大数据技术之_19_Spark学习_02_Spark Core 应用解析小结
Posted chenmingjun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术之_19_Spark学习_02_Spark Core 应用解析小结相关的知识,希望对你有一定的参考价值。
1、RDD 全称 弹性分布式数据集 Resilient Distributed Dataset
它就是一个 class。
abstract class RDD[T: ClassTag](
@transient private var _sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging {
继承了 Serializable 和具有 Logging 的特质,为什么要Serializable?答:因为不同的 RDD 之间需要进行转化(序列化:数据转化成二进制,反序列:化二进制转化为数据)。
2、RDD 其实是 spark 为了减少用户对于不同数据结构之间的差异而提供的数据封装,为用户提供了很多数据处理的操作。
3、RDD 三个特点
3.1、不可分,在 RDD 上调用转换算子,会生成一个新的 RDD,不会更改原 RDD 的数据结构。
3.2、可分区,RDD 的数据可以根据配置分成多个分区,每个分区都被一个 Task 任务去处理,可以认为分区数就是并行度。
3.3、弹性:
3.3.1、存储的弹性,RDD 的数据可以在内存和磁盘进行自动切换,对用户透明。
3.3.2、计算的弹性,RDD 的计算之间会有重试机制,避免由于网络等原因导致的任务失败。
3.3.3、容错的弹性,RDD 可以通过血统机制来进行 RDD 的恢复。
3.3.4、分区的弹性,可以根据需求来动态改变 RDD 分区的分区数,也就是动态改变了并行度。
4、Spark 到底做了什么?
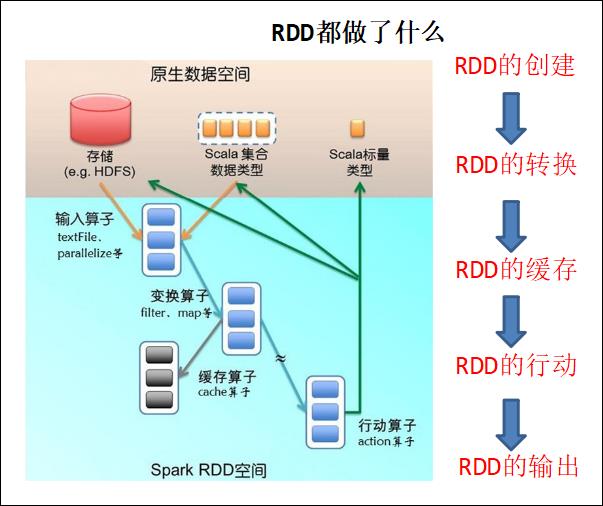
简言之:从外部空间将数据加载到 Spark,对数据进行转换、缓存最后将数据通过行动操作保存到外部空间。
5、RDD 两种处理数据的方式
RDD 有两种处理数据的方式,一种叫转换操作【一个 RDD 调用该方法后返回一个 RDD】,另外一种叫行动操作【一个 RDD 调用该方法后返回一个标量或者直接将数据保存到外部空间】。
6、RDD 是懒执行的,如果没有行动操作出现,所有的转换操作都不会执行。
转换操作:
1、def map[U: ClassTag](f: T => U): RDD[U] 映射,将一种类型的数据转换成为另外一种类型的数据。
2、def filter(f: T => Boolean): RDD[T] 返回满足条件的数据。
3、def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] 将一个数据结构转换成为一个可迭代的数据结构,然后将数据压平。
4、def mapPartitions[U: ClassTag](f: Iterator[T] => Iterator[U], preservesPartitioning: Boolean = false): RDD[U] 对于每一个分区执行一次函数,它的执行效率要比 map 高。
5、def mapPartitionsWithIndex[U: ClassTag](f: (Int, Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false): RDD[U] 类似于 mapPartitions,但 func 带有一个整数参数表示分片的索引值。
6、def sample(withReplacement: Boolean,fraction: Double,seed: Long = Utils.random.nextLong): RDD[T] 对 RDD 进行采样,主要用于观察大数据集的分布情况。
7、def union(other: RDD[T]): RDD[T] 和另外一个 RDD 取并集。
8、def intersection(other: RDD[T]): RDD[T] 和另外一个 RDD 取交集。
9、def distinct(numPartitions: Int) 对原 RDD 进行去重后返回一个新的 RDD。
10、def partitionBy(partitioner: Partitioner): RDD[(K, V)] 对 KV 结构 RDD 进行重新分区。
11、def reduceByKey(func: (V, V) => V): RDD[(K, V)] 返回值 V 的数据类型必须和输入一样。先预聚合再聚集。
12、def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] 将相同 Key 的 value 进行聚集。
13、def combineByKey[C](createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)]
(1) 后面三个函数的逻辑是针对某一个 Key 的聚集来起作用。
(2) createCombiner 每个分区都有,当遇到新 Key 的时候调用,产生一个新的数据结构。
(3) mergeValue 每个分区都有,当遇到旧 Key 的时候调用,将当前数据合并到数据结构中。
(4) mergeCombiners 这个是全局所有,合并所有分区中过来的数据。
14、def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]
是 combineBykey 的简化操作,zeroValue 类似于 createCombiner, seqOp 类似于 mergeValue, combOp 类似于 mergeCombiner。
15、def foldByKey(zeroValue: V, partitioner: Partitioner) (func: (V, V) => V): RDD[(K, V)] 注意:V 的类型不能改变。
16、def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length): RDD[(K, V)] 对 KV 结构 RDD 进行排序(默认升序),K 必须实现 trait Ordering[T],复写 compare 方法,返回一个按照 key 进行排序的 (K,V) 的 RDD。
17、def sortBy[K](f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] sortBy 使用 func 产生的 Key 来做比较。
18、def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] 和另外的 RDD 进行 JOIN。
19、def cogroup[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (Iterable[V], Iterable[W]))] 类似于两个 RDD 分别做 groupByKey 然后再 全JOIN。
20、def cartesian[U: ClassTag](other: RDD[U]): RDD[(T, U)] 笛卡尔积。
21、def pipe(command: String): RDD[String] 对于每个分区,支持使用外部脚本比如 shell、perl 等处理分区内的数据。
22、def coalesce(numPartitions: Int, shuffle: Boolean = false,partitionCoalescer: Option[PartitionCoalescer] = Option.empty)(implicit ord: Ordering[T] = null): RDD[T] 改变分区数。
23、def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] 重新分区,所有数据全部网络混洗。
24、def repartitionAndSortWithinPartitions(partitioner) 在重新分区的过程中会进行排序,如果重新分区后还要进行 sortBy 或者 sorkByKey 操作,那么直接使用该算子。性能比 repartition 要高。
25、def glom(): RDD[Array[T]] 将每一个分区中的所有数据转换为一个 Array 数组,形成新的 RDD。
26、def mapValues[U](f: V => U): RDD[(K, U)] 只对 KV 结构中 value 数据进行映射。value 可以改变类型。
27、def subtract(other: RDD[T]): RDD[T] 求差集
----------------------------------------------------------------------------------------------------------
行动操作:
1、def reduce(f: (T, T) => T): T 规约某个 RDD
2、collect() 将数据返回到 Driver,是以数组的形式返回数据集的所有元素(简单测试用,生产环境中不用)
3、count() 返回 RDD 中的元素个数
4、first() 返回第一个元素
5、take(n) 返回前 n 个元素
6、takeSample(withReplacement, num, [seed]) 采样,返回 Array 数组
7、takeOrdered (n) 返回排序后的前几个元素,如果需要倒序,那么可以利用重写 Ordering 来做
8、aggregate (zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U)
9、fold(zeroValue)(func) aggregate 的简化操作
10、saveAsTextFile(path) 以文本的方式保存到HDFS兼容的文件系统
11、saveAsSequenceFile(path) 以 SequenceFile 形式来存文件
12、saveAsObjectFile(path) 以 ObjectFile 来存文件
13、countByKey() 返回 Map 结构,获取每一个 key 的数量
14、foreach(func) 在数据集上的每一个元素运行 func 函数
7、向 RDD 操作传递函数注意
传递函数的时候需要注意:如果你的 RDD 转换操作中的函数使用到了类的方法或者变量,那么你需要注意该类可能需要能够序列化。即该 class 需要继承 java.io.Serializable 接口,或者可以将属性赋值为本地变量来防止整个对象的传输。
8、RDD的依赖关系
窄依赖(narrow dependency):子的父依赖只有一个,出度1。
宽依赖(wide dependency):子的父依赖有多个,出度大于2。
RDD 之间的前后依赖关系有宽依赖和窄依赖之分,主要通过依赖的不同来划分 Stage(阶段)。
区别:是否要进行 shuffle 阶段(即合并分区的过程)。
9、RDD 的任务切分
Application:一个能够打成 jar 包的 Spark 程序就是一个应用。里面应该有一个 SparkContext。
Job:一个应用中每一个 Action 操作所涉及到的所有转换叫一个 Job。
Stage:一个 Job 根据 RDD 之间的宽窄依赖关系划分为多个 Stage,Stage 之间是根据依赖关系来逐个执行的。
Task: 一个 Stage 运行的时候,RDD 的每一个分区都会被一个 Task 去处理,也可以认为是并行度。
10、RDD 的运行规划
写代码我们都是从前往后写,划分 Stage 是从后往前划分,步骤如下:
(1)首先先把所有代码划分成为一个 Stage,然后该 Stage 入栈。
(2)从最后的代码往前走,如果发现 RDD 之间的依赖关系是宽依赖,那么将宽依赖前面的所有代码划分为第二个 Stage,然后该 Stage 入栈。
(3)根据2规则继续往前走,直到代码开头。
11、RDD 持久化
RDD 持久化:每一个节点都将把计算的分片结果保存在内存中,并在对此 RDD 或衍生出的 RDD 进行的其他动作中重用。(防止重新计算浪费资源,因为 RDD 在没有持久化的时候默认计算的分片结果是不保存的,如果需要那么就要根据血统关系来重新计算。)
持久化也是懒执行的,持久化有两个操作:persist(StorageLevel),persist() 默认把数据以序列化的形式缓存在 jvm 的堆空间中;另外一个是 cache,cache 就相当于 MEMORY_ONLY 的 persist。
使用步骤:
// 设置缓存级别:MEMORY_ONLY, MEMORY_ONLY_SER
data.persist(StorageLevel.DISK_ONLY)
// 清除缓存
data.unpersist
// data.unpersist(blocking=true)
持久化级别按照:存储的位置(磁盘、内存、非堆内存)、是否序列化、存储的份数(1,2)进行划分
12、RDD 检查点机制
检查点也是一种 RDD 的持久化机制,只不过检查点将 RDD 的数据放在非易失存储上,比如 HDFS,存放之后会将 RDD 的依赖关系删除,主要是因为检查点机制认为该 RDD 不会丢失。
如何用呢?步骤如下:
(1)通过 sc.setCheckPointDir("hdfs://hadoop102:9000/checkpoint") 来设置一个 HDFS 兼容的文件系统目录
(2)通过在RDD.checkPoint() 来启用检查点
(3)RDD 创建之初就要启用检查点,否则不成功
注意:整个 checkpoint 的读取是用户透明的(即用户看不到,是后台执行的)。
13、键值对 RDD 的数据分区
hash 分区:对于给定的 key,计算其 hashCode,并除于分区的个数取余,容易造成数据倾斜。
range 分区:采用的是水塘抽样算法,将将一定范围内的数映射到某一个分区内,避免了一个数据倾斜的状态。
主要有 Hash 和 Range 两种,Range 分区通过水塘抽样算法来保证每一个分区的数据都比较均匀。
可以通过继承 Partitoner 来实现自定义的分区器,复写2个方法。
scala 获取分区数的元素:res3.mapPartitionsWithIndex((index, iter) => Iterator(index + "---" + iter.mkString(" , "))).collect
14、RDD 累加器
RDD 累加器:线程安全,不是针对某个节点或者某个 RDD 的,它的对象是整个 Spark,类似于 hadoop 的累加器。
RDD 累加器是提供一个类似于共享变量的东西,能够在 Driver 的数据空间定义,然后在 Executor 的数据空间进行更新,然后在 Driver 的数据空间进行正确访问的机制。
14.1、使用系统默认提供的累加器(没啥用),步骤如下:
(1)申请一个 val blanklines = sc.accumulator(0)
(2)在转换操作中使用累加器要注意,可以回出现重复累加的情况,所以最好是在行动操作中使用。使用的时候不能够访问只能够更新,方法是:blanklines.add()。
(3)在 Driver 程序中去访问,方法是: blanklines.value。
14.2、自定义累加器,主要操作如下:
(1)需要继承 AccumulatorV2 这个虚拟类,然后提供类型参数:1) 增加值的类型参数,2) 输出值的类型参数。然后重写5个方法。
(2)需要创建一个 SparkContext
(3)需要创建一个自定义累加器实例
(4)需要通过 SparkContext 去注册你的累加器, sc.register(accum, "logAccum")
(5)需要在转换或者行动操作中使用累加器。
(6)在Driver中输出累加器的结果。
val conf = new SparkConf().setMaster("local[*]")setAppName("LogAccumulator")
val sc = new SparkContext(conf)
val accum = new LogAccumulator
sc.register(accum, "logAccum")
accum.add(x)
15、广播变量
(1)如果转换操作中使用到了 Driver 程序中定义的变量,如果该变量不是通过广播变量来进行声明的,那么每一个分区都会拷贝该变量一份,会造成大量的网络数据传输。(广播传输,带宽浪费严重!)
(2)如果使用广播变量来声明该共享变量,那么只会在每一个 Executor 中存在一次拷贝。(因为每一个 Executor 中有成千上万个分区!)
(3)广播变量主要用来分发只读的小数据集,比如 300M 左右。
(4)怎么使用广播变量呢?步骤如下:
1. 先声明 val broadcastVar = sc.broadcast(Array(1, 2, 3))
2. 再访问 broadcastVar.value
16、Spark Core 数据读取与存储的主要方式
(1)文本文件的输入输出:textFile 和 saveAsTextFile,注意:在写出 text 文件的时候,每一个 partition 会单独写出,文件系统支持所有和 Hadoop 文件系统兼容的文件系统。
(2)JSON 文件或者 CSV 文件:
这种有格式的文件的输入和输出还是通过文本文件的输入和输出来支持的,Spark Core 没有内置对 JSON 文件和 CSV 文件的解析和反解析功能,这个解析功能是需要用户自己根据需求来定制的。
注意:JSON 文件的读取如果需要多个 partition 来读,那么 JSON 文件一般一行是一个 json。如果你的 JSON 是跨行的,那么需要整体读入所有数据,并整体解析。
(3)Sequence 文件:Spark 有专门用来读取 SequenceFile 文件的接口。可以直接使用 sequenceFile[keyClass, valueClass](path) 进行读取。注意:针对于 HDFS 中的文件 block 数为 1,那么 Spark 设定了最小的读取 partition 数为 2。如果 HDFS 中的文件 block 数为大于 1,比如 block 数为 5,那么 Spark 的读取 partition 数为 5。(因为 Spark 本质上属于内存计算层,它的输入输出很大一部分依赖于 HDFS 文件系统。)
(4)ObjectFile 文件:sc.saveAsObjectFile 输出的是对象的形式
1. 对于 ObjectFile 它的读取和保存使用了读取和保存 SequenceFile 的 API,也最终调用了 hadoop 的 API。
2. ObjectFile 的读取使用 objectFile 进行。
3. ObjectFile 的输出直接使用 saveAsObjectFile 来进行输出。
4. 需要注意的是:在读取 ObjectFile 的时候需要指定对象的类型,而并不是 K-V 的类型。
(5)HadoopAPI 的读取和输入:
读取:newApiHadoopFile 和 newApiHadoopRDD 两个方法,最终都是调用 newApiHadoopRDD 来进行实现。
输出:saveAsNewApiHadoopFile 和 saveAsNewApiHadoopDataset 两个方法,最终都是调用 saveAsNewApiHadoopDataset 这个方法进行实现。
(6)关系型数据库的输入输出:JdbcRDD 里面包括了驱动,数据库用户名/密码
1. 对于关系型数据库的读取使用 JdbcRDD 来进行实现,JdbcRDD 需要依次传入 sparkContext、获取 JDBC Connection 的无参方法、查询数据库的 SQL 语句,id 的下界、id 的上界、分区数、提供解析 ResultSet 的函数。
2. 对于关系型数据库的输出,直接采用 jdbc 执行 insert 语句或者 update 语句进行实现。
以上是关于大数据技术之_19_Spark学习_02_Spark Core 应用解析小结的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术之_19_Spark学习_06_Spark 源码解析小结
大数据技术之_19_Spark学习_05_Spark GraphX 应用解析小结
大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank(
大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
大数据技术之_23_Python核心基础学习_02_ 流程控制语句 + 序列(10.5小时)
大数据技术之_16_Scala学习_11_客户信息管理系统+并发编程模型 Akka+Akka 网络编程-小黄鸡客服案例+Akka 网络编程-Spark Master Worker 进程通讯项目(示例代