,使用-k指定排序列的开始。
注意:k指定的域其实是从这里开始的之后内容,详细设置见之后的介绍。
反序
sort -r video.txt
默认是使用升序,使用-r可以使用降序的。
去重
sort -u video.txt
按数值排序
sort -n -k 3 -t : video.txt
默认使用字符串ASCII进行比较,使用-n开始使用数值比较。
多键排序
都是降序:sort -n -k 2 -k 3 facebook.txt
有升有降(r表示逆序):sort -n -k 3r -k 2 facebook.txt
非数值排序(n表示数值):sort -k 3nr -k 2n facebook.txt
k的语法
[ FStart [ .CStart ] ] [ Modifier ] [ , [ FEnd [ .CEnd ] ][ Modifier ] ]
其中modifier就是n r类似的选项
End如果不设定,默认为行尾部
FStart是域,CStart是域之后从第几个字符开始。
如对第一个域的第二个字母排序,相同就按照第三个域降序
sort -t ‘ ‘ -k 1.2,1.2 -k 3,3nr facebook.txt
Modirier的其他选项
- b表示忽略本域的签到空白符号。
- d表示对本域按照字典顺序排序(即,只考虑空白和字母)。
- f表示对本域忽略大小写进行排序。
- i表示忽略“不可打印字符”,只针对可打印字符进行排序。(有些ASCII就是不可打印字符,比如\\a是报警,\\b是退格,\\n是换行,\\r是回车等等)
其他选项:
-f 忽略大小写,将小写转换成大写进行比较
-M 对月份进行排序
head和tail
使用head和tail可以输出标准输入的第一行或者最后一行
sort -t : -r -k 4 video.txt | head -1
多文件合并分类
sort -t : -k 1 video2.txt video1.txt
uniq
从输入文件或者标准输入中筛选相邻的匹配行并写入到输出文件或标准输出。去除连续相同的行
用法:uniq [选项]... [文件]
不附加任何选项时匹配行将在首次出现处被合并。
长选项必须使用的参数对于短选项时也是必需使用的。
- -c, --count //在每行前加上表示相应行目出现次数的前缀编号
- -d, --repeated //只输出重复的行
- -D, --all-repeated //只输出重复的行,不过有几行输出几行
- -f, --skip-fields=N //-f 忽略的段数,-f 1 忽略第一段
- -i, --ignore-case //不区分大小写
- -s, --skip-chars=N //根-f有点像,不过-s是忽略,后面多少个字符 -s 5就忽略后面5个字符
- -u, --unique //去除重复的后,全部显示出来,根mysql的distinct功能上有点像
- -z, --zero-terminated end lines with 0 byte, not newline
- -w, --check-chars=N //对每行第N 个字符以后的内容不作对照
join
与SQL的join相似。
示例文件:
| cn.txt | en.txt |
|
1 yi |
1 one |
直接使用
join cn.txt en.txt
通过第一列链接两个文件,输出共有的部分,第一个文件的列放到前边。
左匹配/右匹配
join -a 1 cn.txt en.txt #以第一个文件为主,第二个没有的留空
join -a 2 cn.txt en.txt #以第二个文件为主,第一个没有的留空
忽略大小写:-i
输出指定列
join -o 1.1 -o 1.2 -o 2.1 -o 2.2 -a 1 cn.txt en.txt

填充没有匹配的项目 -e
join -o 1.1 -o 1.2 -o 2.1 -o 2.2 -a 1 -e "eee" cn.txt en.txt

指定输入输出分割符:-t
cut
剪切列或者域,可以用于粘贴到其他文件中。
cut [-bn] [file] 或 cut [-c] [file] 或 cut [-df] [file]
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
-c :以字符为单位进行分割。
-d :自定义分隔符,默认为制表符。
-f :与-d一起使用,指定显示哪个区域。
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的范围之内,该字符将被写出;否则,该字符将被排除。
三个定位方法:
第一,字节(bytes),用选项-b
第二,字符(characters),用选项-c
第三,域(fields),用选项-f
使用字节
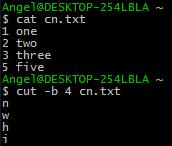
数量的指定
- 从头到指定的位置:-4
- 从指定位置到最后:4-
- 指定范围:3-5
- 指定特定列:1,3-5,7
paste
paste -d -s -file1 file2
-d 指定文件1和文件2之间分割符
-s 文件换成行合并
split
将大文件分割成小文件。
split [-n] file [name]
-n: 指定截断的每一文件的长度,不指定缺省为1000行
file: 要截断的文件
name: 截断后产生的文件的文件名的开头字母,不指定,缺省为x,即截断后产生的文件的文件名为xaa,xab....直到xzz
tr
将整个输入一起对待进行处理。
tr -c -d -s ["string1_to_translate_from"] ["string2_to_translate_to"] < input-file
-c 用字符串1中字符集的补集替换此字符集,要求字符集为ASCII。
-d 删除字符串1中所有输入字符。
-s 删除所有重复出现字符序列,只保留第一个;即将重复出现字符串压缩为一个字符串。
input-file是转换文件名。虽然可以使用其他格式输入,但这种格式最常用。
字符范围
指定字符串1或字符串2的内容时,只能使用单字符或字符串范围或列表。
[a-z] a-z内的字符组成的字符串。
[A-Z] A-Z内的字符组成的字符串。
[0-9] 数字串。
\\octal 一个三位的八进制数,对应有效的ASCII字符。
[O*n] 表示字符O重复出现指定次数n。因此[O*2]匹配OO的字符串。
tr中特定控制字符的不同表达方式
速记符含义八进制方式
\\a Ctrl-G 铃声\\007
\\b Ctrl-H 退格符\\010
\\f Ctrl-L 走行换页\\014
\\n Ctrl-J 新行\\012
\\r Ctrl-M 回车\\015
\\t Ctrl-I tab键\\011
\\v Ctrl-X \\030
去重
echo \'ahhjjjkkk;;;;\' | tr -s "[a-z]"

替换成大写
echo \'ahhjjjkkk;;;;\' | tr "[a-z]" "[A-Z]"

替换非指定字符
echo \'ahhjjjkkk;;;;\' | tr -c \'[a-y]\' \'#\'

以上是关于Shell文本处理 - 分割合并与过滤的主要内容,如果未能解决你的问题,请参考以下文章