python爬虫踩坑教程
Posted linjiaqin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫踩坑教程相关的知识,希望对你有一定的参考价值。
我们的目标是爬取下面这个个网址上的2010~2018年的数据
http://stockdata.stock.hexun.com/zrbg/Plate.aspx?date=2015-12-31
获取我们需要的表格中的某些列的数据?
(这是我从我的微信公众号帮过来的文章)
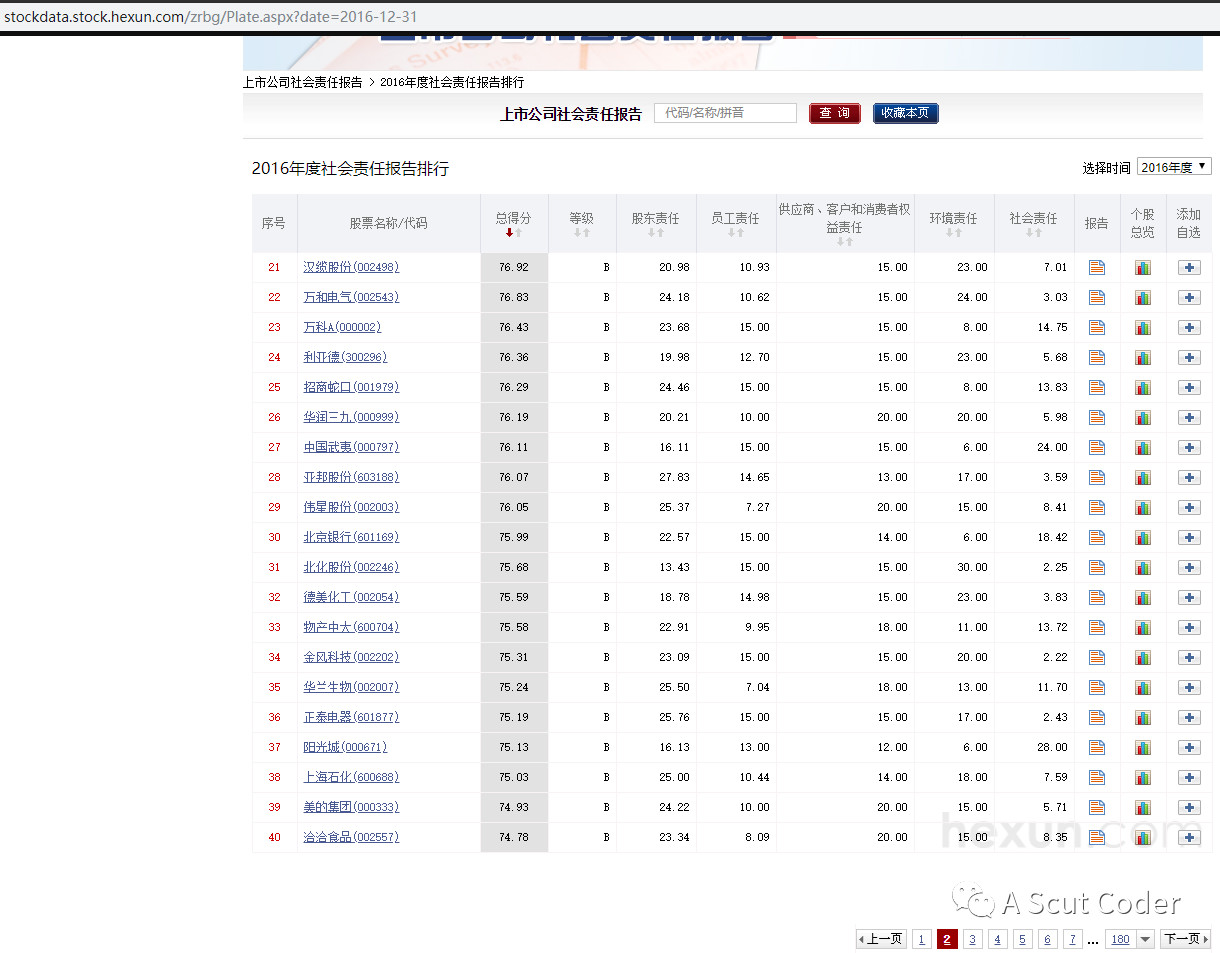
第一步,我们首先用谷歌浏览器查看网页源码,但是可以说现在的数据都是js动态传输不可能会在原始网页上显示?,所以这一步其实是没用的。
第二步,我们分析网页元素,ctrl+shift+c
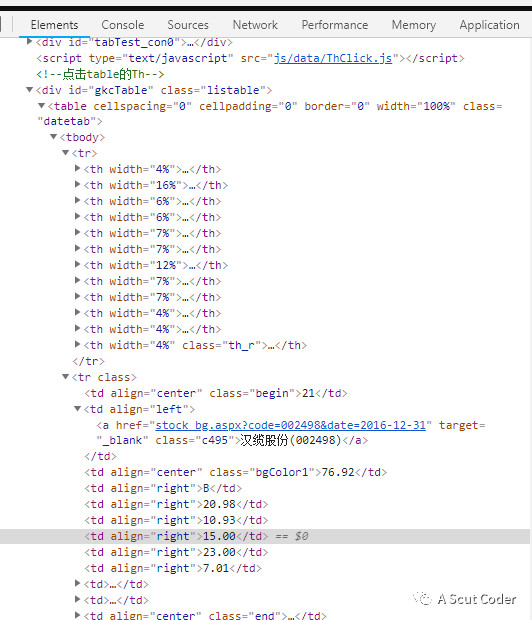
依然没有多大用,因为每一页只显示20条数据,而且我们发现点下一页的时候,网页网址并没有跳转或改变
这时只能看network元素了
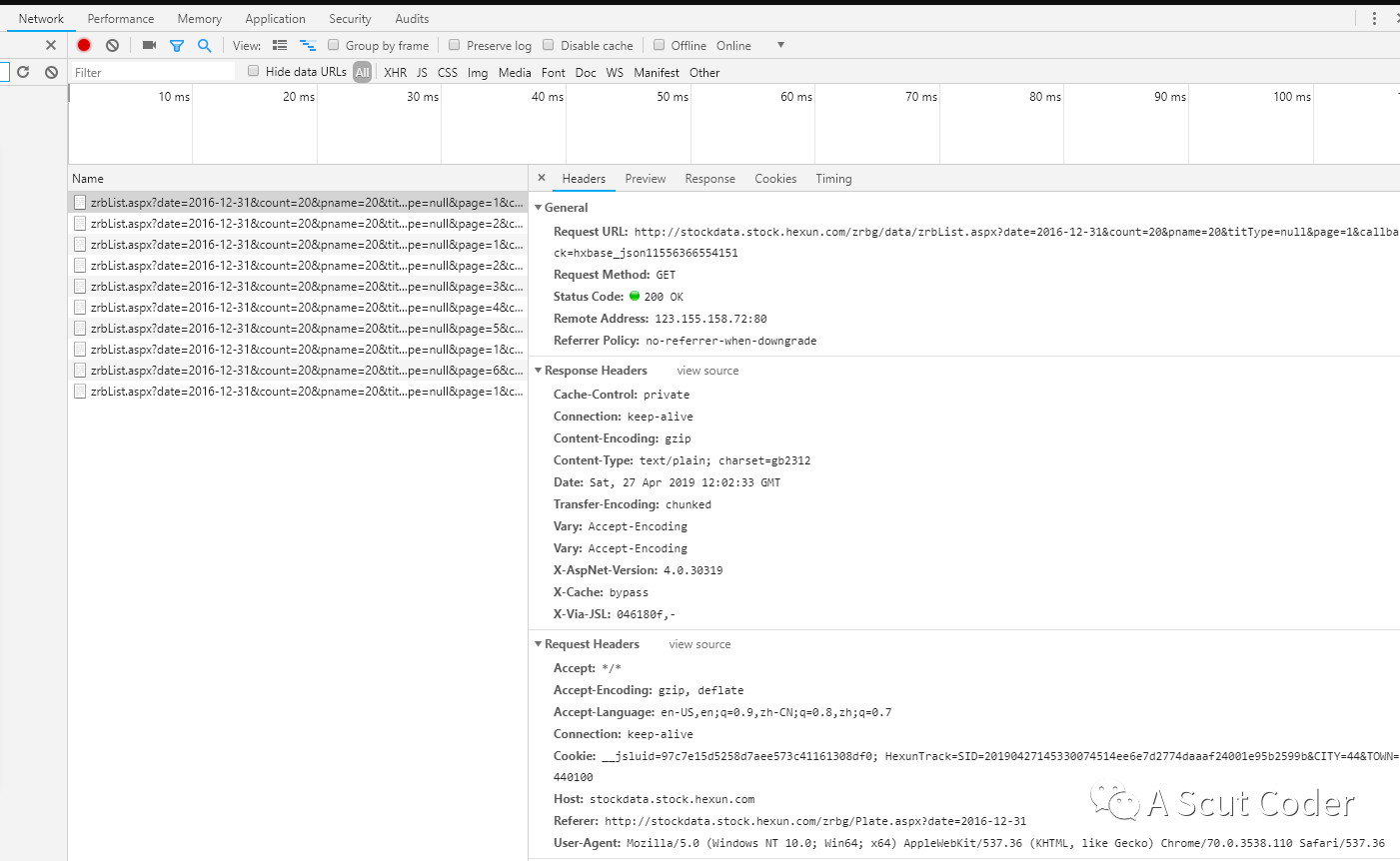
我们知道了数据都是通过这个链接去获取的http://stockdata.stock.hexun.com/zrbg/data/zrbList.aspx?date=2016-12-31&count=20&pname=20&titType=null&page=1&callback=hxbase_json11556366554151
通过尝试发现,有用的参数只有page和count
page表示第几页,count表示每页采集多少条数据
第三步,现在我们开始写代码
第一次我们遇到了403错误,因为我们直接发送url,没有对头部进行代理设置,所以被反爬了?。
第二次,纠结urllib2和urllib和requests用哪个
1)下面是urllib的使用
import urllib.request req = urllib.Request(url) req = urllib.request.Request(url) req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/70.0.3538.110 Safari/537.36") req.add_header("GET",url) req.add_header("Host","stockdata.stock.hexun.com") #使用read()方法才能读取到字节而不是httpresopnse #同时out必须是写入str而不是字节 content = urllib.request.urlopen(req).read()
发现read方法得到的只是字节而不是字符串,然后我就不知道怎么办了,放弃?。,使用requests2)Requests
requests模块的介绍: 能够帮助我们发起请求获取响应
response常见的属性:
response.text 响应体 str类型
respones.content 响应体 bytes类型
response.status_code 响应状态码
response.request.headers 响应对应的请求头
response.headers 响应头
response.request._cookies 响应对应请求的cookie
response.cookies 响应的cookie(经过了set-cookie动作)
解决网页的解码问题:
response.content.decode()
response.content.decode("GBK")
基本使用:
1.requests.get(url,headers,params,cookies,proxies)
headers:字典 请求头
cookies: 字典 携带的cookie
params: 字典 url地址的参数
proxies: 字典 代理ip
2.requests.post(url,data,headers)
data: 字典 请求体
requests发送post请求使用requests.post方法,带上请求体,其中请求体需要时字典的形式,传递给data参数接收
在requests中使用代理,需要准备字典形式的代理,传递给proxies参数接收
第三次,试了一下post方法,除了200,什么都没返回,说明和network上显示的一样,只能get方法。
第四次,得到的json数据,想要用load方法去解析json,可惜网页得到的json格式不是正宗的,比如key没有双引号,只能用正则表达式去处理
JSON到字典转化: 》》》dictinfo = json.loads(json_str) 输出dict类型 字典到JSON转化: 》》》jsoninfo = json.dumps(dict)输出str类型 比如: info = {‘name‘ : ‘jay‘, ‘sex‘ : ‘male‘, ‘age‘: 22} jsoninfo = simplejson.dumps(info) print jsoninfo Unicode到字典的转化: 》》》 json.loads() 比如: import json str = ‘{"params":{"id":222,"offset":0},{"nodename":"topic"}‘ params = json.loads(str) print params[‘params‘][‘id‘]
原始json数据
hxbase_json1( { sum:3591, list:[ { Number:‘21‘, StockNameLink:‘stock_bg.aspx?code=002498&date=2016-12-31‘, industry:‘???¹??(002498)‘, stockNumber:‘20.98‘, industryrate:‘76.92‘, Pricelimit:‘B‘, lootingchips:‘10.93‘, Scramble:‘15.00‘, rscramble:‘23.00‘, Strongstock:‘7.01‘, Hstock:‘ <a href="http://www.cninfo.com.cn/finalpage/2017-04-27/1203402047.PDF" target="_blank"><img alt="" src="img/table_btn1.gif"/></a>‘, Wstock:‘<a href="http://stockdata.stock.hexun.com/002498.shtml" target="_blank"><img alt="" src="img/icon_02.gif"/></a>‘, Tstock:‘<img "="" alt="" code="" codetype="" onclick="addIStock(\‘002498\‘,\‘1\‘);" src="img/icon_03.gif"/>‘ }, {Number:‘22‘, StockNameLink:‘stock_bg.aspx?code=002543&date=2016-12-31‘, industry:‘??????(002543)‘, ....} ] })
正则表达式
p1 = re.compile(r‘[{](.*)[}]‘, re.S) #最大匹配
p2 = re.compile(r‘[{](.*?)[}]‘, re.S) #最小匹配
res = re.findall(p1, r.text)
得到的是一个len为1 的list,是最外层{}里面的内容
res = re.findall(p2, res[0])
得到的是一个len为最里层{}数目 的list,是最里层{}里面的内容
第五次,编码问题
outfile = open(filename, ‘w‘, encoding=‘utf-8‘)
?打开的时候指定编码方式,解决
代码
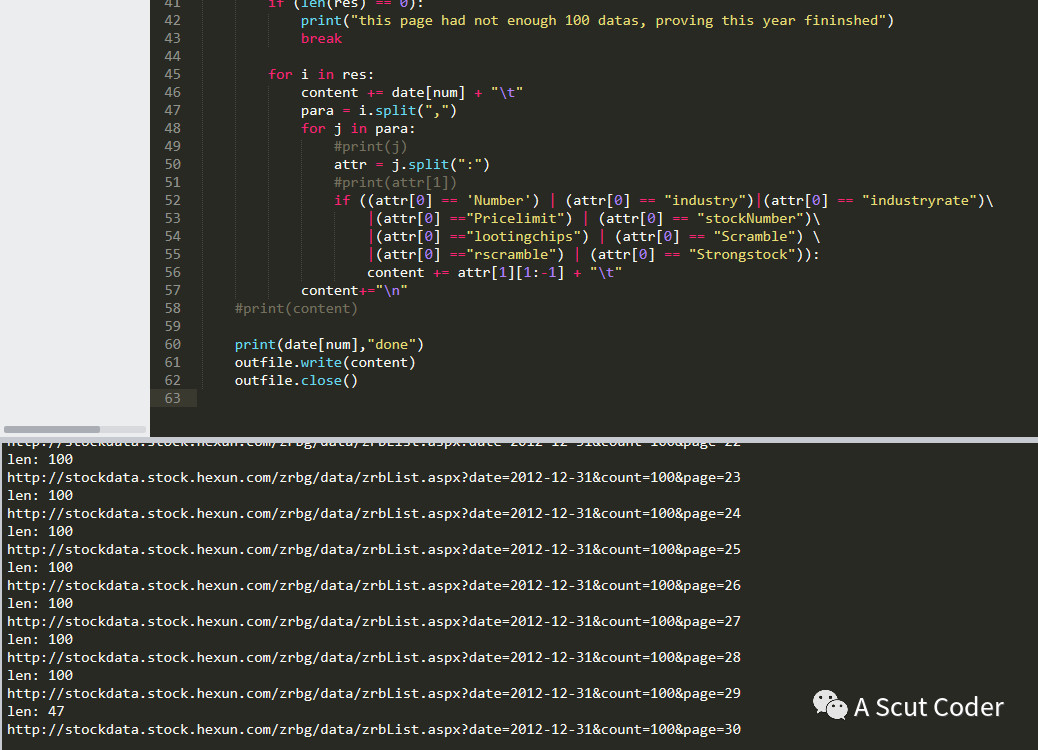
#coding=utf-8 import requests from bs4 import BeautifulSoup import json import re date=["2010","2011","2012","2013","2014","2015","2016","2017","2018"] #url = r‘http://stockdata.stock.hexun.com/zrbg/data/zrbList.aspx?date=2016-12-31&count=20&pname=20&titType=null&page=2‘ firsturl = r‘http://stockdata.stock.hexun.com/zrbg/data/zrbList.aspx?date=‘ dayurl ="-12-31" num = 0 header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36", "Host":"stockdata.stock.hexun.com"} for num in range(2,6): print("start year :",date[num]) filename = ‘D:\\company‘+date[num]+‘.txt‘ print("store file is:", filename) outfile = open(filename, ‘w‘, encoding=‘utf-8‘) pagenum = 1 content = "" for pagenum in range(1,40): url = firsturl + date[num] + dayurl + "&count=100&page=" + str(pagenum) print(url) r = requests.get(url, headers=header) p1 = re.compile(r‘[{](.*)[}]‘, re.S) p2 = re.compile(r‘[{](.*?)[}]‘, re.S) res = re.findall(p1, r.text) # print("len:",len(res)) # print(res) res = re.findall(p2, res[0]) print("len:",len(res)) if (len(res) == 0): print("this page had not enough 100 datas, proving this year fininshed") break for i in res: content += date[num] + "\t" para = i.split(",") for j in para: #print(j) attr = j.split(":") #print(attr[1]) if ((attr[0] == ‘Number‘) | (attr[0] == "industry")|(attr[0] == "industryrate") |(attr[0] =="Pricelimit") | (attr[0] == "stockNumber") |(attr[0] =="lootingchips") | (attr[0] == "Scramble") |(attr[0] =="rscramble") | (attr[0] == "Strongstock")): content += attr[1][1:-1] + "\t" content+="\n" #print(content) print(date[num],"done") outfile.write(content) outfile.close()
以上是关于python爬虫踩坑教程的主要内容,如果未能解决你的问题,请参考以下文章