Hadoop Mapreduce中shuffle 详解
Posted pickknow
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop Mapreduce中shuffle 详解相关的知识,希望对你有一定的参考价值。
MapReduce 里面的shuffle:描述者数据从map task 输出到reduce task 输入的这段过程
Shuffle 过程:
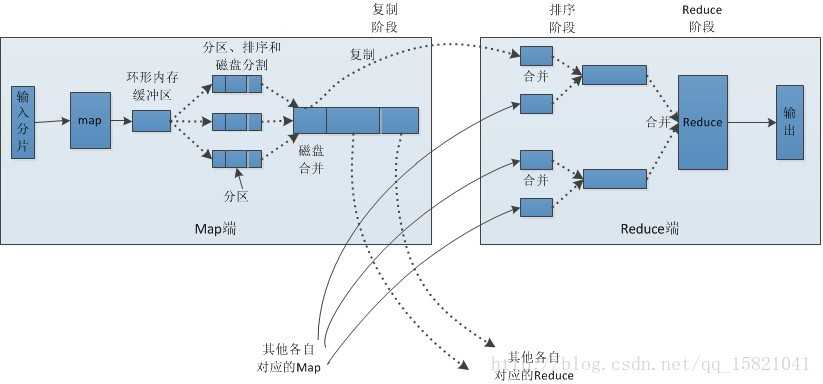
首先,map 输出的<key,value > 会放在内存中,内存有一定的大小,超过之后,会将内存里的东西溢写(spill) 到磁盘(disk)中 。在从内存溢写到磁盘的过程中,会有两个操作:分区(parttition),排序(sort)。map结束之后,磁盘中会有很多文件 。
有很多小文件,需要将文件进行文件的合并,并且排序。map 中的一些map任务可能结束....
合并的大文件,存在map task 运行的本地磁盘,reduce task 会去map task 运行机器上拷贝要处理的数据,多个reduce task 拷贝的数据,也得进行merge,并且排序。然后进行分组(将相同的key 的value 放在一起),然后调用reduce 方法。
map输出的<key,value> 和 reduce 输入的<key,value> 的数据类型一致
综上所述:
分区 partition
排序 sort
copy 用户无法干涉
分组 group
压缩 compress 可设置
combiner
以上是关于Hadoop Mapreduce中shuffle 详解的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop学习之路(二十三)MapReduce中的shuffle详解
Hadoop从入门到精通33:MapReduce核心原理之Shuffle过程分析
Big Data - Hadoop - MapReduce通过腾讯shuffle部署对shuffle过程进行详解