Hadoop系列-HDFS基础
Posted zeem0ny
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop系列-HDFS基础相关的知识,希望对你有一定的参考价值。
-
HDFS(Hadoop Distributed File System)是Hadoop的一个基础的分布式文件系统,这个分布式的概念主要体现在两个地方:
-
数据分块存储在多台主机
-
数据块采取冗余存储的方式提高数据的可用性
针对于以上的分布式存储概念,HDFS采用了master/slave的主从结构来构建整个存储系统。之所以可以通过分散的机器组成一个整体式的系统,这其中机器之间的相互通讯必不可少。对于一个程序在不同机器上的通讯,主要是通过远程系统调用RPC(remote procedure call)实现,不同的语言有不同的实现方式,而HDFS是运行于JVM基础上的,那么这里的通讯就是指不同机器的JVM进程之间的通讯。当然,底层的网络通讯主要是socket协议,在实际的工业场景中使用对socket进一步封装的netty实现。接下来,进一步针对数据块、namenode、datanode等进行说明。
-
-
数据块
每个计算机的磁盘都有一个默认的数据块(block)大小,这是进行数据读写的最小单位,文件系统通过管理磁盘上的数据块来管理文件。HDFS的block默认大小为128MB,但是于一般单一的磁盘文件系统不同的是,HDFS中小于一个块大小的文件不会占用整个block空间。例如:一个大小为1MB的文件存储在HDFS中时,在默认数据块是128MB的情况下还是只占用1MB,而不是128MB。决定数据传输速度的因素主要是磁盘驱动器的传输速率和文件寻址效率,如果数据块设置的足够大,那么文件寻址的效率就会变高,但也不是无限大,具体block的大小还需要根据具体的业务逻辑进行考虑。对文件进行块抽象的一个明显优点就是文件的大小不受限于任何一台单独的主机的磁盘容量限制,也就使得HDFS更适合数据量比较大的大数据场景。
-
namenode
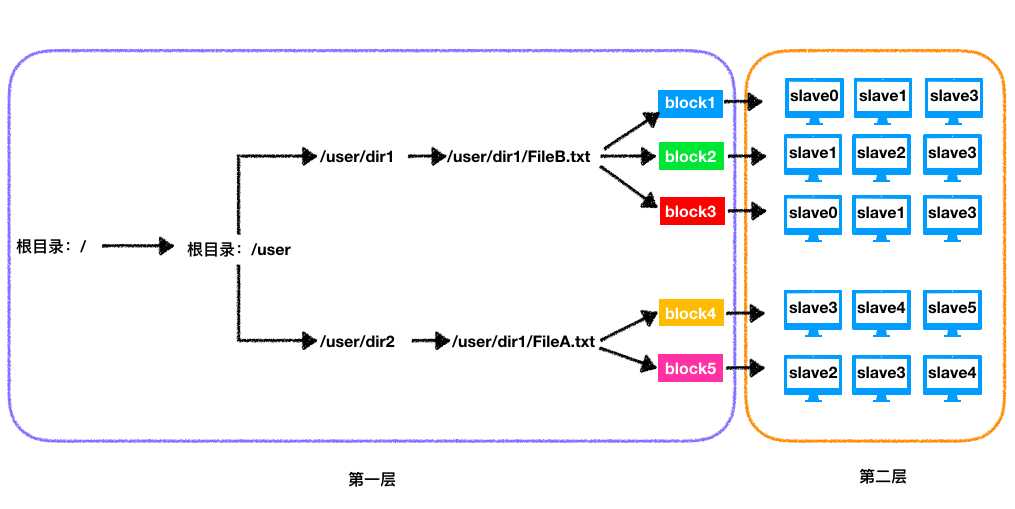
整个HDFS集群有管理节点(namenode)和工作节点(datanode)。namenode主要维持两层关系:
-
第一层:整个集群的目录树结构以及文件的数据块列表;
-
第二层:数据块与各个datanode的映射关系,也包括datanode的一些主机名、磁盘大小等数据。

-
命名空间镜像文件(FSImage):某一时刻内存元数据的真实组织情况
-
编辑日志文件(EditsLog):该时刻后所有元数据的改动信息
-
-
-
secondarynamenode
secondarynamenode主要是不定时的观察EditsLog、FSImage的情况,超过一定的阈值情况下对EditsLog和FSImage进行合并,形成新的FSImage文件。这样可以尽量减少namenode本身的负载。
-
datanode
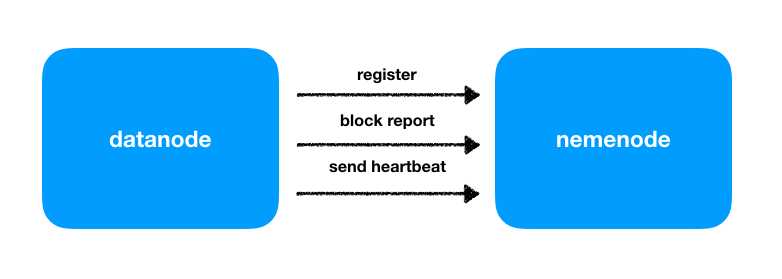
datanode是主要的数据存储节点,这其中涉及了datanode与namenode的通讯情况。

-
register:将datanode所在主机的信息(如主机名、内存、硬盘)告诉namenode,nemenode通过check相应的信息允许其称为集群中的一员;
-
block report:传输block信息给namenode,便于namenode可以维护数据块和数据节点之间的映射关系;
-
send heartbeat:
-
通过心跳机制保持与namenode的联系更新存储容量等信息
-
执行namenode通过heartbeat传输来的指令
-
-
federation
上文提到,namenode为了尽可能的使客户端的访问效率变高,会将所有的文件系统和数据块的引用信息保存在内存中,如果集群存储的文件量足够多,namenode内存的大小将限制集群的整个性能和可扩展能力。为此,在hadoop2.x中引入了federation机制,通过添加namenode实现扩展。
federation环境下,每隔namenode维护一个命名空间卷(namespace volume)由命名空间的元数据和数据块池组成,命名空间之间相互独立,互不通信。在这种情况下datanode被用作通用的数据存储设备,每个datanode要向集群中所有的namenode注册,且周期性的向所有namenode发送心跳和报告,并执行来自所有namenode的命令。但是,每个namenode只管理各自的block信息,如果一个namenode挂掉,虽然不会影响到其他的namenode,但是这个namenode管理的数据就不可访问,还是会存在SPOF(single point of failure,即单点故障问题)。
以上主要是个人对HDFS的一些基本概念的初步理解,如有错误还请各位大大们指正。
以上是关于Hadoop系列-HDFS基础的主要内容,如果未能解决你的问题,请参考以下文章