Web深度面试题(原理)
Posted lujihang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Web深度面试题(原理)相关的知识,希望对你有一定的参考价值。
XML和JSON的区别,
其实XML和JSON很相似
(1).XML定义
扩展标记语言 (Extensible Markup Language, XML) ,用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 XML使用DTD(document type definition)文档类型定义来组织数据;格式统一,跨平台和语言,早已成为业界公认的标准。
XML是标准通用标记语言 (SGML) 的子集,非常适合 Web 传输。XML 提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。
(2).JSON定义
JSON(javascript Object Notation)一种轻量级的数据交换格式,具有良好的可读和便于快速编写的特性。可在不同平台之间进行数据交换。JSON采用兼容性很高的、完全独立于语言文本格式,同时也具备类似于C语言的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等)体系的行为。这些特性使JSON成为理想的数据交换语言。
JSON基于JavaScript Programming Language , Standard ECMA-262 3rd Edition - December 1999 的一个子集。
XML的优缺点:格式统一,符合标准,容易远程交互,数据共享比较方便。
缺点: 文件庞大,格式复杂,占带宽;
服务器端和客户端都需要花大量代码来解析XML,导致两方代码异常复杂不易维护;
客户端不同浏览器之间解析XML的方式不一致,需要重复编写很多代码;
服务端和客户端解析XML话费较多的资源和时间;
JSON的优缺点:数据格式比较简单,易于读写,格式都是压缩的,占用带宽小等等,
缺点: 没有XML那么通用性。
JS函数作用域
1、变量作用域
在JavaScript中全局变量的作用域比较简单,它的作用域是全局的,在代码的任何地方都是有定义的。然而函数的参数和局部变量只在函数体内有定义。另外局部变量的优先级要高于同名的全局变量,也就是说当局部变量与全局变量重名时,局部变量会覆盖全局变量。
var num = 1; //声明一个全局变量
function func() {
var num = 2; //声明一个局部变量
return num;
}
console.log(func()); // 2
2、函数作用域
在JavaScript中变量的作用域,并非和C、Java等编程语言似得,在变量声明的代码段之外是不可见的,我们通常称为块级作用域,然而在JavaScript中使用的是函数作用域 变量在声明它们的函数体以及这个函数体嵌套的任意函数体都是有定义的。
function func() {
console.log(num); //输出:undefined,而非报错,因为变量num在整个函数体内都是有定义的
var num = 1; //声明num 在整个函数体func内都有定义
console.log(num); //输出:1
}
func();
 3、作用域链
3、作用域链当一个函数创建后,它实际上保存一个作用域链,并且作用域链会被创建此函数的作用域中可访问的数据对象填充。
function func() {
var num = 1;
alert(num);
}
func()
在函数func创建时,它的作用域链中会填入一个全局对象,该全局对象包含了所有全局变量
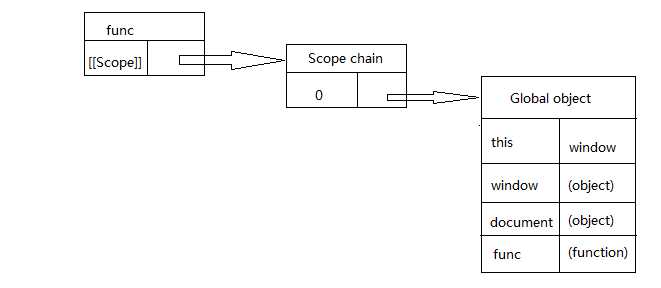
函数add的作用域将会在执行时用到。例如执行如下代码:
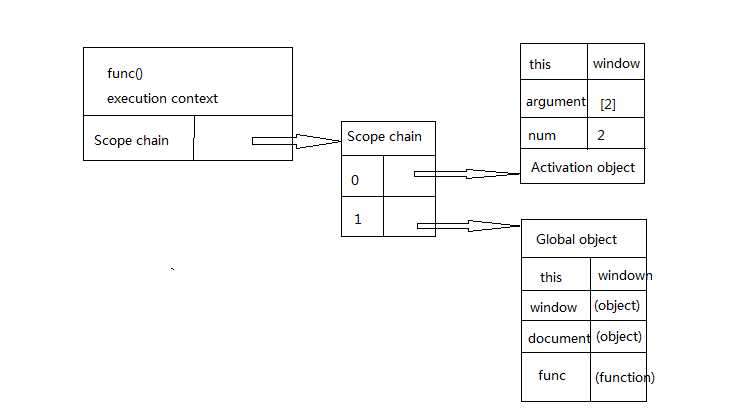
执行此函数时会创建一个称为“运行期上下文(execution context)”(有人称为运行环境)的内部对象,运行期上下文定义了函数执行时的环境。每个运行期上下文都有自己的作用域链,用于标识符解析,当运行期上下文被创建时,而它的作用域链初始化为当前运行函数的[[Scope]]所包含的对象。
这些值按照它们出现在函数中的顺序被复制到运行期上下文的作用域链中。它们共同组成了一个新的对象,叫“活动对象(activation object)”,该对象包含了函数的所有局部变量、命名参数、参数集合以及this,然后此对象会被推入作用域链的前端,当运行期上下文被销毁,活动对象也随之销毁。新的作用域链如下图所示:
**原型链**
每个构造函数都有一个原型对象, 原型对象都包含一个指向构造函数想指针(constructor),而实例对象都包含一个指向原型对象的内部指针(proto)。如果让原型对象等于另一个类型的实例,此时的原型对象将包含一个指向另一个原型的指针(proto),另一个原型也包含着一个指向另一个构造函数的指针(constructor)。
加入另一个原型又是另一个类型的实例 这就构成了实例与原型的链条。
function animal(){
this.type = "animal";
}
animal.prototype.getType = function(){
return this.type;
}
function dog(){
this.name = "dog";
}
dog.prototype = new animal();
dog.prototype.getName = function(){
return this.name;
}
var xiaohuang = new dog();
原型链关系
xiaohuang.__proto__ === dog.prototype
dog.prototype.__proto__ === animal.prototype
animal.prototype.__proto__ === Object.prototype
Object.prototype.__proto__ === null
MVC
全名是Model View Controller,
是模型(model)-视图(view)-控制器(controller)的缩写,
一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。
MVC要实现的目标是将软件用户界面和业务逻辑分离以使代码可扩展性、可复用性、可维护性、灵活性加强。
比如:有一个View会提交数据给Model进行处理以实现具体的行为,View通常不会直接提交数据给Model,它会先把数据提交给Controller,然后Controller再将数据转发给Model。假如此时程序业务逻辑的处理方式有变化,那么只需要在Controller中将原来的Model换成新实现的Model就可以了,控制器的作用就是这么简单, 用来将不同的View和不同的Model组织在一起,顺便替双方传递消息,仅此而已。
组成MVC的三个模式分别是组合模式、策咯模式、观察者模式,MVC在软件开发中发挥的威力,最终离不开这三个模式的默契配合。
View层,单独实现了组合模式
Model层和View层,实现了观察者模式
View层和Controller层,实现了策咯模式
MVC就是将这三个设计模式在一起用了。
线程:
单线程就是按照从上向下的执行顺序
单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务耗时很长,后一个任务就不得不一直等着。
如果排队是因为计算量大,CPU忙不过来,倒也算了,但是很多时候CPU是闲着的,因为IO设备(输入输出设备)很慢(比如Ajax操作从网络读取数据),不得不等着结果出来,再往下执行。
JavaScript语言的设计者意识到,这时主线程完全可以不管IO设备,挂起处于等待中的任务,先运行排在后面的任务。等到IO设备返回了结果,再回过头,把挂起的任务继续执行下去。
于是,所有任务可以分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)。同步任务指的是,在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务;异步任务指的是,不进入主线程、而进入”任务队列”(task queue)的任务,只有”任务队列”通知主线程,某个异步任务可以执行了,该任务才会进入主线程执行。
下面是异步的运行机制
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
(3)一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步
只要主线空了,就会去读取“任务队列” , 这就是javaScript的运行机制,这个过程不会重复。
事件和回调函数
“任务队列”是一个事件的队列(也可以理解成消息的队列),IO设备完成一项任务,就在”任务队列”中添加一个事件,表示相关的异步任务可以进入”执行栈”了。主线程读取”任务队列”,就是读取里面有哪些事件。
“任务队列”中的事件,除了IO设备的事件以外,还包括一些用户产生的事件(比如鼠标点击、页面滚动等等)。只要指定过回调函数,这些事件发生时就会进入”任务队列”,等待主线程读取。
所谓”回调函数”(callback),就是那些会被主线程挂起来的代码。异步任务必须指定回调函数,当主线程开始执行异步任务,就是执行对应的回调函数。
“任务队列”是一个先进先出的数据结构,排在前面的事件,优先被主线程读取。主线程的读取过程基本上是自动的,只要执行栈一清空,”任务队列”上第一位的事件就自动进入主线程。但是,由于存在后文提到的”定时器”功能,主线程首先要检查一下执行时间,某些事件只有到了规定的时间,才能返回主线程。
Event Loop
主线程从”任务队列”中读取事件,这个过程是循环不断的,所以整个的这种运行机制又称为Event Loop(事件循环)。
TCP / IP / HttP
TPC/IP协议是传输层协议,主要解决数据如何在网络中传输,而HTTP是应用层协议,主要解决如何包装数据。关于TCP/IP和HTTP协议的关系,网络有一段比较容易理解的介绍:“我们在传输数据时,可以只使用(传输层)TCP/IP协议,但是那样的话,如果没有应用层,便无法识别数据内容,如果想要使传输的数据有意义,则必须使用到应用层协议,应用层协议有很多,比如HTTP、FTP、TELNET等,也可以自己定义应用层协议。WEB使用HTTP协议作应用层协议,以封装HTTP 文本信息,然后使用TCP/IP做传输层协议将它发到网络上。”
(收集到的图表): 显示不同的TCP/IP和其他的协议在最初OSI模型中的位置:

1、HTTP协议的几个重要概念
1.连接(Connection):一个传输层的实际环流,它是建立在两个相互通讯的应用程序之间。
2.消息(Message):HTTP通讯的基本单位,包括一个结构化的八元组序列并通过连接传输。
3.请求(Request):一个从客户端到服务器的请求信息包括应用于资源的方法、资源的标识符和协议的版本号
4.响应(Response):一个从服务器返回的信息包括HTTP协议的版本号、请求的状态(例如“成功”或“没找到”)和文档的MIME类型。
5.资源(Resource):由URI标识的网络数据对象或服务。
6.实体(Entity):数据资源或来自服务资源的回映的一种特殊表示方法,它可能被包围在一个请求或响应信息中。一个实体包括实体头信息和实体的本身内容。
7.客户机(Client):一个为发送请求目的而建立连接的应用程序。
8.用户代理(Useragent):初始化一个请求的客户机。它们是浏览器、编辑器或其它用户工具。
9.服务器(Server):一个接受连接并对请求返回信息的应用程序。
10.源服务器(Originserver):是一个给定资源可以在其上驻留或被创建的服务器。
11.代理(Proxy):一个中间程序,它可以充当一个服务器,也可以充当一个客户机,为其它客户机建立请求。请求是通过可能的翻译在内部或经过传递到其它的服务器中。一个代理在发送请求信息之前,必须解释并且如果可能重写它。
代理经常作为通过防火墙的客户机端的门户,代理还可以作为一个帮助应用来通过协议处理没有被用户代理完成的请求。
12.网关(Gateway):一个作为其它服务器中间媒介的服务器。与代理不同的是,网关接受请求就好象对被请求的资源来说它就是源服务器;发出请求的客户机并没有意识到它在同网关打交道。
网关经常作为通过防火墙的服务器端的门户,网关还可以作为一个协议翻译器以便存取那些存储在非HTTP系统中的资源。
13.通道(Tunnel):是作为两个连接中继的中介程序。一旦激活,通道便被认为不属于HTTP通讯,尽管通道可能是被一个HTTP请求初始化的。当被中继的连接两端关闭时,通道便消失。当一个门户(Portal)必须存在或中介(Intermediary)不能解释中继的通讯时通道被经常使用。
14.缓存(Cache):反应信息的局域存储。
2.发送请求
打开一个连接后,客户机把请求消息送到服务器的停留端口上,完成提出请求动作。
HTTP/1.0 请求消息的格式为:
请求消息=请求行(通用信息|请求头|实体头)CRLF[实体内容]
请求 行=方法 请求URL HTTP版本号 CRLF
方 法=GET|HEAD|POST|扩展方法
U R L=协议名称+宿主名+目录与文件名
请求行中的方法描述指定资源中应该执行的动作,常用的方法有GET、HEAD和POST。不同的请求对象对应GET的结果是不同的,对应关系如下:
对象 GET的结果
文件 文件的内容
程序 该程序的执行结果
数据库查询 查询结果
HEAD??要求服务器查找某对象的元信息,而不是对象本身。
POST??从客户机向服务器传送数据,在要求服务器和CGI做进一步处理时会用到POST方法。POST主要用于发送html文本中FORM的内容,让CGI程序处理。
一个请求的例子为:
GEThttp://networking.zju.edu.cn/zju/index.htmHTTP/1.0 networking.zju.edu.cn/zju/index.htmHTTP/1.0 头信息又称为元信息,即信息的信息,利用元信息可以实现有条件的请求或应答。
请求头??告诉服务器怎样解释本次请求,主要包括用户可以接受的数据类型、压缩方法和语言等。
实体头??实体信息类型、长度、压缩方法、最后一次修改时间、数据有效期等。
实体??请求或应答对象本身。
3.发送响应
服务器在处理完客户的请求之后,要向客户机发送响应消息。
HTTP/1.0的响应消息格式如下:
响应消息=状态行(通用信息头|响应头|实体头) CRLF 〔实体内容〕
状态行=HTTP版本号 状态码 原因叙述
状态码表示响应类型
1×× 保留
2×× 表示请求成功地接收
3×× 为完成请求客户需进一步细化请求
4×× 客户错误
5×× 服务器错误
响应头的信息包括:服务程序名,通知客户请求的URL需要认证,请求的资源何时能使用。
4.关闭连接
客户和服务器双方都可以通过关闭套接字来结束TCP/IP对话
由于要吸收的知识点较多暂写到这里
以上是关于Web深度面试题(原理)的主要内容,如果未能解决你的问题,请参考以下文章