Kafka设计原理
Posted ylxn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka设计原理相关的知识,希望对你有一定的参考价值。
1、持久性
kafka使用文件存储消息,这就直接决定kafka在性能上严重依赖文件系统的本身特性。且无论任何OS下,对文件系统本身的优化几乎没有可能。因为kafka是对日志进行append操作,因此磁盘检索的开支是较小的;同时为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阈值再flush到磁盘,这样减少了磁盘IO调用的次数。
2、性能
需要考虑的影响性能点很多,除磁盘IO之外,我们还需要考虑网络IO,这直接关系到kafka的吞吐量问题,kafka并没有提供太多高超的技巧,对于producer端,可以将消息buffer起来,当消息的条数达到一定阀值的时候,批量发送给broker,对于consumer端也一样,批量fetch多条消息,不过消息量的大小可以通过配置文件来指定。对于kafka broker端,似乎有个sendfile系统调用可以潜在的提升网络IO性能:将文件的数据映射到系统内存中,socket直接读取相应的内存区域即可,而无需进程再次copy和交换,其实对于producer/consumer/broker三者而言,CPU的开支应该都不大,因此启用消息压缩机制是一个良好的策略。压缩需要消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑,可以将任何在网络上传输的消息都经过压缩。kafka支持gzip/snappy等各种压缩方式。
3、生产者
负载均衡:producer将会和Topic下所有partition leader保持socket连接;消息由producer直接通过socket发送到broker,中间不会经过任何“路由层”,事实上,消息被路由到哪个partition上,由producer决定。比如可以采用“random”“key-hash”“轮询”等,如果一个topic中有多个partitions,那么producer端实现“消息均衡分发”是必要的。
其中partition leader的位置(host:port)注册在zookeeper中,producer作为zookeeper client,已经注册了watch用来监听partition leader的变更时间。
异步发送:将多的消息暂且在客户端buffer起来,并将它们批量的发送到broker,小数据IO太多,会拖慢整体的网络延迟,批量延迟发送事实上提升了网络效率。不过这也有一定的隐患,比如说当producer失效时,那些尚未发送的消息将会丢失
4、消费者
consumer端向broker发送“fetch”请求,并告知其获取消息的offset;此后consumer将会获得一定条数的消息;consumer端也可以重置offset来重新消费消息。
在JMS实现中,TOPIC模型基于push方式,即broker将消息推送给consumer端,不过在kafka中,采用了pull方式,即consumer在和broker建立连接之后,主动去pull或者说fetch消息。这种模式有些优点,首先consumer端可以根据自己的消费能力适时的去fetch消息并处理,且可以控制消息消费的进度(offset);此外,消费者可以良好的控制消息的数量,batch fetch。
其他JMS实现,消息消费的位置是由prodiver保留,以便避免重复发送消息或者将没有消费成功的消息重发等,同时还要控制消息的状态,这就要求JMS broker需要太多额外的工作。在kafka中,partition中的消息只有一个consumer在消费,且不存在消息状态的控制,也没有复杂的消息确认机制。当消息被consumer接受之后,consumer可以在本地保存最后消息的offset,并间歇性的向zookeeper注册offset。
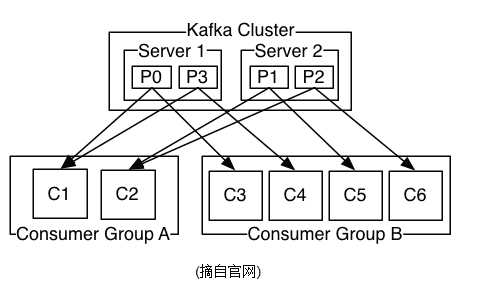
5、消息传送机制
对于JMS实现,消息传输担保非常直接:有且只有一次(exextly once)。在kafka中稍有不同。
- at most once:最多一次。这个和JMS中“非持久化”消息类似,发送一次,无论成败,将不会重发
- at least one: 如果offset未能成功同步到zookeeper,那么消息有可能再次被fetch
- exactly once:消息只会发送一次
6、复制备份
kafka将每个partition数据复制到多个server上,任何一个partition有一个leader和多个follower(可以没有);备份的个数可以通过broker配置文件来设定.leader处理所有的read-write请求,follower需要和leader保持同步.Follower和consumer一样,消费消息并保存在本地日志中;leader负责跟踪所有的follower状态,如果follower"落后"太多或者失效,leader将会把它从replicas同步列表中删除.当所有的follower都将一条消息保存成功,此消息才被认为是"committed",那么此时consumer才能消费它.即使只有一个replicas实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper集群存活即可.(不同于其他分布式存储,比如hbase需要"多数派"存活才行)
以上是关于Kafka设计原理的主要内容,如果未能解决你的问题,请参考以下文章