初始scrapy,简单项目创建和CSS选择器,xpath选择器
Posted angle6-liu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初始scrapy,简单项目创建和CSS选择器,xpath选择器相关的知识,希望对你有一定的参考价值。
一 安装
#Linux: pip3 install scrapy #Windows: a. pip3 install wheel b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted c. 进入下载目录,执行 pip3 install Twisted?17.1.0?cp35?cp35m?win_amd64.whl d. pip3 install pywin32 e. pip3 install scrapy
二 实验要求
目标网站: http://quotes.toscrape.com/tag/humor/
任务:保存网页信息到本地
二 创建爬虫项目
scrapy startproject tutorial
生成项目的结构
tutorial/ scrapy.cfg # 部署配置文件 tutorial/ # 项目的Python模块,你将从这里导入你的代码 __init__.py items.py # 项目项目定义文件,用于规定存储的字段 middlewares.py # 项目中间件文件 pipelines.py # 项目持久化存储文件 settings.py # 项目配置文件 spiders/ # 这里可以创建爬虫文件
. # 若干个爬虫文件
.
.
__init__.py
三 创建爬虫文件
scrapy genspider QuotesSpider #爬虫文件名为QuotesSpider
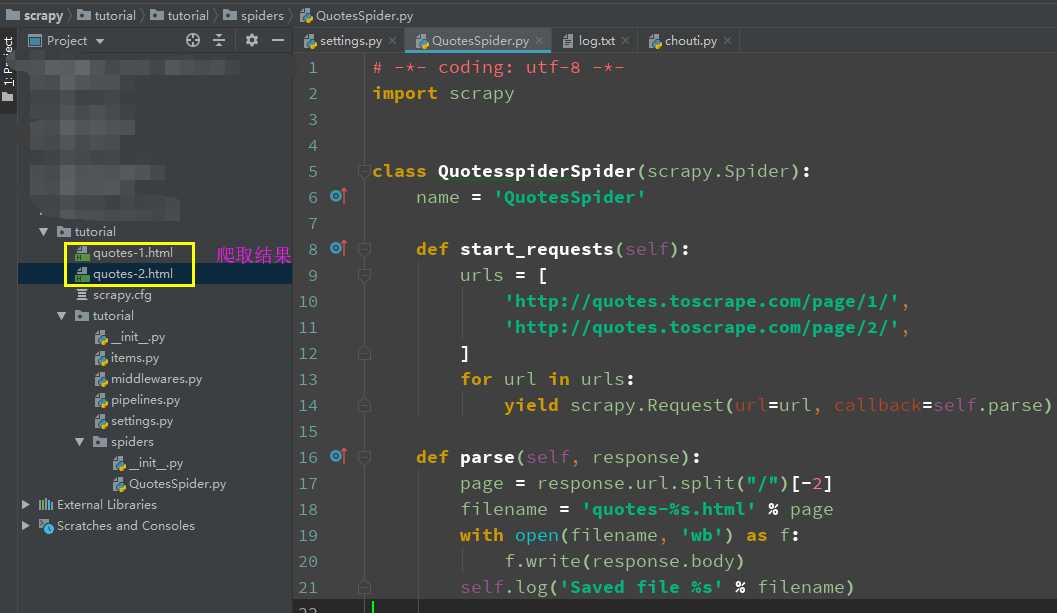
使用pycharm打开项目,修改QuotesSpider .py 文件改为
# -*- coding: utf-8 -*- import scrapy class QuotesspiderSpider(scrapy.Spider): name = ‘QuotesSpider‘ #爬虫名字 def start_requests(self): #待爬取的url列表 urls = [ ‘http://quotes.toscrape.com/page/1/‘, ‘http://quotes.toscrape.com/page/2/‘, ] for url in urls: #提交请求,并制定回调函数为self.parse yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): ‘解析页面,response是网页返回的数据(源码)‘ page = response.url.split("/")[-2] filename = ‘quotes-%s.html‘ % page # 网页保存 with open(filename, ‘wb‘) as f: f.write(response.body) self.log(‘Saved file %s‘ % filename)
其中
name: 爬虫名字,项目中名字是唯一的.
start_requests():必须返回一个可迭代的对象.爬取起始url网页.指定回调函数.
parse():解析页面数据,
四 启动爬虫文件
scrapy crawl QuotesSpider
效果展示
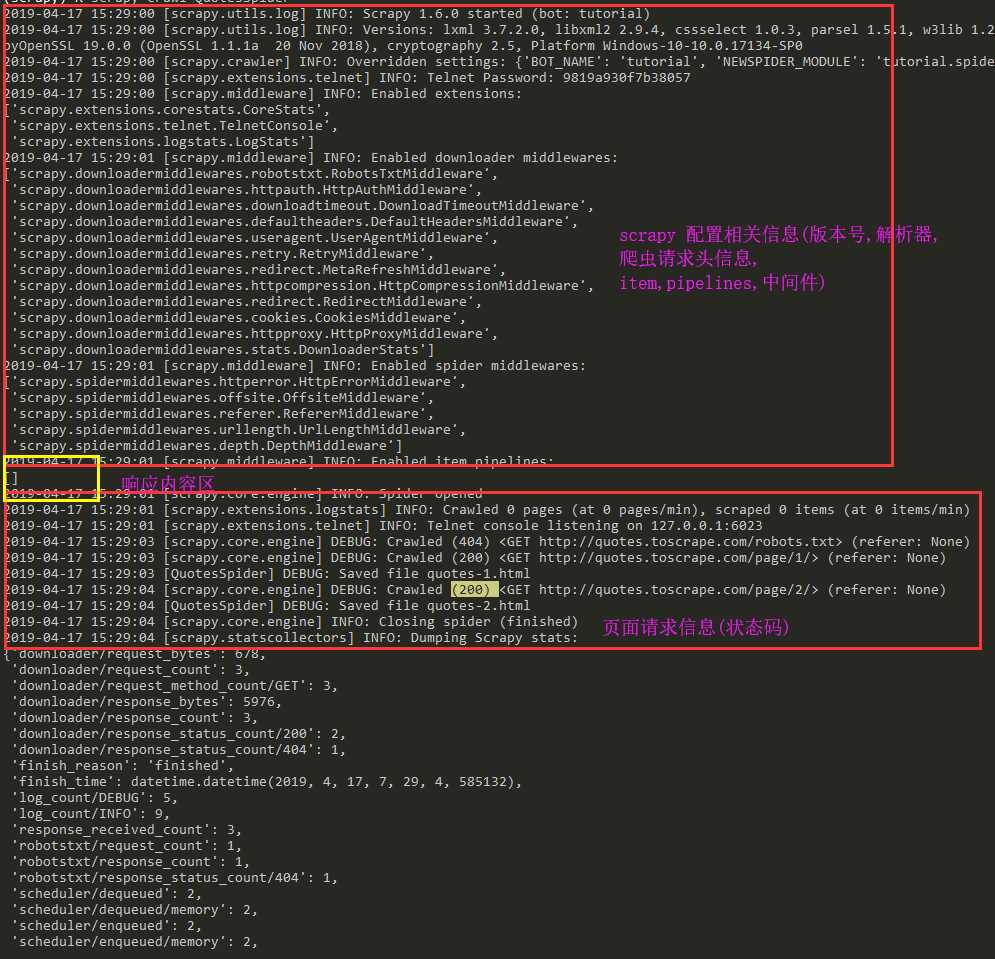
五 项目执行流程
Scrapy 执行的时候,首先会调用start_requests方法,然后执行方法中的scrapy.Request方法获取url对应网站的数据,得到Response相应对象,转而把Response对象交给Scrapy.Request的回调函数,在回调函数中解析response对象中的网页源码数据,保存到当前目录下.
六 Scrapy shell
使用Scrapy提取数据的最佳方法时使用scrapy shell 常识选择器.
scrapy shell "http://quotes.toscrape.com/page/1/"
执行此命令后可以进入交互模式(如下):
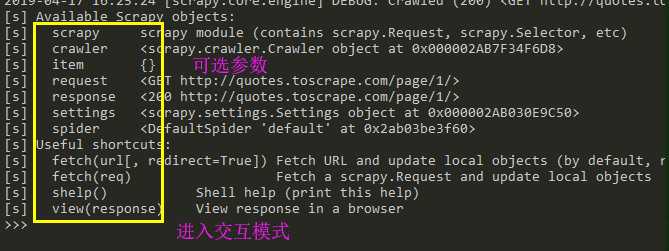
解析可选参数
[s] Available Scrapy objects:
[s] scrapy # 可以使用scrapy中的模块,如contains scrapy.Request, scrapy.Selector...
[s] crawler # 当前爬虫对象
[s] item {}
[s] request #当前的请求页面
[s] response #当前请求的响应
[s] settings # 当前的配置文件
[s] spider <DefaultSpider ‘default‘ at 0x7fa91c8af990>
[s] Useful shortcuts: [s] shelp() Shell help (print this help) [s] fetch(req_or_url) # 爬取url或者request获取新的response [s] view(response) # 使用网页打开response
使用栗子:

>>> response.css(‘title::text‘).getall() #获取标题中提取文本 [‘Quotes to Scrape‘]
七 scrapy 中的数据解析
Scrapy带有自己的提取数据机制。它们被称为选择器,因为它们“选择”由XPath或CSS表达式指定的HTML文档的某些部分。
测试代码
‘‘‘
<html>
<head>
<base href=‘http://example.com/‘ />
<title>Example website</title>
</head>
<body>
<div id=‘images‘>
<a href=‘image1.html‘>Name: My image 1 <br /><img src=‘image1_thumb.jpg‘ /></a>
<a href=‘image2.html‘>Name: My image 2 <br /><img src=‘image2_thumb.jpg‘ /></a>
<a href=‘image3.html‘>Name: My image 3 <br /><img src=‘image3_thumb.jpg‘ /></a>
<a href=‘image4.html‘>Name: My image 4 <br /><img src=‘image4_thumb.jpg‘ /></a>
<a href=‘image5.html‘>Name: My image 5 <br /><img src=‘image5_thumb.jpg‘ /></a>
</div>
</body>
</html>
‘‘‘
1 css解析器
>>> response.css(‘title‘).getall() #获取所有的匹配结果 [‘<title>Quotes to Scrape</title>‘]
>>> response.css(‘title::text‘)[0].get() #获取第一个匹配结果 ‘Quotes to Scrape‘
使用正则匹配结果
>>> response.css(‘title::text‘).re(r‘Quotes.*‘) [‘Quotes to Scrape‘] >>> response.css(‘title::text‘).re(r‘Q\\w+‘) [‘Quotes‘] >>> response.css(‘title::text‘).re(r‘(\\w+) to (\\w+)‘) [‘Quotes‘, ‘Scrape‘]
2 xpath 解析数据
>>> response.xpath(‘//title‘) [<Selector xpath=‘//title‘ data=‘<title>Quotes to Scrape</title>‘>] >>> response.xpath(‘//title/text()‘).get() ‘Quotes to Scrape‘
注意:scrapy使用xpath解析出来的数据返回的是select对象,一般提取数据信息的方法如下
# 获取第一个元素 author = div.xpath(‘./div[1]/a[2]/h2/text()‘)[0].extract()
# 获取第一个元素 author = div.xpath(‘./div[1]/a[2]/h2/text()‘).extract_first() #获取所有元素,结果为一个列表 content = div.xpath(‘./a[1]/div/span//text()‘).extract()
现在我们将获得基本URL和一些图像链接:
>>> response.xpath(‘//base/@href‘).get() ‘http://example.com/‘ >>> response.css(‘base::attr(href)‘).get() ‘http://example.com/‘ >>> response.css(‘base‘).attrib[‘href‘] ‘http://example.com/‘ >>> response.xpath(‘//a[contains(@href, "image")]/@href‘).getall() [‘image1.html‘, ‘image2.html‘, ‘image3.html‘, ‘image4.html‘, ‘image5.html‘] >>> response.css(‘a[href*=image]::attr(href)‘).getall() [‘image1.html‘, ‘image2.html‘, ‘image3.html‘, ‘image4.html‘, ‘image5.html‘] >>> response.xpath(‘//a[contains(@href, "image")]/img/@src‘).getall() [‘image1_thumb.jpg‘, ‘image2_thumb.jpg‘, ‘image3_thumb.jpg‘, ‘image4_thumb.jpg‘, ‘image5_thumb.jpg‘] >>> response.css(‘a[href*=image] img::attr(src)‘).getall() [‘image1_thumb.jpg‘, ‘image2_thumb.jpg‘, ‘image3_thumb.jpg‘, ‘image4_thumb.jpg‘, ‘image5_thumb.jpg‘]
最后归纳:
获取元素中的文本推荐使用
- get( ) #获取第一个值
- getall( ) #获取所有,返回列表
八 调整代码进行所有页面数据爬取
# -*- coding: utf-8 -*- import scrapy class QuotesspiderSpider(scrapy.Spider): name = ‘QuotesSpider‘ start_urls = [ ‘http://quotes.toscrape.com/page/1/‘, ] def parse(self, response): for quote in response.css(‘div.quote‘): yield { ‘text‘: quote.css(‘span.text::text‘).get(), ‘author‘: quote.css(‘small.author::text‘).get(), ‘tags‘: quote.css(‘div.tags a.tag::text‘).getall(), } #获取下一页的url next_page = response.css(‘li.next a::attr(href)‘).get() if next_page is not None: #urljoin用于构建下一页的绝对路径url next_page = response.urljoin(next_page) yield scrapy.Request(next_page, callback=self.parse)
使用css选择器获取下一页的url(相对路径),在使用response.urljoin()获取绝对路径,再次回调self.parse()实现所有页面数据爬取.
九 scrapy 文件输出参数
scrapy crawl quotes -o quotes-humor.json
‘‘‘
- o 把详情页返回结果,输入到文件
‘‘‘
以上是关于初始scrapy,简单项目创建和CSS选择器,xpath选择器的主要内容,如果未能解决你的问题,请参考以下文章