阿里靠什么支撑 EB 级计算力?
Posted zhaowei121
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里靠什么支撑 EB 级计算力?相关的知识,希望对你有一定的参考价值。

作者 关涛 阿里云智能事业群 研究员
导读:MaxCompute 是阿里EB级计算平台,经过十年磨砺,它成为阿里巴巴集团数据中台的计算核心和阿里云大数据的基础服务。去年MaxCompute 做了哪些工作,这些工作背后的原因是什么?大数据市场进入普惠+红海的新阶段,如何与生态发展共赢?人工智能进入井喷阶段,如何支持与借力?本文从过去一年的总结,核心技术概览,以及每条技术线路未来展望等几个方面做一个概述。
BigData 概念在上世纪90年代被提出,随 Google 的3篇经典论文(GFS,BigTable,MapReduce)奠基,已经发展了超过10年。这10年中,诞生了包括Google 大数据体系,微软 Cosmos 体系,开源 Hadoop 体系等优秀的系统,这其中也包括阿里云的飞天系统。这些系统一步一步推动业界进入“数字化“和之后的“ AI 化”的时代。
同时,与其他老牌系统相比(如,Linux 等操作系统体系,数据库系统、中间件,很多有超过30年的历史),大数据系统又非常年轻,随着云计算的普惠,正在大规模被应用。海量的需求和迭代推动系统快速发展,有蓬勃的生机。(技术体系的发展,可以通过如下 Hype-Cycle 概述,作者认为,大数据系统的发展进入技术复兴期/Slope of Enlightenment,并开始大规模应用 Plateau of Productivity。)
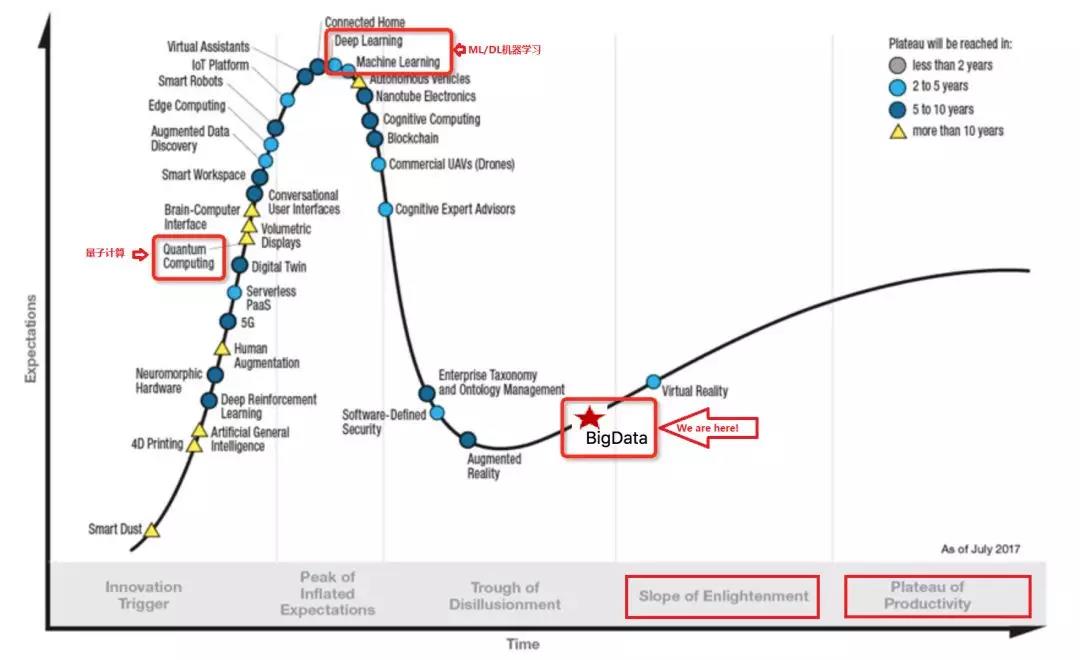
如果说,0到1上线标志一个系统的诞生,在集团内大规模部署标志一个系统的成长,在云上对外大规模服务标志一个系统的成熟。
MaxCompute 这10年已经走向成熟,经过多次升级换代,功能、性能、服务、稳定性已经有一个体系化的基础,成为阿里巴巴集团数据中台的计算核心和阿里云大数据的基础服务。
1. MaxCompute(ODPS)概述
1.1 背景信息:十年之后,回头看什么是大数据
"Big data represents the information assets characterized by such a high volume, velocity and variety torequire specific technology and analytical methods for its transformation intovalue. "
用5个“V”来描述大数据的特点:
- Volume (数据量):数据量非线性增长,包括采集、存储和计算的量都非常大,且增速很快。
- Variety (数据类型):包括结构化和非结构化的数据,特别是最近随音视图兴起,非结构化数据增速更快。
- Velocity(数据存储和计算的增长速度):数据增长速度快,处理速度快,时效性要求高。
- Veracity(信噪比):数据量越大,噪声越多,需要深入挖掘数据来得到结果。
- Value(价值):数据作为一种资产,有 1+1>2 的特点。
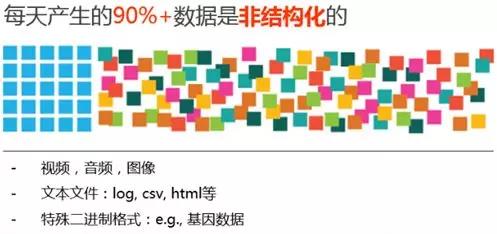
总结下来,大数据具备如下的五个趋势:
- 数据爆炸导致数据和计算量增速很高,很多时候超过业务增速,带来成本压力!
- 数据量变大,但单位数据的价值在下降,深度挖掘势在必行,但反过来要求计算力的进一步提升。
- 非结构化数据处理,成为趋势。
- 时效性,是能完成任务之后,用户的新期待。
- 超大规模的数据和计算,对人工管理是一个挑战。
上述趋势,也会得出了作为大数据平台,我们要发力的方向:计算力、智能化、生态系统。
1.2 MaxCompute 定位
阿里云大数据计算服务( MaxCompute,原名 ODPS )是阿里云提供的一种安全可靠、高效能、低成本、从 GB 到 EB 级别按需弹性伸缩的在线大数据计算服务。MaxCompute 向用户提供了丰富的大数据开发工具、完善的数据导入导出方案以及多种经典的分布式计算模型。能够最快速地解决用户海量数据计算问题,有效降低企业大数据计算平台的总体拥有成本,提高大数据应用开发效率,并保障数据在云计算环境的安全。被广泛地应用于互联网海量数据分析类场景。
MaxCompute 是大数据云数仓的数据汇集点,存储和管理 EB 级数据,支持弹性伸缩的高性能大数据计算服务:它不只是个单一的引擎,而是一个平台。
“不是单一的引擎”体现在,MaxCompute 原生支持 SQL、MR、DAG 编程语义和Graph、PAI 机器学习计算,同时也通过联合计算平台支持任意第三方引擎,如Spark、Flink等 。
“一个平台”体现在,MaxCompute 提供统一高效的数据存储,可靠的元数据服务,跨地域多集群管理,和数据/计算调度能力。
MaxCompute 以其可靠性、高性能、扩展性、安全性和富生态被广泛的用于互联网海量数据分析场景,如海量数据分析与处理、大数据仓库、产品维度报表、机器学习训练、等场景。

1.3 竞品对比与分析
大数据发展到今天,数据仓库市场潜力仍然巨大,更多客户开始选择云数据仓库,CDW仍处于高速增长期。当前互联网公司和传统数仓厂家都有进入领导者地位,竞争激烈,阿里巴巴CDW在全球权威咨询与服务机构Forrester发布的《The Forrester WaveTM: CloudData Warehouse, Q4 2018》报告中位列中国第一,全球第七。
在 CDW 的领导者中,AWS Redshift 高度商业化、商业客户部署规模领先整个市场,GoogleBigQuery 以高性能、高度弹性伸缩获得领先,Oracle 云数仓服务以自动化数仓技术获得领先。
MaxCompute 当前的定位是市场竞争者,目标是成为客户大数据的“航母”级计算引擎,解决客户在物联网、日志分析、人工智能等场景下日益增长的数据规模与计算性能下降、成本上升、复杂度上升、数据安全风险加大之间的矛盾。在此目标定位下,对 MaxCompute 在智能数仓、高可靠性、高自动化、数据安全等方面的能力提出了更高的要求。
2. 2018年MaxCompute技术发展概述
过去的一个财年,MaxCompute 在技术发展上坚持在核心引擎、开放平台、技术新领域等方向的深耕,在业务上继续匠心打造产品,扩大业界影响力。
效率提升
2018年9月云栖大会发布,MaxCompute 在标准测试集 TPC-BB 100TB整体指标较2017年提升一倍以上。

得益于整体效率的提升,在集团内部 MaxCompute 以20%的硬件增长支撑了超过70%的业务增长。
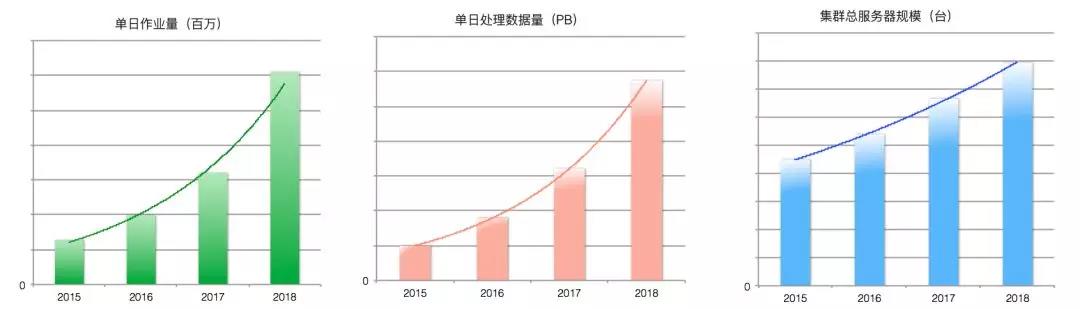
系统开放性和与生态融合
- 联合计算平台 Cupid 逐步成熟,性能与 EMR Spark Benchmark 持平,支持K8S 接口,支持完整的框架安全体系,Spark On MaxCompute 已开始支持云上业务。
- Python 分布式项目 MARS 正式发布,开源两周内收获1200+ Star,填补了国内在 Python 生态上支持大规模分布式科学计算的空白,是竞品 Dask 性能的3倍。
探索新领域
MaxCompute 持续在前沿技术领域投入,保持技术先进性。在下一代引擎方向,如:
- AdaptiveOperators
- Operator Fusion
- ClusteredTable
智能数仓 Auto Datawarehouse 方向上的调研都取得了不错的进展。在渐进计算、Advanced FailChecking and Recovery 、基于 ML的分布式计算平台优化、超大数据量 Query 子图匹配等多个方向上的调研也在进行中。
深度参与和推动全球大数据领域标准化建设
2018年11月,MaxCompute 与 DataWorks/AnalyticDB一起代表阿里云入选 Forrester Wave™ Q4 2018云数据仓库研究报告,在产品能力综合得分上力压微软,排名全球第七,中国第一。
2019年3月,MaxCompute 正式代表 Alibaba 加入了 TPC 委员会推动融入和建立标准。
MaxCompute 持续在开源社区投入。成为全球两大热门计算存储标准化开源体系 ORC 社区的 PMC,MaxCompute 成为近两年贡献代码量最多的贡献者,引导存储标准化;在全球最热门优化器项目 Calcite,拥有一个专委席位,成为国内前两家具备该领域影响力的公司,推动数十个贡献。
3. 核心技术栈
大数据市场进入普惠+红海的新阶段,如何借力井喷阶段中的人工智能,如何与生态发展共赢?
基于横向架构上的核心引擎和系统平台,MaxCompute 在计算力、生态化、智能化3个纵向上着力发展差异化的竞争力。
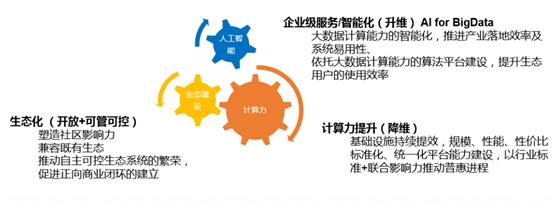
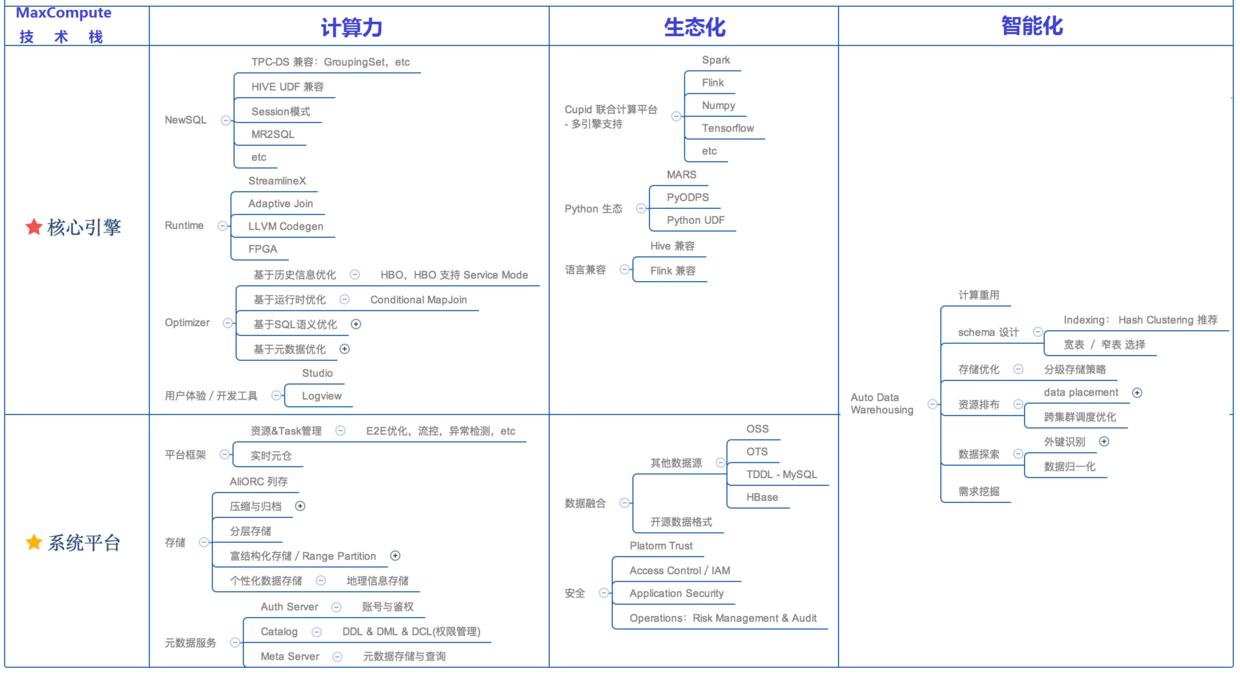
3.1 计算力
首先我们从计算力这个角度出发,介绍一下 MaxCompute 的技术架构。
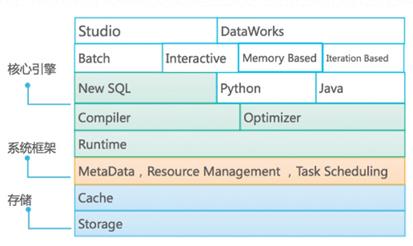
a.核心引擎
支撑 MaxCompute 的计算力的核心模块之一是其 SQL 引擎:在 MaxCompute 的作业中,有90%以上的作业是 SQL 作业,SQL 引擎的能力是 MaxCompute 的核心竞争力之一。
在 MaxCompute 产品框架中,SQL 引擎将用户的 SQL 语句转换成对应的分布式执行计划来执行。SQL 引擎由3个主要模块构成:
- 编译器 Compiler:对 SQL 标准有友好支持,支持100% TPC-DS 语法;并具备强大都错误恢复能力,支持 MaxCompute Studio 等先进应用。
- 运行时 Runtime:基于LLVM优化代码生产,支持列式处理与丰富的关系算符;基于 CPP 的运行时具有更高效率。
- 优化器 Optimizer:支持HBO和基于 Calcite 的 CBO, 通过多种优化手段不断提升 MaxCompute 性能。
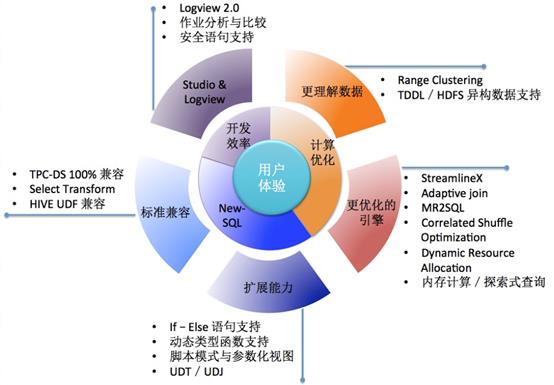
图中部分功能只在阿里集团内部发布,云上版本会陆续发布上线
MaxComputeSQL 引擎当前的发展,以提升用户体验为核心目标,在 SQL 语言能力、引擎优化等多个方向上兼顾发力,建立技术优势,在 SQL 语言能力方面, 新一代大数据语言 NewSQL 做到了 Declarative 语言和 Imperative 语言的融合,进一步提升语言兼容性,目前已100% 支持 TPC-DS 语法。过去一年中,MaxCompute 新增了对 GroupingSets,If-Else 分支语句,动态类型函数,等方面的支持。
b.存储
MaxCompute 不仅仅是一个计算平台,也承担着大数据的存储。阿里巴巴集团99%的大数据存储都基于 MaxCompute,提高数据存储效率、稳定性、可用性,也是MaxCompute一直努力的目标。
MaxCompute 存储层处于 MaxCompute Tasks 和底层盘古分布式文件系统之间,提供一个统一的逻辑数据模型给各种各样的计算任务。MaxCompute 的存储格式演化,从最早的行存格式 CFile1,到第一个列存储格式 CFile2,到第三代存储格式。支持更复杂的编码方式,异步预读等功能,进一步提升效能。在存储和计算2个方面都带来了效能的提升。存储成本方面,在阿里巴巴集团内通过 新一代的列存格式节省约8%存储空间,直接降低约1亿成本;在计算效率上,过去的一个财年中发布的每个版本之间都实现了20%的提升。目前在集团内大规模落地的过程中。
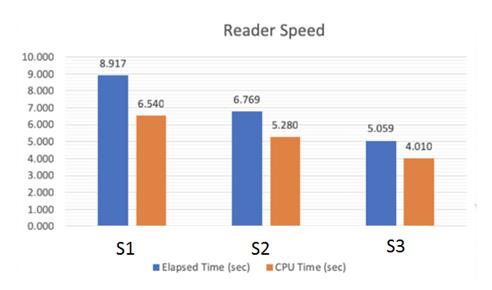
在归档以及压缩方面,MaxCompute 支持 ZSTD 压缩格式,以及压缩策略,用户可以在 Normal,High 和 Extreme 三种 Stategy 里面选择。更高的压缩级别,带来更高效的存储,但也意味着更高的读写 CPU 代价。
2018年, MaxCompute 陆续推出了 Hash Clustering 和 Range Clustering 支持富结构化数据,并持续的进行了深度的优化,例如增加了 ShuffleRemove,Clustering Pruning 等优化。从线上试用数据,以及大量的 ATA 用户实践案例也可以看出,Clustering 的收益也获得了用户的认可。
c.系统框架
资源与任务管理:MaxCompute 框架为 ODPS 上面各种类型的计算引擎提供稳定便捷的作业接入管理接口,管理着 ODPS 各种类型 Task 的生命周期。过去一年对短作业查询的持续优化,缩短 e2e 时间,加强对异常作业(OOM)的自动检测与隔离处理,全面打开服务级别流控,限制作业异常提交流量,为服务整体稳定性保驾护航。
MaxCompute 存储着海量的数据,也产生了丰富的数据元数据。在离线元仓统计T+1的情况下,用户至少需要一天后才能做事后的数据风险审计,现实场景下用户希望更早风险控制,将数据访问事件和项目空间授权事件通过 CUPID 平台实时推送到用户 DataHub 订阅,用户可以通过消费 DataHub 实时获取项目空间表、volume数据被谁访问等。
元数据管理:元数据服务支撑了 MaxCompute 各个计算引擎及框架的运行。每天运行在 MaxCompute 的作业,都依赖元数据服务完成 DDL,DML 以及授权及鉴权的操作。元数据服务保障了作业的稳定性和吞吐率,保障了数据的完整性和数据访问的安全性。元数据服务包含了三个核心模块:
- Catalog :完成DDL,DML及DCL(权限管理)的业务逻辑,Catalog保障MaxCompute作业的ACID特性。
- MetaServer:完成元数据的高可用存储和查询能力。
- AuthServer:是高性能和高QPS的鉴权服务,完成对 MaxCompute 的所有请求的鉴权,保障数据访问安全。
元数据服务经过了模块化和服务化后,对核心事务管理引擎做了多次技术升级,通过数据目录多版本,元数据存储重构等改造升级,保障了数据操作的原子性和强一致,并提高了作业提交的隔离能力,并保障了线上作业的稳定性。
在数据安全越来越重要的今天,元数据服务和阿里巴巴集团安全部合作,权限系统升级到了2.0。核心改进包括:
- MAC(强制安全控制)及安全策略管理:让项目空间管理员能更加灵活地控制用户对列级别敏感数据的访问,强制访问控制机制(MAC)独立于自主访问控制机制(DAC)。
- 数据分类分级:新增数据的标签能力,支持对数据做隐私类数据打标。
- 精细权限管理:将ACL的管控能力拓展到了 Package 内的表和资源,实现字段级的权限的精细化管理。
系统安全:系统安全方面,MaxCompute 通过综合运用计算虚拟化和网络虚拟化技术,为云上多租户各自的用户自定义代码逻辑提供了安全而且完善的计算和网络隔离环境。
SQL UDF(python udf 和 java udf),CUPID联合计算平台(Sparks/Mars等),PAI tensorflow 等计算形态都基于这套统一的基础隔离系统构建上层计算引擎。
MaxCompute 还通过提供原生的存储加密能力,抵御非授权访问存储设备的数据泄露风险。MaxCompute 内置的存储加密能力,可以基于KMS云服务支持用户自定义秘钥(BYOK)以及AES256加密算法,并计划提供符合国密合规要求的SM系列加密算法支持。
结合MaxCompute元仓(MetaData)提供的安全审计能力和元数据管理(MetaService)提供的安全授权鉴权能力,以及数据安全生态中安全卫士和数据保护伞等安全产品,就构成了 MaxCompute安全栈完整大图。
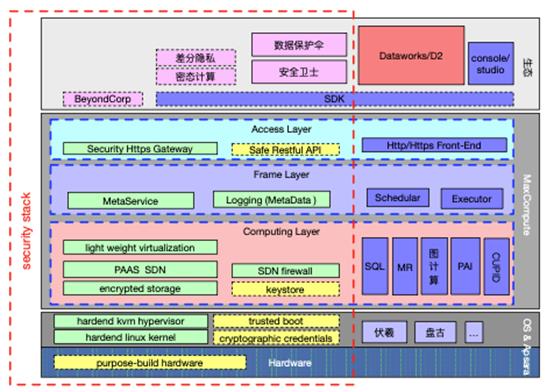
3.2 生态化
作为一个大规模数据计算平台,MaxCompute 拥有来自各类场景的EB级数据,需要快速满足各类业务发展的需要。在真实的用户场景中,很少有用户只用到一套系统:用户会有多份数据,或者使用多种引擎。联合计算融合不同的数据,丰富 MaxCompute 的数据处理生态,打破数据孤岛, 打通阿里云核心计算平台与阿里云各个重要存储服务之间的数据链路。联合计算也融合不同的引擎,提供多种计算模式,支持开源生态。开源能带来丰富和灵活的技术以赋能业务,通过兼容开源API对接开源生态。另一方面,在开源过程中我们需要解决最小化引入开源技术成本及打通数据、适配开源接口等问题。
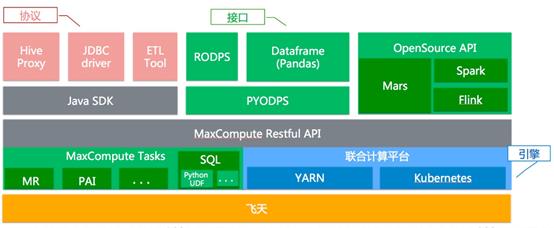
a.Cupid 联合计算平台
联合计算平台 Cupid 使一个平台能够支持 Spark、Flink、Tensorflow、Numpy、ElasticSearch 等多种异构引擎, 在一份数据上做计算。在数据统一、资源统一的基础上,提供标准化的接口,将不同的引擎融合在一起做联合计算。
Cupid 的工作原理是通过将 MaxCompute 所依赖的 Fuxi 、Pangu 等飞天组间接口适配成开源领域常见的 Yarn、HDFS 接口,使得开源引擎可以顺利执行。现在,Cupid 新增支持了 Kubernetes 接口,使得联合计算平台更加开放。
案例:Spark OnMaxCompute
Spark 是联合计算平台第一个支持的开源引擎。基于 Cupid 的 Spark on MaxCompute 实现了与 MaxCompute 数据/元数据的完美集成;遵循 MaxCompute 多租户权限及安全体系;与Dataworks、PAI平台集成;支持 Spark Streaming,Mllib, GraphX,Spark SQL,交互式等完整 Spark生态;支持动态资源伸缩等。
b.多源异构数据的互联互通
随着大数据业务的不断扩展,新的数据使用场景在不断产生,用户也期望把所有数据放到一起计算,从而能取得 1+1 > 2 这样更好的结果。
MaxCompute 提出了联合计算,将计算下推,联动其他系统:将一个作业在多套系统联动,利用起各个系统可行的优化,做最优的决策,实现数据之间的联动和打通。
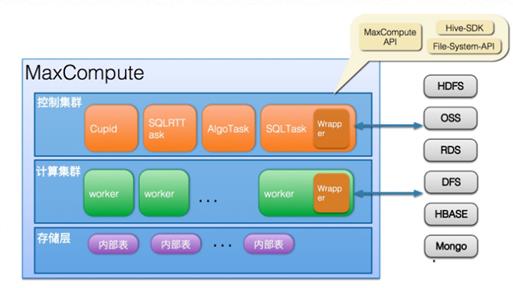
图为MaxCompute集团内和专有云能力,公共云已实现与OSS、OTS的数据互通
MaxCompute 通过异构数据支持来提供与各种数据的联通,这里的“各种数据”是两个维度上的:
- 多样的数据存储介质(外部数据源),插件式的框架可以对接多种数据存储介质。当前支持的外部数据源有:
- OSS
- TableStore(OTS)
- TDDL
- Volume
- 多样的数据存储格式:开源的数据格式支持,如 ORC、Parquet 等;半结构化数据,如包括 CSV、Json等隐含一定schema 的文本文件;完全无结构数据,如对OSS上的文本,音频、图像及其他开源格式的数据进行计算。
基于MaxCompute 异构数据支持,用户通过一条简单的 DDL 语句即可在 MaxCompute 上创建一张EXTERNAL TABLE(外表),建立 MaxCompute 表与外部数据源的关联,提供各种数据的接入和输出能力。
创建好的外表在大部分场景中可以像普通的 MaxCompute 表一样使用,充分利用 MaxCompute 的强大计算力和数据集成、作业调度等功能。MaxCompute 外表支持不同数据源之间的 Join,支持数据融合分析,从而帮助您获得通过查询独立的数据孤岛无法获得的独特见解。从而MaxCompute 可以把数据查询从数据仓库扩展到EB级的数据湖(如OSS),快速分析任何规模的数据,没有MaxCompute存储成本,无需加载或 ETL。
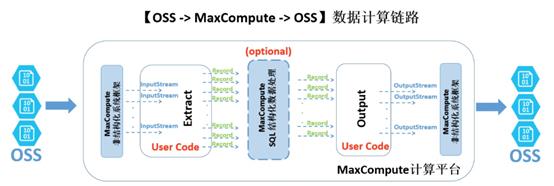
异构数据支持是MaxCompute 2.0升级中的一项重大更新,意在丰富 MaxCompute 的数据处理生态,打破数据孤岛,打通阿里云核心计算平台与阿里云各个重要存储服务之间的数据链路。
c.Python 生态和 MARS科学计算引擎
MaxCompute 的开源生态体系中,对 Python 的支持主要包括 PyODPS、Python UDF、和MARS。
PyODPS 一方面是 MaxCompute 的 PythonSDK,同时也提供 DataFrame 框架,提供类似 pandas 的语法,能利用 MaxCompute 强大的处理能力来处理超大规模数据。基于 MaxCompute 丰富的用户自定义函数(UDF)支持,用户可以在 ODPS SQL 中编写 Python UDF 来扩展 ODPS SQL。 MARS 则是为了赋能 MaxCompute 科学计算,全新开发的基于矩阵的统一计算框架。使用 Mars 进行科学计算,不仅能大幅度减少分布式科学计算代码编写难度,在性能上也有大幅提升。
3.3 智能化
随着大数据的发展,我们在几年前就开始面对数据/作业爆发式增长的趋势。面对百万计的作业和表,如何做管理呢?MaxCompute 通过对历史作业特征的学习、基于对数据和作业的深刻理解,让 MaxCompute 上的业务一定程度实现自适应调整,让算法和系统帮助用户自动、透明、高效地进行数仓管理和重构优化工作,实现更好地理解数据,实现数据智能排布和作业全球调度,做到大数据处理领域的“自动驾驶”,也就是我们所说的Auto DataWarehousing。
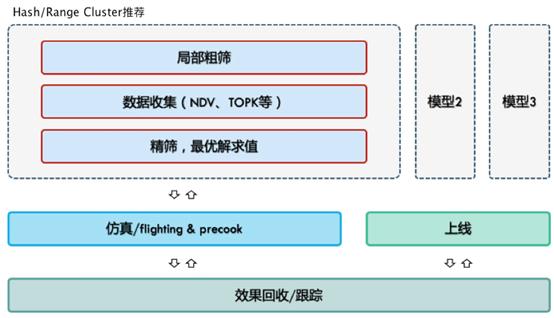
Auto Data Warehousing 在线上真实的业务中,到底能做什么呢?我们以Hash Clustering 的自动推荐来小试牛刀。Hash Clustering 经过一年多的发展,功能不断完善,但对用户来说,最难的问题仍然在于,给哪些表建立怎样的 Clustering 策略是最佳的方案?
MaxCompute 基于 Auto Data Warehousing,来实现为用户推荐如何使用 HashClustering,回答如何选择 Table、如何设置Cluteringkey 和分桶数等问题,让用户在海量数据、海量作业、快速变化的业务场景下,充分利用平台功能。
4. 商业化历程
从2009年云梯到 ODPS,再到 MaxCompute,MaxCompute(ODPS) 这个大数据平台已经发展了十年。回顾 MaxCompute 的发展,首先从云梯到完成登月,成为了一个统一的大数据平台。
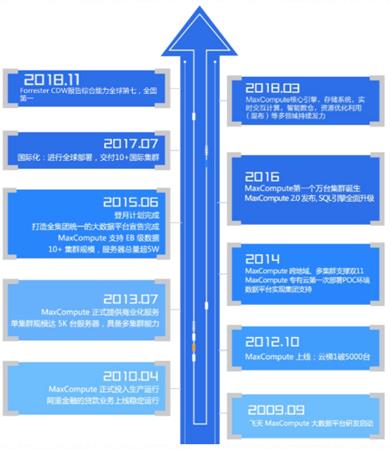
2014年,MaxCompute 开始商业化的历程,走出集团、向公共云和专有云输出,直面中国、乃至全球的用户。面对挑战,MaxCompute 坚持产品核心能力的增强,以及差异化能力的打造, 赢得了客户的选择。回顾上云历程,公共云的第一个节点华东2上海在2014(13年)年7月开服,经过4年多发展,MaxCompute 已在全球部署18个Region,为云上过万家用户提供大数据计算服务,客户已覆盖了新零售、传媒、社交、互联网金融、健康、教育等多个行业。专有云的起点则从2014年8月第一套POC环境部署开始,发展至今专有云总机器规模已超过10000台;输出项目150+套,客户涵盖城市大脑,大安全,税务,等多个重点行业。
今天,MaxCompute 在全球有超过十万的服务器,通过统一的作业调度系统和统一的元数据管理,这十万多台服务器就像一台计算机,为全球用户提供提供包括批计算、流计算、内存计算、机器学习、迭代等一系列计算能力。这一整套计算平台成为了阿里巴巴经济体,以及阿里云背后计算力的强有力支撑。MaxCompute 作为一个完整的大数据平台,将不断以技术驱动平台和产品化发展,让企业和社会能够拥有充沛的计算能力,持续快速进化,驱动数字中国。
本文作者:晋恒
本文为云栖社区原创内容,未经允许不得转载。
以上是关于阿里靠什么支撑 EB 级计算力?的主要内容,如果未能解决你的问题,请参考以下文章