识别同音字词pypinyin, 分词 jieba
Posted robertx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了识别同音字词pypinyin, 分词 jieba相关的知识,希望对你有一定的参考价值。
一.pypinyin
在处理语音输入指令时, 比如 请给圆圆发消息,那么转化为文字识别时, 无法确定转换的是圆圆还是园园或是源源, 为了解决这个问题, 就把指令转换为拼音来处理,这样就可以处理同音字了.用到的库为pypinyin
 简单使用, TONE,TONE2,TONE3为不同转换模式
简单使用, TONE,TONE2,TONE3为不同转换模式
from pypinyin import lazy_pinyin,TONE,TONE2,TONE3 a = ‘圆圆‘ b = ‘源源‘ c = ‘园园‘ print(‘‘.join(lazy_pinyin(a, style=TONE))) print(‘‘.join(lazy_pinyin(b, style=TONE2))) print(‘‘.join(lazy_pinyin(c, style=TONE3))) #结果 yuányuán yua2nyua2n yuan2yuan2
二 jieba
import jieba a = ‘我们来试试这个分词‘ print(jieba.cut(a)) # <generator object Tokenizer.cut at 0x0000019C3F4523B8> print(list(jieba.cut(a)))

import jieba jieba.add_word(‘这个分词‘) # 添加分词 a = ‘我们来试试这个分词‘ print(jieba.cut(a)) # <generator object Tokenizer.cut at 0x0000019C3F4523B8> print(list(jieba.cut(a)))
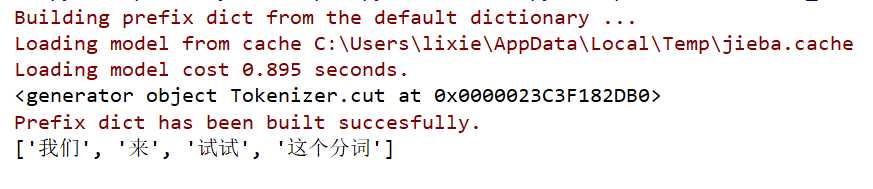
这个模块仅对中文支持友好,英文什么的就不好用了.如果想用英文分词的话,在google的tensorflow里面有一个功能很好用
以上是关于识别同音字词pypinyin, 分词 jieba的主要内容,如果未能解决你的问题,请参考以下文章