数据库的总结
Posted bky-lxm
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库的总结相关的知识,希望对你有一定的参考价值。
(1)sys / system的区别:
System是数据库内置的普通管理员,手动创建任何用户在被授予dba角色后与system这个用户差 不多。而sys是数据库超级用户,数据库的很多重要东西(字典、内置包、静态数据字典视图等)都属于这个用户,该用户只能以sysdba的身份登录。任何用户以as sysdba登录时都是sys,通过命令show user可查看得知。
(2)数据库:存储在磁盘上的文件,这些文件中保存的数据有一定的物理结构和逻辑结构。
数据库名:数据库的名称表示,该叫法一般用于单机。
全局数据库名:由“数据库名称”+ “域名”组成,是数据库处于网络中的名称标示。
如“orcl.localhost”,其中数据库名称设定于DB_NAME,域名设定于DB_DOMAIN。这两个 . 参数合并之后可在网络中唯一标识一个数据库。
SID = Oracle实例,是实例的唯一标识。用户访问数据库,实际上是向一个Oracle实例发送请求, Oracle实例负责向数据库获取数据。
Oracle实例 = 内存结构+后台进程,所以Oracle实例是临时性的; 可以通过startup nomount去启动实例,但是注意这时Oracle数据库并没有启动,需要用open去启动数据库; 一个实例只能对应一个数据库,一个数据库可以用多个实例。
(3)结构化查询语言(sql: structured query language)分类:
1、数据操纵语言(DML:data manipulation language):
insert update delete
2、数据定义语言(DDL:data defination language):
create alter drop rename truncate
3、数据控制语言(DCL:data control language):
grant revoke
4、数据查询语言(DQL:data query language):
select
(4)数据库三级模式(外模式、模式、内模式):
数据库领域公认的标准结构是三级模式结构,它包括外模式、模式和内模式,有效地组织、管理数据,提高了数据库的逻辑独立性和物理独立性。用户级对应外模式,概念级对应模式,物理级对应内模式,使不同级别的用户对数据库形成不同的视图。所谓视图,就是指观察、认识和理解数据的范围、角度和方法,是数据库在用户“眼中"的反映,很显然,不同层次(级别)用户所“看到”的数据库是不相同的。
外模式:对应于用户级,是某几个用户能看到的数据库的数据视图,是从模式中导出的子集,包含模式中允许特定用户使用的那部分数据。通过DML来描述定义。
模式:对应于概念级,是对数据库中全部数据的逻辑结构、特征的总体描述,是所有用户的公共数据视图。由DDL语言来描述定义。
内模式: 称为存储模式,对应物理级,是 数据库全体数据的内部表述或底层描述,描述数据在物理介质上的存储方式和物理结构,对应着实际存储在外存储器上的数据库。
(5)sql窗口、命令窗口区别:
sql窗口只能执行sql语句。
而命令窗口可执行命令。如:desc emp;(查看表结构)
(6)数据字典
数据库是数据的集合,数据库维护和管理这用户的数据,那么这些用户数据表都存在哪里,用户的信息是怎样的,存储这些用户的数据的路径在哪里,这些信息不属于用户的信息,却是数据库维护和管理用户数据的核心,这些信息就是数据库的数据字典来维护的,数据库的数据字典就汇集了这些数据库运行所需要的基础信息。
(7)sql建表规范化:
http://blog.csdn.net/liguihan88/article/details/3002403
方式一:
create table ctable_name
(
field1 varchar2(20), --注释的内容1
field2 number, --注释的内容2
field3 char(2), --注释的内容3
field4 date /*注释的内容4*/
)
方式一的缺点:在表结构不复杂时使用,但是表复杂,阅读不方便。
方式二:
create table ctable_name
(
field1 varchar2(20),
field2 number,
field3 char(2),
field4 date
)
comment on table ctable_name is ‘这里写表注释‘;
comment on column ctable_name.field1 is ‘这里写列注释‘;
select * from user_tab_comments whereTABLE_NAME = ‘这里写选择的表名‘;
--查询表的相应注释
select * from user_col_comments where TABLE_NAME = ‘这里写选择的表名‘;
--查询表中相应的列注释
(8)列别名:
三种方式:(column对应的列,alias别名)
1/column alias
2/column ‘‘alias‘‘
3/column as alias
(9)转义字符:escape
例子:select * from emp e where e.ename like ‘5_%%‘ escape ‘5‘;
--意思是搜索以‘5_‘开头的。
(10)SQL优化问题: (这个网址很好)
http://blog.csdn.net/orclight/article/details/8634839
目前我能理解的3个:
1、SQL语句用大写,因为oracle解析SQL语句时,是用大写进行解析的。
2、oracle解析where子句采用从右到左,因此,能最大程度过滤数据的应放在子句尾部。
3、避免采用*,oracle解析*是通过数据字典完成的。
(11)拼接字段(||, +)
– 首选|| (mysql中||表示or,一般用concat() )
(12)并集、全集、交集、差集
union(并集):去掉重复的
union all(全集):包含重复的
intersect(交集)
minus(差集):属于前者,不属于后者
(13)组函数
avg min max count sum
其中除了count,其他4个在数据处理时都跳过空值。
(
而对于count,只有count(*) 或count(n数字)能处理空值,
count(e.comm)直接跳过空值。
例子:select count(a.comm) from (select e.comm from emp e) a;
)
avg/sum只适用于数字类型。
min/max适用于任意数据类型。
例子:select count(distinct e.deptno) from emp e;
ps:组函数不能处理null的数据,需要通过nvl解决。
(14)分组group by
例子:select e.deptno, min(e.sal)
from emp e
where e.sal>1000 --where是对行操作,应放于group by前面
group by e.deptno --分组
order by e.deptno; --排序(若没有,则隐式的采用降序(分组特有))
PS:如果分组中有null,则null会作为一个分组返回。
PS:group by.pdf中第五页很好的解释了这个:
select e.deptno, count(1)
from emp e
where e.sal > --这里的where子句用于对行数据进行筛选(数据进入分组前)
any(select avg(sal) from emp group by deptno)
group by e.deptno
order by e.deptno;
PS:select e.* from emp e order by e.mgr asc nulls first;
(15)视图(view)
也称虚表, 不占用物理空间,这个也是相对概念,因为视图本身的定义语句还是要存储在数据字典里的。视图叧有逻辑定义。每次使用的时候, 叧是重新执行SQL.
创建视图:
create (or replace) view v$_emp_dept (alias)
as
(select ....from....) with read only;(添加只读)
撤销视图:
drop view v$_emp_dept;
查找用户视图:
select * from user_views;
修改视图对应的基表数据时,如果对应的是多个基表,则一次只能修改对应一个基表的数据。
(16)数据库:
行式存储:查找行数据很快,更易于维护。
列式存储:找一行数据要遍历全表,但是查找具体列速度很快。
(17)关系型:(概念)指的是表之间的联系。
非关系型:更擅长大量数据的存储。(毕竟关系型貌似是按行查找)
(18)dual虚表的存在是为了实现SQL语法。
(19)DML insert:::
两种方法:
方法一:insert into table_name [(????)] values(???);
方法二:insert into table_name [(????)] (子查询select ?? from ?????)
PS:用已有的表来创建新表:
create table table1 as select * from emp e where 1=2;
----->条件始终未false,因此只复制了表结构,未复制表数据。
(insert into table1 select * from emp e where e.empno = 10;)
create table table2 as select * from emp e where 1=1;
------>条件始终未true,因此不但复制了表结构,也复制表数据。
删除表数据:
delete from table_name [where ...]
truncate table_name;
http://blog.sina.com.cn/s/blog_6daab81101019ail.html
两者区别:
(1、truncate、delete只删表数据,不删表结构。truncate相当于删除表,然后根据表结构重新创建(表结构、列、约束、索引不变、序列所对应的计数值不变,如要保留计数值,用delete),相比起delete,产生的系统、事务日志少。
delete每删除一行数据,就会在事务日志上记录。而truncate通过释放表数据所用的数据页来删除数据,并且只在事务日志上记录页的释放。
(2、delete是dml语句,会产生事务;而truncate是ddl语句,不产生事务。
(3、存在外键约束的,不能使用truncate--由于日志中不记录,不能激活触发器。
(4、truncate不能用于参与视图索引的表。
(20)事务
(1、事务是一个不可分割的操作序列,要么都做,要么都不做。是数据库环境的逻辑工作单位。
(2、其存在是为了保持数据库完整性。
(3、事务不能嵌套。
(4、在oracle中,没有事务开启的语句,事务通过DML语句开启。
(5、当一个事务开启后,系统会对该用户正在进行修改并未commit/rollback的行数据添加行级锁,以保证在同一时间,只有一个用户能对该条数据进行dml操作。
事务结束与一下情况:
一、用户执行commit提交事务、rollback回滚事务。
二、执行DDL语句时自动提交。
三、用户正常断开连接时自动提交。
四、系统崩溃、断电时自动回滚事务。
断点:savepoint用来让事务回滚的一个中途临时点。用于将事务分成多个单元。
--与 rollback to savepoint_name;对应。
事务的四个属性(ACID):
(1、原子性(Atomicity):要么都提交,要么都回滚。
(2、一致性(Consistency):保证底层数据的完整性。
(3、隔离性(Isolation):加锁。事务的进程不受外界的影响。
(4、持久性(Durability):在事务未提交、回滚前,相关数据存储在某个物理介质中,以保证这些操作在系统出错时不会丢失。
(21)sql语句里有个begin...end,暂不知道用法,不知道这个需不需要记?
(22)创建用户:create user username identified by password;

(23)序列 Sequence
序列是oracle专有的,用于产生一个自动递增的数列。
select sequence_name from user_sequences; 查询序列
create sequence seq_name 1
increment by n --每次增长多少
start with n --以什么开始
maxvalue n | nomaxvalue --循环/不循环
minvalue n | nominvalue
cycle
cache n; --分配并存入到内存中
这里有问题,关于start with 以及nextval的问题。
另外貌似周期的大小必须大于缓存的大小??
序列上的计数值是只存储在该序列中吗,对于应用到的表,表会不会对此有相应记录??
----->!!!!网上说能对自动增值字段做归零处理,但是实验为啥不行???
----->truncate确实对序列值不能做归零处理。
ppt(用户管理、序列)最后一页也有错误,先在dual中运行一次nextval,然后再插入数据,错的离谱。
========================================================
create sequence test
increment by 1
start with 1;
drop sequence test;
create table test1 (
no number(4),
name varchar2(10)
);
drop table test1;
delete from test1;
insert into test1 values(test.currval, ‘张三‘);
insert into test1 values (test.nextval, ‘张三‘);
select * from test1;
select test.nextval from dual;
------------------------------------------------
create sequence test
increment by 1
start with 1
maxvalue 10
cycle
cache 10; //提示chache 值必须小于cycle值
========================================================
(24)建表
方法一:
例子:
create table test (
id number(可不填,默认38位),
name varchar2(20) not null unique,
sex number(1) not null,
age number(3),
sdate date,
grade number(2) default 1, --默认值为1
email varchar2(50)
);
方法二:
采用子查询。
create table test (....) as (子查询);
修改表结构
(1、增加列:
alter table table_name add column type();
注意:采用该方式新增加的列不能设定为 not null, 因为基本表在增加一列后,原有的元组 . 在新增的列上值都定义为空。
(2、删除列:
alter table table_name drop column;
(3、修改列:
alter table table_name modify(column type());
(4、修改表名:
rename old_name to new_name;
(5、删除表
drop table table_name cascade constraints;
(25)约束:
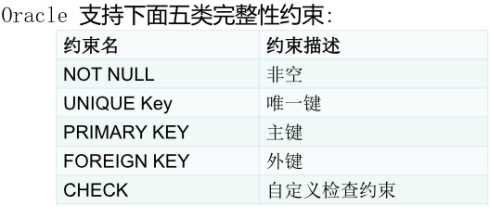
创建约束的时机:
(1、建表时添加
(2、建表后创建
从作用上分:
(1、列级约束:只能约束其中一列,可定义任何约束。
(2、表级约束:可约束任意一列、多列,可以定义除not null以外的任何约束。
例子:
列级约束:
create table table_name (
no number unique primary key,
name varchar2(20) not null,
no2 number references foreign key table_name(column),
birthday date constraint $name not null, --给列级约束自定义名称$name
day number check(day > 0) --自定义约束
);
表级约束:
create table table_name (
no number(5) unique,
dept number(2),
constraint $name foreign key(dept) references table_name(column),
constraint $name primary key(no) --该写法需要自定义约束名称$name
constraint $name check (dept >0) --自定义约束
);
——————————————————————
在外部,对约束可以增加、删除,但是不能修改!!!!
alter table table_name
add constraint $name unique(column);
drop constraint $name;只能通过约束名
(26)关系数据库的三类完整性
一、实体完整性:主键不能为空
二、参照完整性:不能引用非法的实体。即外键值要满足相关要求,不能用非法数据。
三、用户自定义完整性:满足具体的语义要求。
(27)删除存在外键的表的三种方式:(更多的时候,用于行数据删除而不是整表)
一、 restrict方式:当依赖表中没有外键值与要删除的主表中的主键值对应时,才能删除。
二、cascade方式:级联删除。将依赖表中所有与主表中要删除的主键值对应的记录一同删除。
三、set null方式:将依赖表中所有与主表中被删除的主键值对应的外键值设为null。
(28)数据库对象:
表、视图、索引、约束、序列
命名规则:
(1、以字母开头
(2、可包括数字、# 、_ 、 $
(29)索引:
用于加快对数据的搜索。通过快速路径访问的方法快速定位数据,减少磁盘i/o。
SQL中的索引是非显示索引,在用户查询时自动调用。
优劣:
(1、索引能改善操作的性能, 但会降低数据修改的性能,执行这些操作时,DBMS需要动态的更新索引。
(2、索引可能要占用大量存储空间。
(3、唯一性不好的数据并不适用于索引。
(4、索引用于数据过滤、数据排序。
创建索引:
方法一:自动为表上定义为主键、unique约束的列创建。
方法二:手动创建。
create index $name on table(column....);
drop index $name;
(30)oracle表的隐藏字段:
rowid / rownum
rowid:可唯一的表示行数据。----可用于删除重复数据(只要某列具备唯一性,就能实现)
rownum:用于对搜索的结果添加排序。(在取的数据时产生序号,即rownum在order by之前执行。)----可用于分页。
利用rownum在大批量数据中查找几列时:
select * from
(select a.*, rownum rn from
(select * from emp order by ename) a
where rownum <= 10) b --先确定一个小范围,减少搜索量
where b.rn >5; --再确定具体的范围
去重:
select * from emp
where e.rowid not in
(select min(rowid) from emp e group by e.ename having count(1) >1);
(31)数据库范式
第一范式:属性不能分割。(存在部分依赖,即多个候选主键)
第二范式:非主属性完全依赖于码(候选主键,具备唯一性),不能部分依赖,即组合的码中存在单独一个元素能决定非主属性。(组合主键若进行拆分,则不能唯一确定元组)
第三范式: 消除传递依赖。属性A可以确定B,然后B可以确定C
http://blog.sina.com.cn/s/blog_46d817650100yj2i.html
(32)关于排序,oracle中对字母的大小写,是优先对大写字母排序,拍完后才开始拍小写字母。
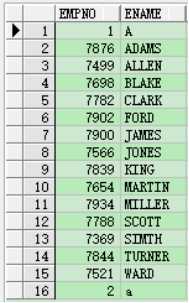
(33)oracle段延迟:
在新建表后,往表中插入序列时,insert into...(nextval...),该序列start with 1,但是显示的是从2开始。
因为oracle11g采用了段延迟技术,在建表后,oracle考虑到大量的空表会占用很多空间,因此在该表被实际使用前,oracle都不会为该表分配段空间。因此第一次插入数据(插入序列)时,是从2开始。
解决方法:
方法一:
在第一次对表进行DML操作时不插入序列。
方法二:
在新表中插入序列,事务回滚,删除该序列,然后重建该序列,重新插入,即可。
http://blog.csdn.net/bisal/article/details/38434007
(34)SimpleDateFormat
util.Date
(35)IN操作符一般比一组OR操作符执行速度快。
(36)通配符的检索速度很慢,最好不要放到筛选条件的开始处。
(37)书上说虽然给列的别名起具体的名字可以提高可读性,但是这样会给客户端应用带来许多问题,因此最好使用单个字母。
(38)SQL中有个函数soundex(str)可以根据发音来匹配,但必须英文字母。
select * from emp e where soundex(e.ename) = soundex(‘join‘);
注意:这个的匹配是按照一定的规律的:
http://www.2cto.com/database/201401/273013.html
http://blog.csdn.net/perny/article/details/7971003
http://www.cnblogs.com/zhwl/p/3750118.html
以上是关于数据库的总结的主要内容,如果未能解决你的问题,请参考以下文章