利用scrapy-client 发布爬虫到远程服务端
Posted knighterrant
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用scrapy-client 发布爬虫到远程服务端相关的知识,希望对你有一定的参考价值。
远程服务端Scrapyd先要开启
远程服务器必须装有scapyd,并开启。
这里远程服务开启的端口和ip:
192.166.12.80:6800
客户端配置和上传
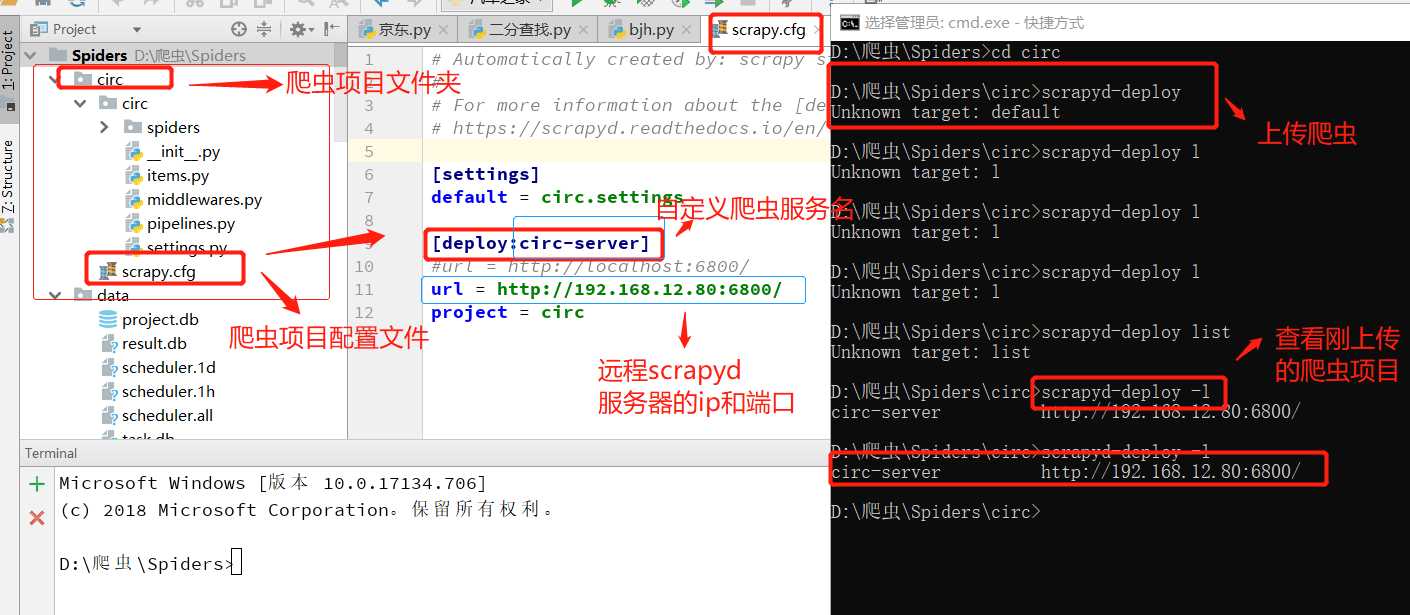
先修爬虫项目文件scrapy.cfg:如下图
cd 到爬虫项目文件夹下,后执行:
scrapyd-deploy # 上传
scrapyd-deploy -l # 查看
打包项目
1、打包前先查看项目下的爬虫文件:
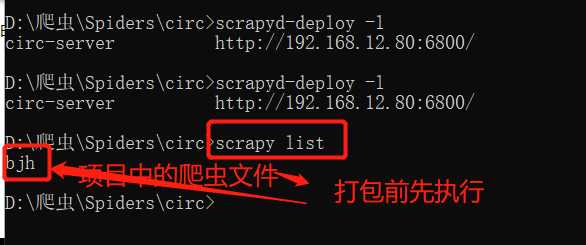
说明可以开始打包了
2.执行打包命令:
scrapyd-deploy 部署名称 -p 项目名称
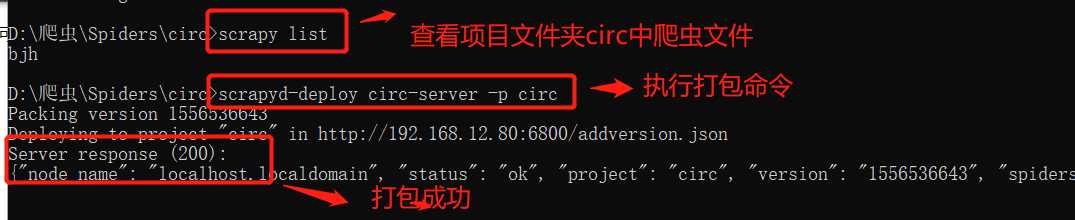
上面表示打包成功。
以下是可能出现的问题,以及解决方案:
如果出现后端报错和scrapyd前端页面报错,解决方案:
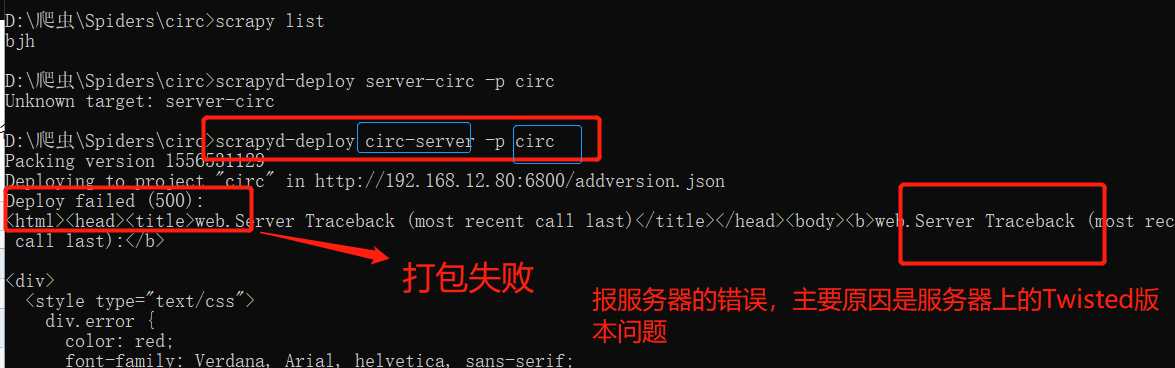
scrapyd 前端报错:
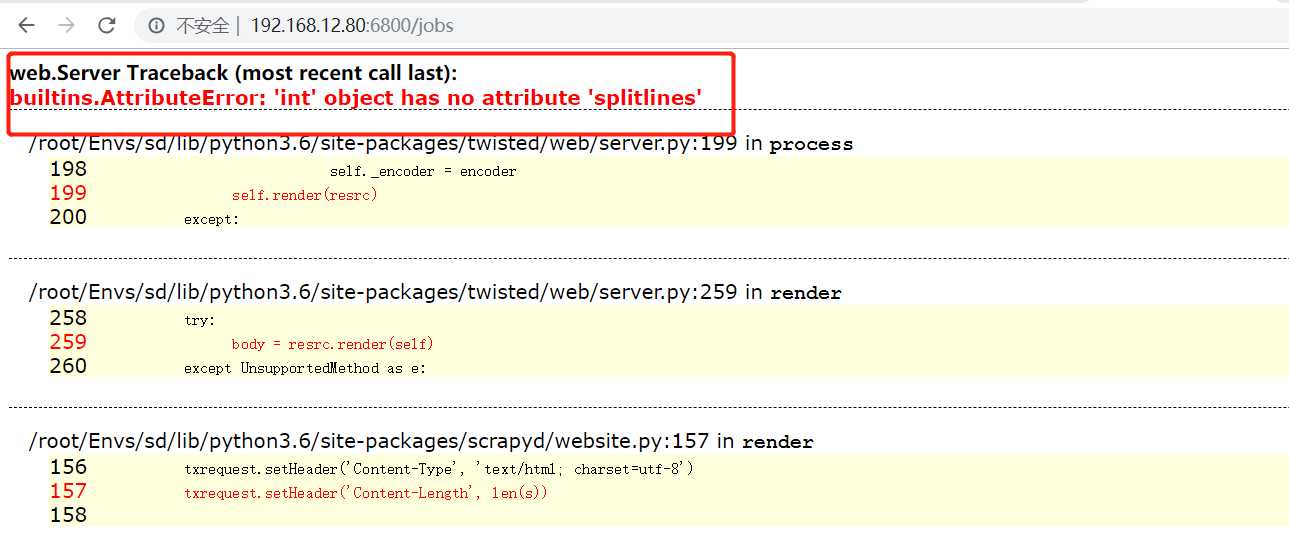
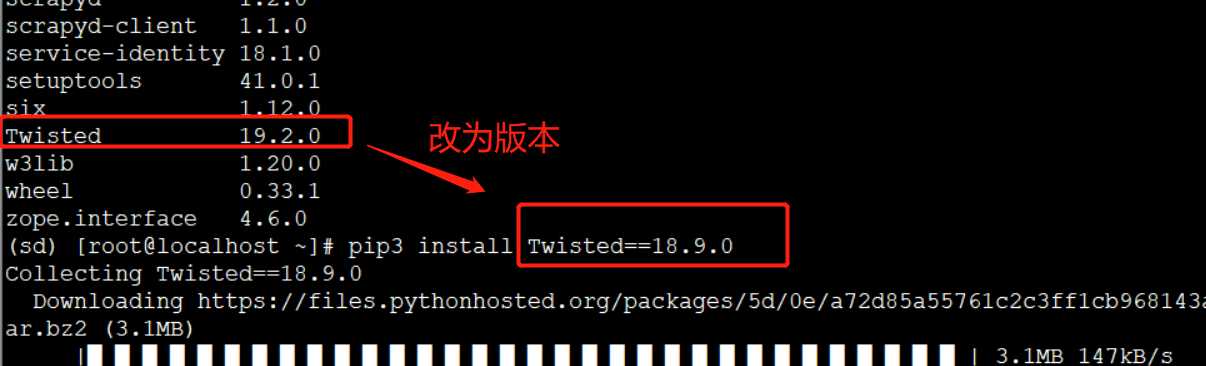
修改远程服务器(192.168.12.80)上的Twisted的版本改为 18.9.0
pip3 install Twisted==18.9.0
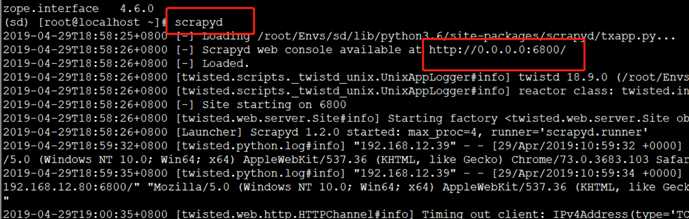
重启 Scrapyd:
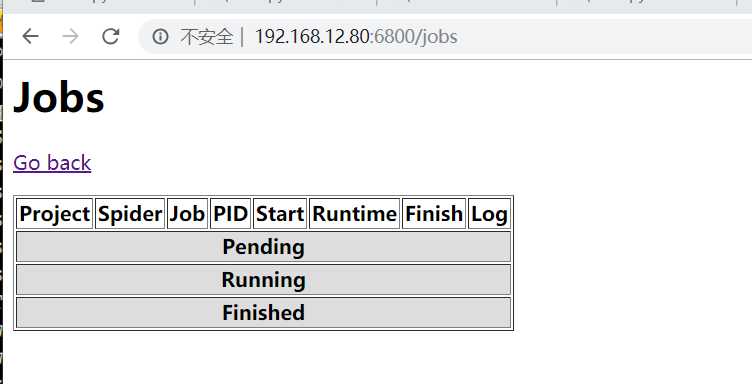
在访问192.168.12.80:6800/jobs,正常显示:
3.上传运行爬虫
curl http://远程ip:6800/schedule.json -d project=项目名称 -d spider=爬虫名称
如:
curl http://192.168.12.80:6800/schedule.json -d project=circ -d spider=bjh
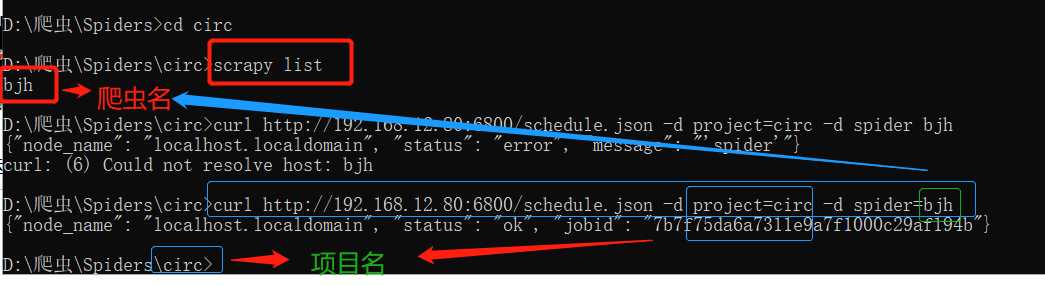
说明部署成功:
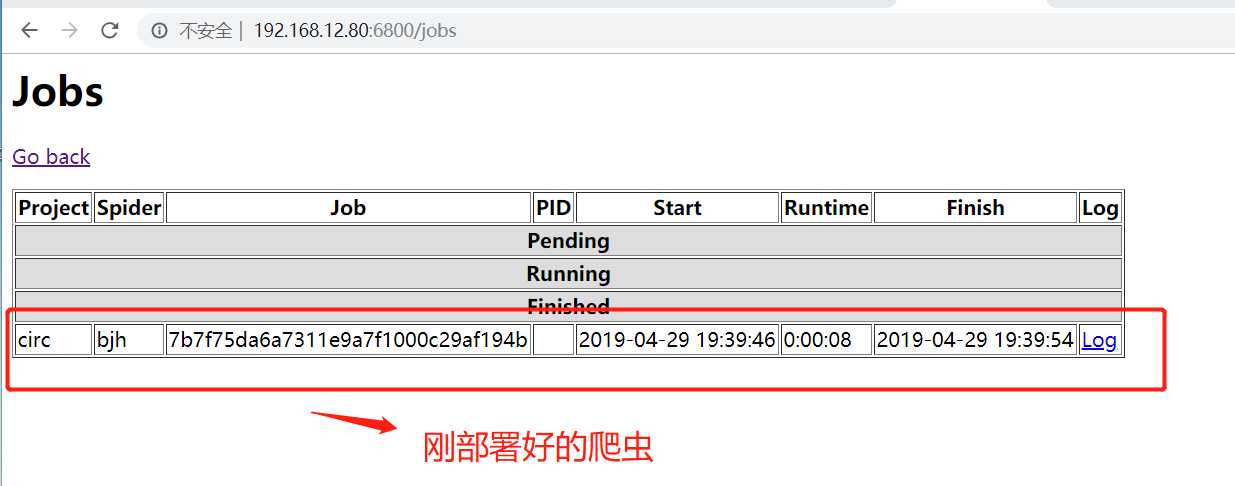
scrapyd部署已经完成了。
管理
1、停止爬虫
curl http://localhost:6800/cancel.json -d project=scrapy项目名称 -d job=运行ID
2.删除scrapy项目
注意:一般删除scrapy项目,需要先执行命令停止项目下在远行的爬虫
curl http://localhost:6800/delproject.json -d project=scrapy项目名称
3.查看有多少个scrapy项目在api中
curl http://localhost:6800/listprojects.json
4.查看指定的scrapy项目中有多少个爬虫
curl http://localhost:6800/listspiders.json?project=scrapy项目名称
5总结几个请求url,通过在浏览器输入,也可以监控爬虫进程。
例子:地址栏访问 :http://192.168.12.80:6800/daemonstatus.json,获取到一下页面


1、获取状态
http://127.0.0.1:6800/daemonstatus.json
2、获取项目列表
http://127.0.0.1:6800/listprojects.json
3、获取项目下已发布的爬虫列表
http://127.0.0.1:6800/listspiders.json?project=myproject
4、获取项目下已发布的爬虫版本列表
http://127.0.0.1:6800/listversions.json?project=myproject
5、获取爬虫运行状态
http://127.0.0.1:6800/listjobs.json?project=myproject
6、启动服务器上某一爬虫(必须是已发布到服务器的爬虫)
http://127.0.0.1:6800/schedule.json (post方式,data={“project”:myproject,“spider”:myspider})
7、删除某一版本爬虫
http://127.0.0.1:6800/delversion.json
(post方式,data={“project”:myproject,“version”:myversion})
8、删除某一工程,包括该工程下的各版本爬虫
http://127.0.0.1:6800/delproject.json(post方式,data={“project”:myproject})
以上是关于利用scrapy-client 发布爬虫到远程服务端的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫从入门到放弃(二十一)之 Scrapy分布式部署
Heroku 上的 Scrapy 爬虫返回 503 服务不可用