流量整形,延迟以及ACK丢失对TCP发送时序的影响
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了流量整形,延迟以及ACK丢失对TCP发送时序的影响相关的知识,希望对你有一定的参考价值。
TCP是一个连续不断的涓涓细流或者滚滚长江,但这只是理想情况!经过诸多中间网络设备,最终一个TCP流到达接收端的时候,将可能不再保持一个流的形式,而变成了一阵阵的突发...这些突发产生的ACK反过来反馈到发送端,进而对发送端的发送时序产生影响,也就是说对发送端的数据流进行整形,这真是一个典型的涡轮增压反馈系统,根本不是通常认为的那样不可控或者说另一个极端,仅仅是端到端!想驾驭它其实不是那么难,如果有人说仅仅可以靠感觉就可以驾驭它,倒不如说它本来就是1+1=2那般有条有理。如果觉得TCP的行为很难理解,可能只是因为你在试图破坏网络的规则,网络的规则只有两点:效率和公平。真的,杀一个人很容易,却代价高昂,与人相处,很难,却可以细水长流终一生!本文介绍一下网络对TCP发送端时序的影响如何在报文序列上体现出来,使用Wireshark。
1.如何Wireshark看TCP拥塞窗口的大小
Wireshark是网络协议分析的利器,不光如此,使用它还可以分析“未体现在数据包”里的信息,比如TCP的拥塞窗口的大小。TCP的拥塞窗口并未体现在数据包本身,它完全是端到端利用网络的反馈信息通过协议栈自己算出来的,这种反馈包括ACK序列以及超时事件等。那么如何通过Wireshark展示的一个TCP流的包序列分析出TCP的拥塞窗口大小呢。
其实很简单,只要算出in flight的数量即可。TCP的发送窗口等于拥塞窗口(cwnd)与对端通告窗口(awnd)中的最小值:
wnd=min(awnd,cwnd)
如果cwnd比awnd大,那可以不关注cwnd,因此其对数据发送无影响(TCP自带了拥塞窗口限制机制,使其不会大得太多,此为制止突发),因此只关注cwnd小于awnd的情形,此时:
wnd=cwnd
我们知道,在TCP形成一个连续的ACK时钟后,发送是平缓的,所谓的平缓指的是发送行为基于网络上的数据包守恒原则,被确认一个,发送一个,因此:
cwnd=in flight+tosend
tosend是我们将要发送的数据包数量,按照数据包守恒,可以认为tosend是当前被ACK的数据量,按照段数计数,如果接收端未启用delay ACK,那么每次将ACK一个段,即:
cwnd=in flight+1
看上面的公式时,请暂时忘记拥塞窗口的突变,后面会讲。接下来,如果对端启用了delay ACK,那么每次将最多ACK 2个段,即:
cwnd=in flight+max(thisACKed,2)
请暂时忘记ACK丢失的情况,这个普遍可能发生的现象会在TCP发送端到底是数ACK的数量还是数ACK确认的字节数之间引发争议,我个人倾向于这个选择交给TCP自己来做,这充分考虑到昂贵的无线链路中带宽的前向后向不对称性。然后考虑到拥塞避免阶段,我们可以认为:
cwnd=cwnd+(1/cwnd|1)
如果在慢启动阶段,则:
cwnd=cwnd+1
因此,最终我们可得到拥塞窗口的大小:
cwnd=in flight+max(thisACKed,2)+(1/cwnd|1)
现在的问题是如何去求in flight的大小。非常简单,公式如下:
in flight=当前发送到的-当前最后被确认的
我们用一个实际的抓包结果来确认一下,在此之前说明,Wireshark可以为你分析出大多数的in flight报文,只要它能精确确认两个数值:当前发送到的序列号以及当前最后被确认的序列号。因此你可以不必自己去按照上述公式自己去计算,而是直接通过Wireshark就可以看到。我先展示一个确认包:
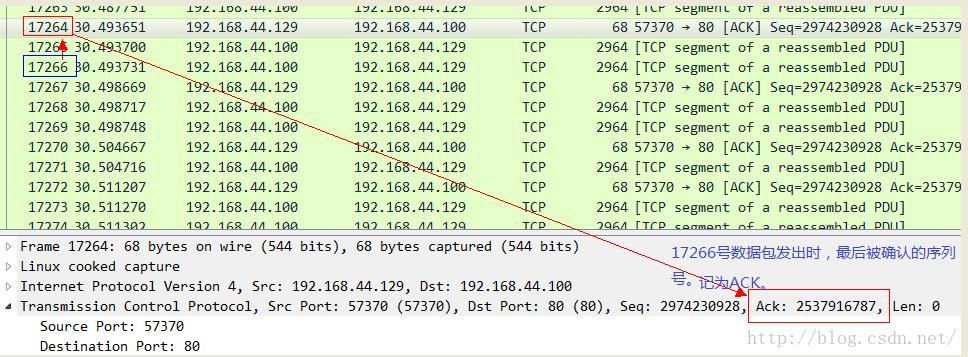
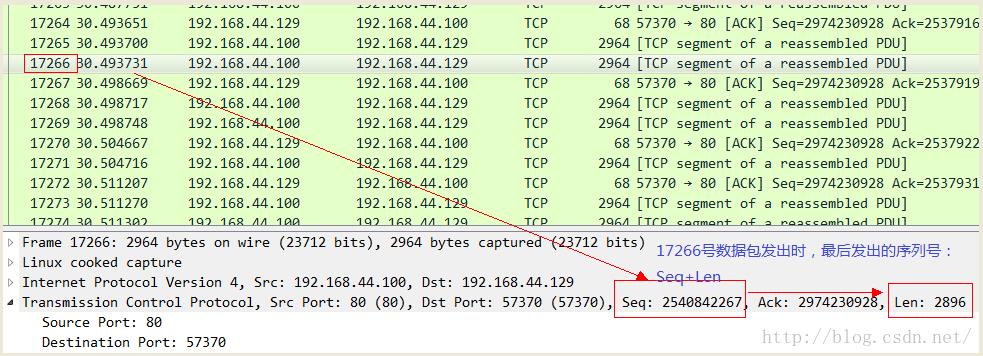
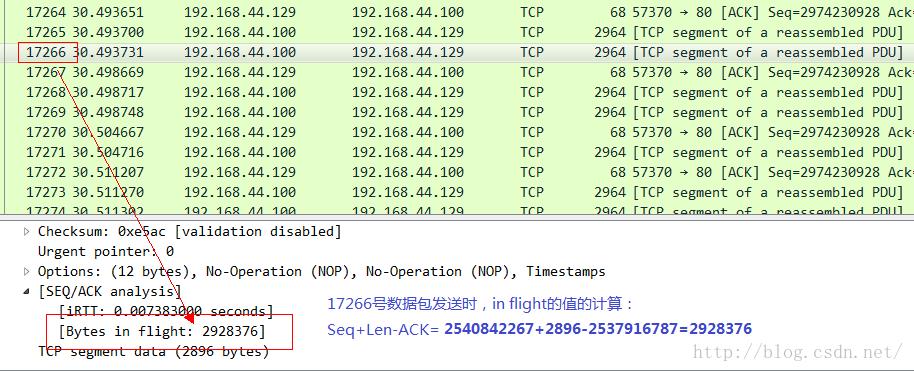
有的时候,你可能会发现点击Wireshark中某个数据包的时候,并没有展示出in flight的值,那是因为前面有些数据包没有抓到,而且这些未抓取到的数据包和当前数据包之间又没有ACK包,所以不足以提供上述计算in flight值所需要的元素,因此就不会替你计算,不是没有,而是丢失了信息,计算不出来而已。
但是有的时候,有人完全迷信Wireshark的结果(其实说的就包括我自己),所以造成了令人遗憾又可悲的结果。这到底是怎么回事呢?且看下节。
2.多余的数据包flight到哪儿了?
我做了一个测试,在TCP的发送端加入下列命令模拟一个300ms的数据包延迟:tc qdisc add dev eth0 root netem delay 300ms
然后同样在TCP发送端进行tcpdump抓包,然后用Wireshark来解析。
我们来看3064号ACK包到达发送端时候的情景:
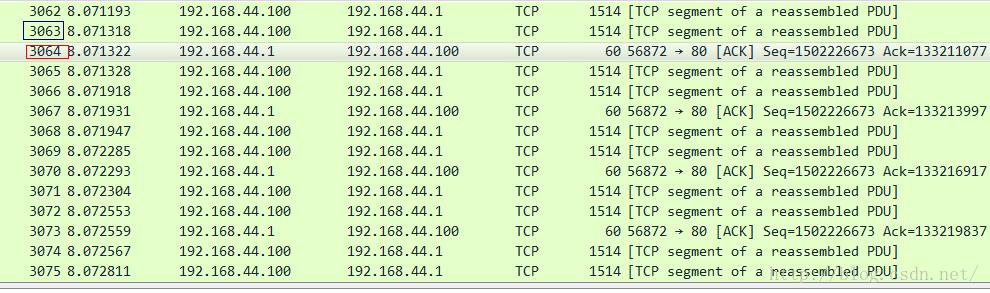
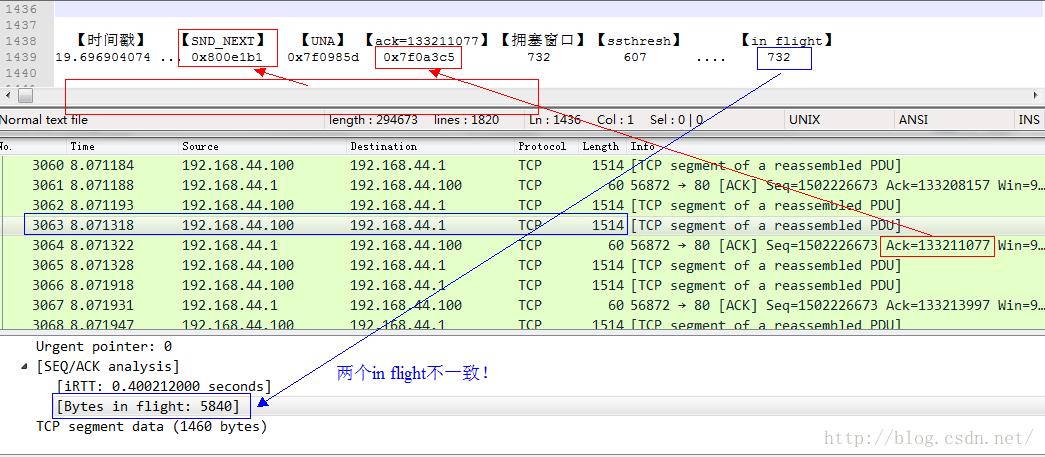
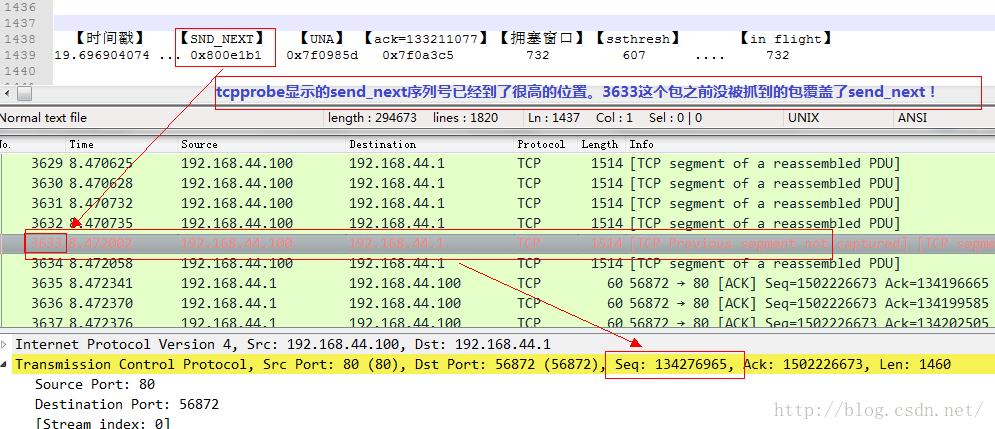
要想明确知道原因,需要对抓包的位置有足够的理解。tcpprobe显示的是TCP栈那里的情景,而tcpdump抓取的确实网卡边界的情景,中间隔了一个“qdisc”逻辑,即队列管理。也就是说TCP确实将732个数据段发出去了,因此它会认为其已经in flight了,但是这些数据并没有到达网上,而是到达了qdisc队列里面,考虑到是千兆网络同一网段的模拟,基本可以忽略传输延迟,因此tcpdump抓取的所谓in flight只是qdisc后面到达接收端的in flight。如果用端到端的观点,qdisc确实也是sky的一部分,但是对于tcpdump附着的网卡来讲,qdisc只是一个island,我想这就是区别:
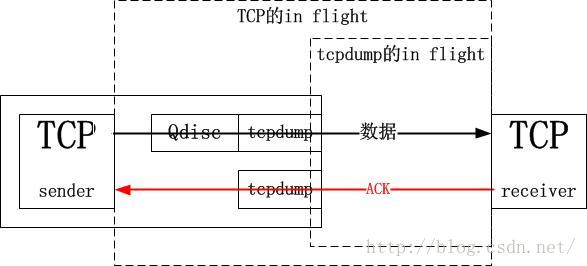
3.插一点理论:拥塞窗口自动变速调节
TCP发送端基于ACK带来的反馈信号发送数据:1).端到端的数据包守恒反馈
在接收端通告窗口允许的范围内执行数据守恒策略,接收端确认了多少数据就再发多少数据,记为E。2).网络拥塞状况反馈
根据ACK确认到达的速率,其字段中算出的RTT以及被确认的数据量来增减拥塞窗口,执行加性增乘性减逻辑以保证收敛。在拥塞窗口允许范围内最大限度发送发送通告窗口内的数据,记为W。在以上两类反馈信号分别允许发送的数据量E和W中取最小的值作为发送量,这样可以同时满足二者的限制。
需要记住的是,发多少数据并不是拥塞窗口决定的,而是对端通告窗口决定的,这个决定由ACK时钟流反馈到发送端,收到ACK后执行数据包守恒,放出被ACK的数据量,发送端理论上还可以发送通告窗口大小的数据,但要问一下网络情况是否允许发送这么多,这就是拥塞窗口的作用,它的增减是一个独立的过程!唯一和别的逻辑交互的点在于:它的值减去in flight的值就是还可以发送的数据量,当它大于最大允许的突发时,拥塞窗口将不再增长,还是那句话,拥塞窗口不能突发增长,这是个反馈系统,只有反馈信号才能诱导窗口增长,所有的拥塞控制算法都在保证增窗是加性的,即缓慢的,一来这是线性控制系统中收敛性的要求,二来它可以让拥塞控制系统捕获到突发,从而禁止拥塞窗口的进一步增长以加重突发,最终造成网络拥塞。这里说的反馈信号就是本节开头描述的那两种反馈信号。
如果你读过Linux的TCP协议实现的代码,我想你应该知道,收到ACK后,可发送的数据量大于一个可承受突发后将不会执行拥塞避免逻辑,由于窗口是缓慢增加的,一旦增加到超过一个突发的节奏,就会马上被拉回来,拉回到in flight的位置。如果你没读过,就看看RFC,然后...算了,请记住这个结论。我本来想把这个反馈系统按照控制论的机理画个图出来,但还是觉得多此一举,还是直接看数据包吧。且看下节。
4.阵发发送与平缓发送
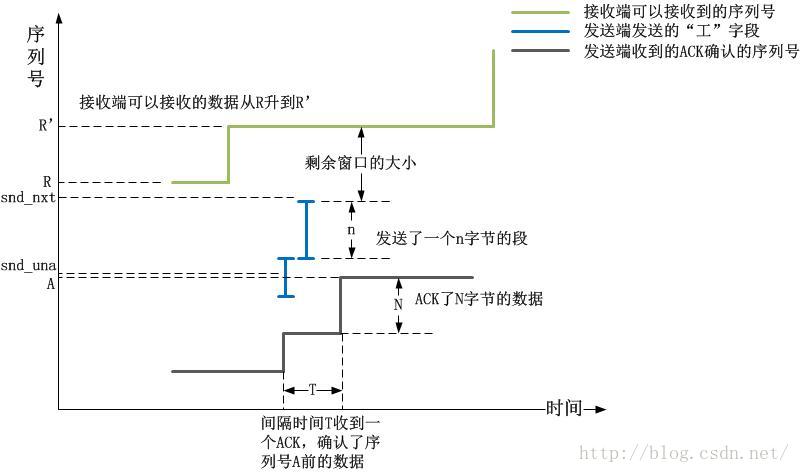
在描述这个问题前,我先给出一个关于Wireshark的“统计-TCP流图形-时间序列(tcptrace)”图的一个查看方法。我不建议看Stenves,因为它的信息不全。在tcptrace图中,我们可以看到三条线:1).对端的接收端窗口容纳的最高序列号线,阶梯形。
2).发送端发出的序列号以及长度线,典型呈现“工”形。
3).接收端ACK的序列号线,阶梯形
以下图示简单描述了上述的三类线:
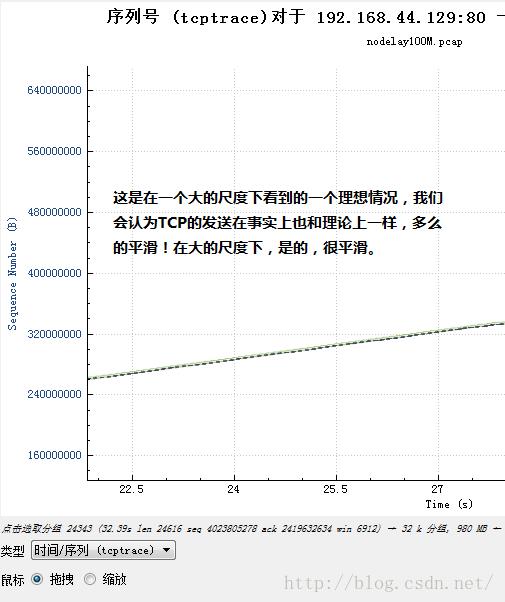
可是缩放以后近看,它可能是这个样子:
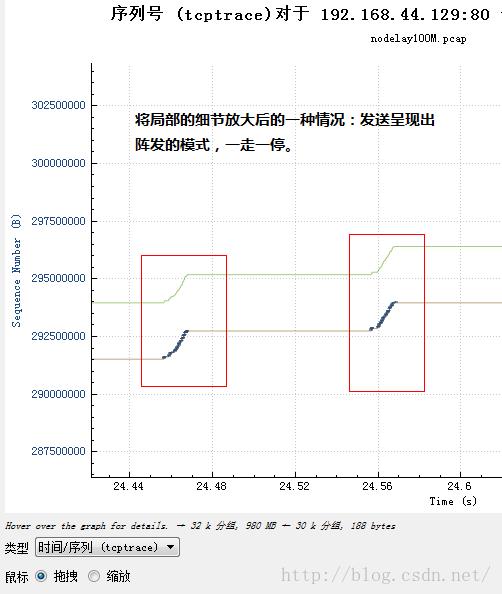
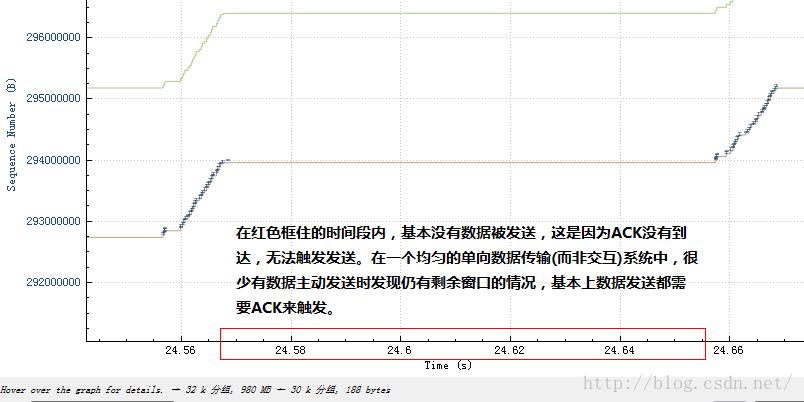
或者说是这个样子:
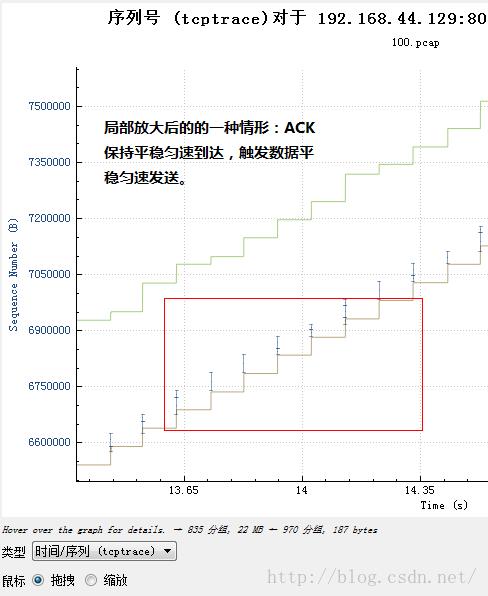
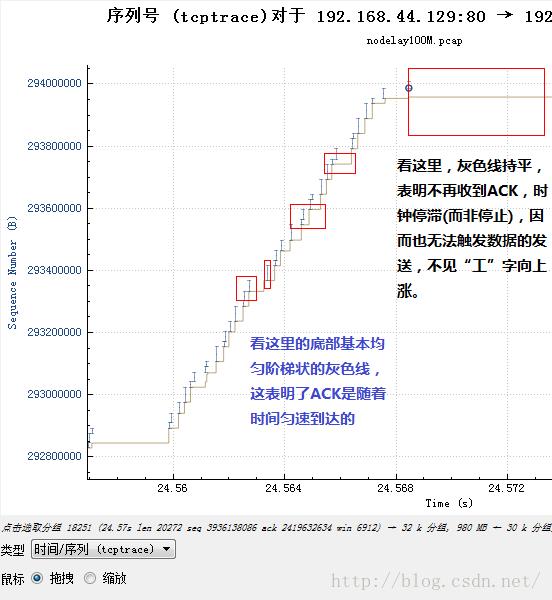
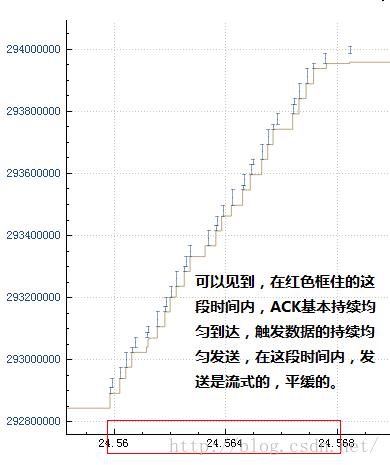
然后再结合不发送数据的那一部分:
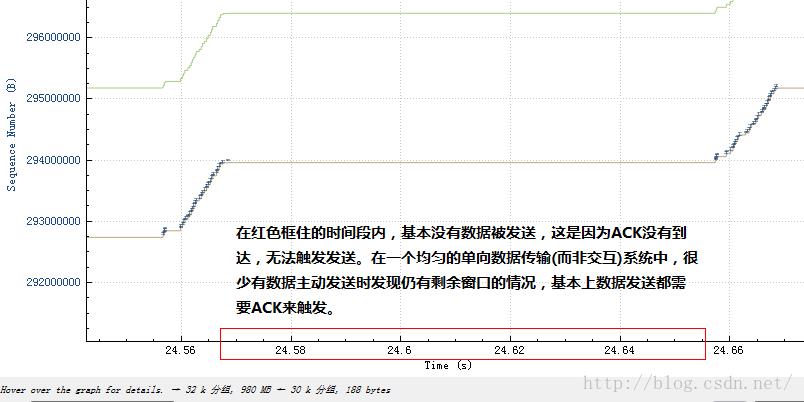
具体可以看一下流量整形的细节,本文不再描述。最简单的就是统一设置一个延时,由于TCP是由慢启动开始的,因此一开始数据量只是初始窗口大小的一小段,然后等待这段数据的ACK,再发送另外的段,这种阵发模式将会由于统一延时而被保持下去,即便是数据已经塞满了网络,也还是会保持下去。事实上由于统一延时也是一堵时间墙,因此仅仅设置一个统一的延时,并无法真正模拟“长肥管道”,虽然长肥管道里的数据包也是统一延时的,但这些延时是时间展开的,tc设置的统一延时则是时间阻滞的,因此,设置统一延时后,除了你会看到窗口大增之外,和长肥管道一点也不像。
5.如何从RTT看网络拥塞
下面我们来看一下RTT对数据发送的影响,这方面的理论已经烂大街了,所以我不想一再重复。结论如下:1).RTT不会缓增缓降(线性的),而是陡增陡降的(指数级),这是网络排队的本质决定的;
2).是RTT的变化率而不是RTT本身描述了网络的情况,RTT可能是固有的,需要关注的是其变化率;
3).观察RTT的变化率应从以下两方面入手:
a.对变化率求导,甚至二阶导数,找出拐点,预测队列清空以及继续排队。事件发生的时候,TCP收到反馈后怕是来不及反应;
b.RTT持平的时候,可以过滤出噪声丢包,这种信号如果能被TCP发送端捕获,将不必乘性减窗而重传。
下面展示一下从Wireshark的时间/序列号图以及RTT/序列号的对比:
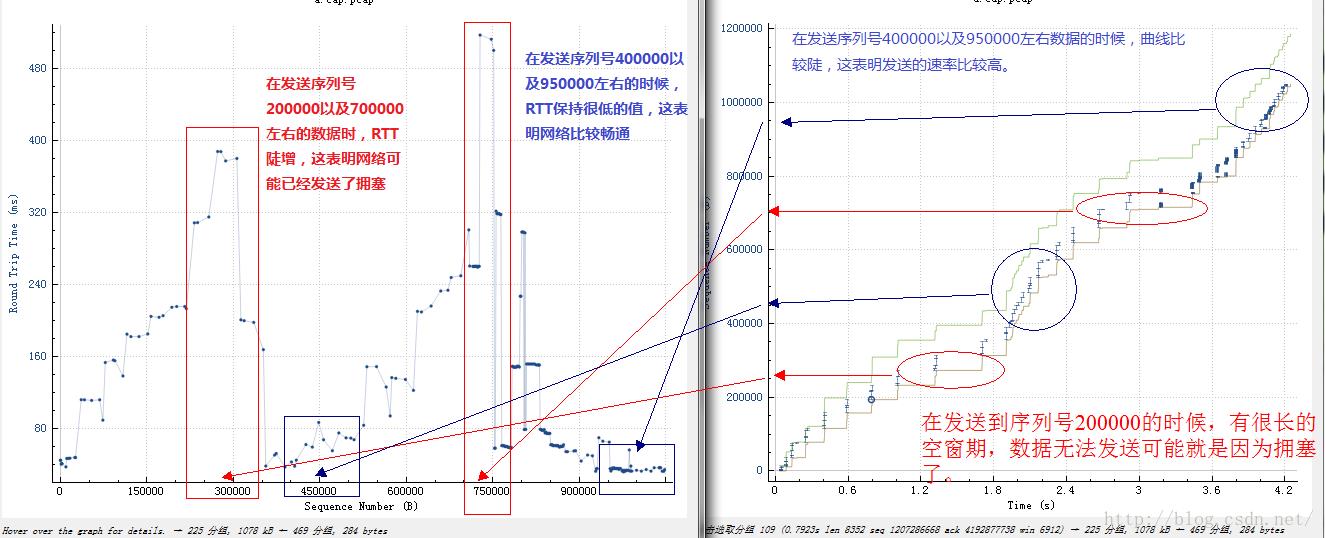
6.ACK丢失的情况
最后我们来看下ACK丢失会怎样。通常人们很难想象ACK会丢失,也不会在乎ACK丢失的后果,人们总是仅仅关注手头上正在做的,比如TCP数据的发送。ACK是可能丢失的,并且ACK不会被ACK,因此不会被重传,TCP接收端记得住它接收到了哪里,因此任意时刻它都能给出正确的ACK。问题是这对于发送端意味着什么。ACK是发送端的时钟!
如果连续的ACK丢失了,就会出现一个ACK确认了大块数据的场景,由于前面ACK连续丢失,发送端久久未收到时钟反馈导致数据不能发送,但其实就像带突发的令牌桶一样,这段时间内需要发送但未发送的数据可能被积累了,一旦收到一个确认很多数据的ACK,TCP希望这个ACK作为一个积累令牌可以补偿ACK丢失带来的空窗期,但是这样做是有问题的,它可能会造成突发。因此TCP把这个策略的选择留给了用户,TCP有两个选择,一个是按照ACK确认的数据量来反馈,一个是按照单纯的ACK包的数量来反馈,前一种选择更精细,然而后一种选择则更加真实的反馈了网络情况。
值得注意的是,整个互联网中已经有相当的百分比的数据包是单纯的裸ACK包了,作为一种控制信令,它已经跟数据本身一样纵横逍遥在互联网各个链路中了。
以上是关于流量整形,延迟以及ACK丢失对TCP发送时序的影响的主要内容,如果未能解决你的问题,请参考以下文章