Large-Margin Softmax Loss for Convolutional Neural Networks
Posted nowgood
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Large-Margin Softmax Loss for Convolutional Neural Networks相关的知识,希望对你有一定的参考价值。
paper url: https://arxiv.org/pdf/1612.02295
year:2017
Introduction
交叉熵损失与softmax一起使用可以说是CNN中最常用的监督组件之一。 尽管该组件简单而且性能出色, 但是它只要求特征的可分性, 没有明确鼓励网络学习到的特征具有类内方差小, 类间方差大的特性。 该文中,作者提出了一个广义的 large margin softmax loss(L-Softmax),是large margin系列的开篇之作. 它明确地鼓励了学习特征之间的类内紧凑性和类间可分离性。
Softmax Loss
Softmax Loss定义如下
\\[ \\bf \\text{Softmax Loss = FC + Softmax + Cross-Entropy} \\]
 ?
?
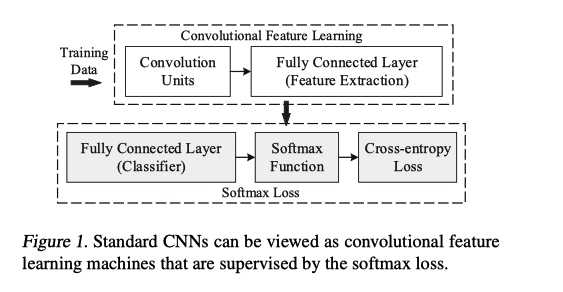
如上图, 当前CNN分类网络可以看成 特征提取backbone+Softmax Loss 部分
特征提取网络最后一层特征记为 \\(\\bf x\\), 最后一层 FC 可以看成一个 N 类线性分类器, N 为类别数.
Insight
由于 Softmax 并没有明确地鼓励类内紧凑性和类间分离性。 基于此, 该文中一个insight就是, 特征提取网络提取的特征向量 x 和与相应类别c的权重向量\\(W_c\\)的乘积可以分解为模长+余弦值:
\\[W_cx = ||W_c||_2 ||x||_2 \\cos(θ_c)\\]
其中, c为类别索引, \\(W_c\\) 是最后一个FC层的参数, 可以认为是的类别 c 的线性分类器。
从而, Softmax Loss 重构如下
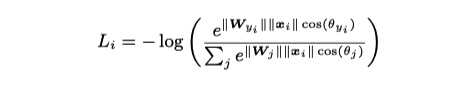 ?
?
这样, 在L-Softmax loss中,类别预测很大程度上取决于特征向量\\(x\\)与权重\\(W_c\\)的余弦相似性.
method
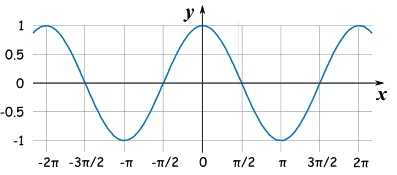
余弦函数如下
 ?
?
当 \\(\\theta = [0, \\pi]\\)时候, \\(\\cos(\\theta)\\) 单调递减
下面以二分类为例, 对于类别 1
Softmax 要求,
\\[W_1x > W_2x\\]
\\[\\Downarrow\\]
\\[||W_1||_2 ||x||_2 \\cos(θ_1) > ||W_2||_2 ||x||_2 \\cos(θ_2)\\]
\\[\\Downarrow\\]
\\[||W_1||_2 \\cos(θ_1) > ||W_2||_2 \\cos(θ_2)\\]
L-Softmax 要求,
\\[
||W_1||_2 \\cos(mθ_1) > ||W_2||_2 \\cos(θ_2)
\\]
那么, 由于\\(\\cos\\theta\\) 在 \\([0, \\pi]\\)上的单调递减特性, 有如下不等式
\\[||W_1||_2 \\cos(θ_1) \\gt ||W_1||_2 \\cos(mθ_1) > ||W_2||_2 \\cos(θ_2), \\quad m \\gt 1\\]
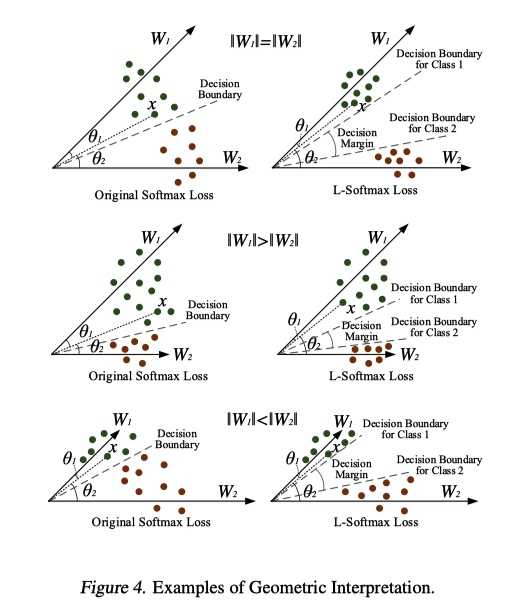
几何上直观理解如下
 ?
?
property
L-Softmax损失具有清晰的几何解释. m控制类别之间的差距. 随着m越大(在相同的训练损失下),类之间的margin变得越大, 学习困难也越来越大.
L-Softmax损失定义了一个相对困难的学习目标,可调节margin(margin 表示了特征学习困难程度)。 一个困难的学习目标可以有效地避免overfiting,并充分利用来自深层和广泛架构的强大学习能力。
experiment result
toy example
 ?
?
 ?
?
 ?
?
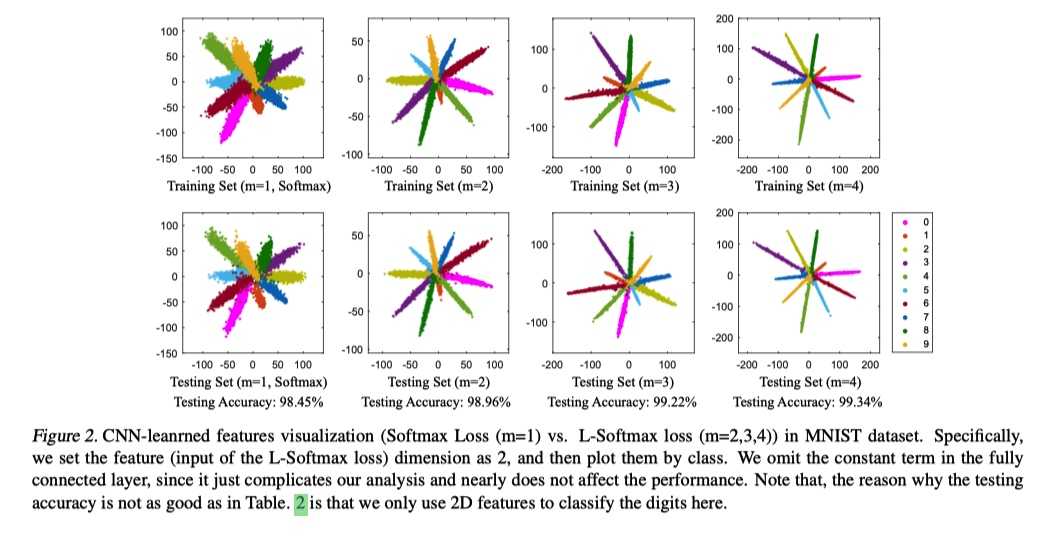
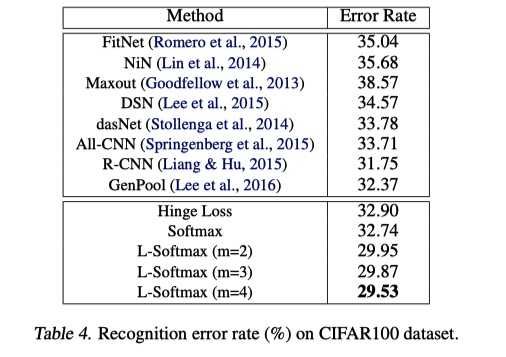
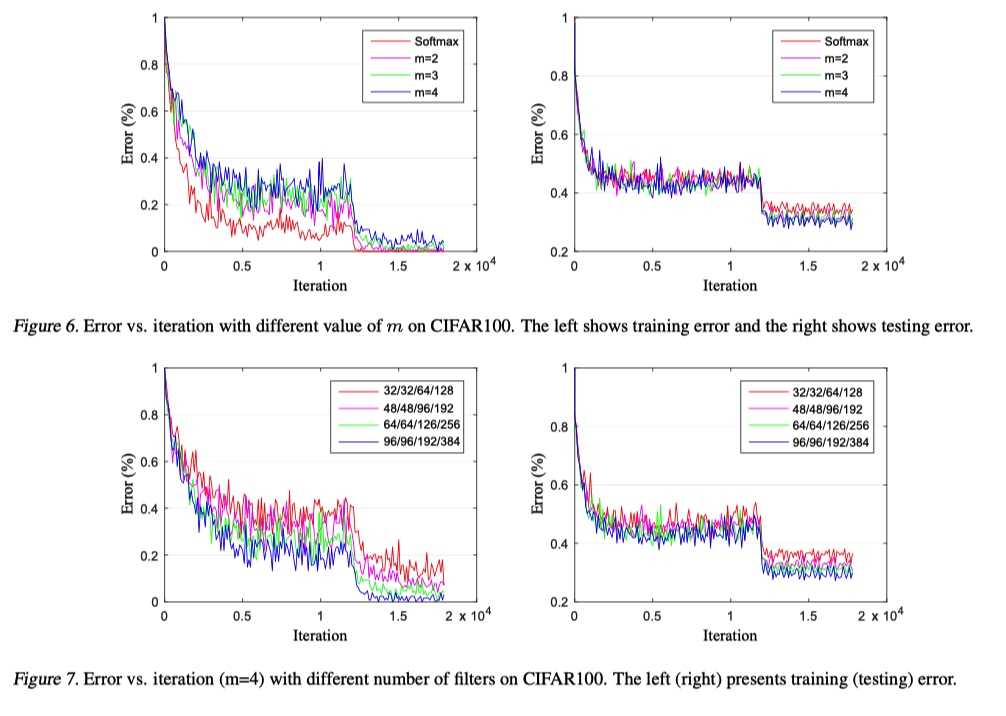
可以看出, L-softmax 的训练损失更大, 但是在测试集上损失更小.
thought
该篇论文为 larger-margin softmax loss 的开篇之作. 提出乘性 larger-margin softmax loss, 相较与加性 larger-margin softmax loss(如 AM-softmax, ArcFace), 训练难度更大(需要用到退火训练方法, 见原文 5.1), 效果而言, 也是加性 loss 更好.
从
\\[||W_1||_2 \\cos(θ_1) \\ge ||W_1||_2 \\cos(mθ_1) > ||W_2||_2 \\cos(θ_2), \\quad m \\ge 1\\]
可以看出, 该不等式不仅依赖余弦角度而且依赖最后一层 FC 的权重的模长, 所以, 为了学习的特征更加专注于对于余弦角度的优化, 后面一批论文很多都用到权重归一化, 效果很好.
同时可以看到, 在特征分类时, 其实 feature 的模长会被消元, 为了各个类别学习的特征更加有判别能力, 后面一批论文也做了特征归一化(实际上将特征模长限制为 1 会降低特征的表达能力, 其实在加难特征学习的过程)
总之, 后面的各个large margin 系列, 特征归一化, 权重归一化已经是标配了.
?
以上是关于Large-Margin Softmax Loss for Convolutional Neural Networks的主要内容,如果未能解决你的问题,请参考以下文章