Python+Selenium----使用HTMLTestRunner.py生成自动化测试报告2(使用PyCharm )
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python+Selenium----使用HTMLTestRunner.py生成自动化测试报告2(使用PyCharm )相关的知识,希望对你有一定的参考价值。
1.说明
在我前一篇文件(Python+Selenium----使用HTMLTestRunner.py生成自动化测试报告1(使用IDLE ))中简单的写明了,如何生产测试报告,但是使用IDLE很麻烦,而且在实际的项目中也不方便,所以,查了很多资料来研究如何在PyCharm中生成测试报告,故此记录一下(命名什么的不规范就不要纠结了)。
2.步骤
第一步:下载HTMLTestRunner.py
参考:Python+Selenium----使用HTMLTestRunner.py生成自动化测试报告1(使用IDLE )
第二步:PyCharm中生成测试报告
前提:方法运行成功,显示ok,但是没有生成测试报告,此时可以采用一下几种方法中的其中一种,进行处理,然后就可以顺利的生成测试报告啦~~
方法一:修改运行路径(比较麻烦,每次运行的文件可能都会更改)
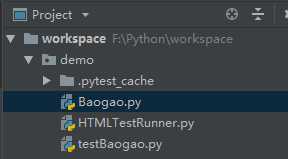 (项目结构图)
(项目结构图)
(2.1.1)PyCharm右上角,在要运行的文件上点击宣选择"Edit Configurations..."
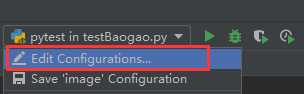
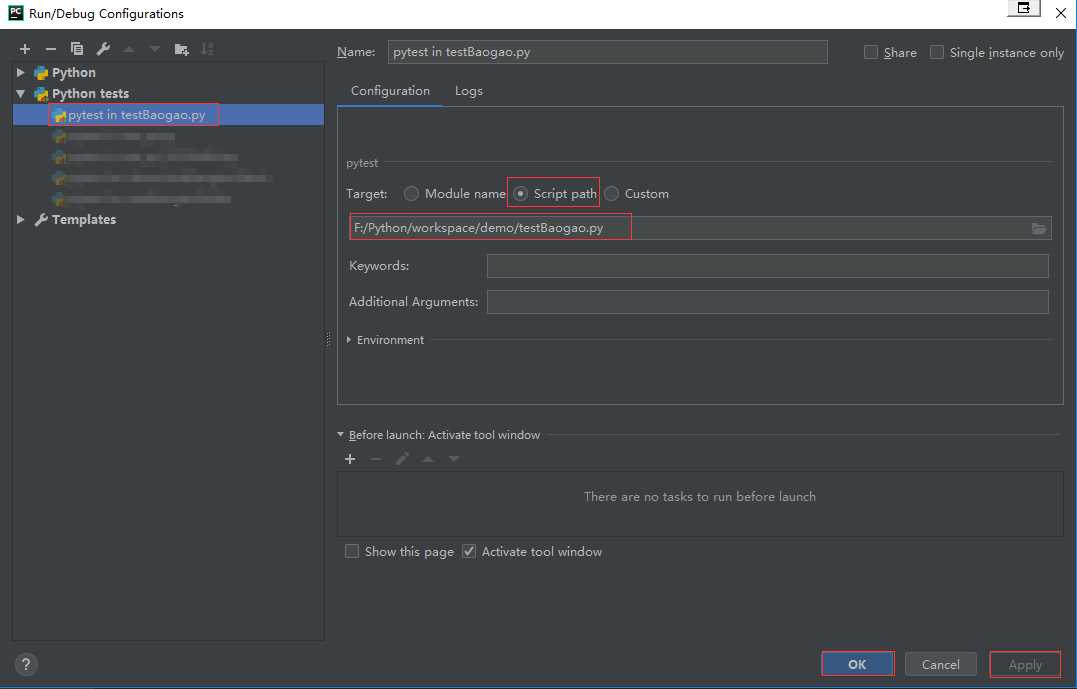
(2.1.2)在打开的弹出框中,在Python tests里找到自己要运行的文件,修改他的路径为运行文件路径,修改完成之后先apply再点击ok,然后在PyCharm右上角点击“运行”,运行完成,就会发现测试报告生成了奥~~
方法二:在main函数上运行.py文件
我们在main函数中简单的添加一句打印代码,发现,在.py中随意找个地方,鼠标右键“run”之后,并未打印,可见,脚本运行时并没有执行里面的代码,为什么没有执行里面的代码呢?因为在Pycharm不同的地方右键后,运行脚本得到的结果是不一样的,执行的代码段不一样,所以,我们可以在main函数处,右键,运行脚本,运行完成,就会生成测试报告文件(但是,我在main函数处运行,我一个测试运行,跑了2次,尴尬,暂时不知道为什么)
import time import unittest import htmlTestRunner #直接将HTMLTestRunner.py放到python安装目录下的Lib中即可 from selenium import webdriver class Baidu(unittest.TestCase): def setUp(self): self.driver = webdriver.Chrome(‘F:\\Python\\workspace\\selenium_demo3_test\\drivers\\chromedriver.exe‘) self.driver.implicitly_wait(30) self.base_url = "http://www.baidu.com/" self.verificationErrors = [] self.accept_next_alert = True # 百度搜索用例 def test_baidu_search(self): driver = self.driver driver.get(self.base_url + "/") driver.find_element_by_id("kw").send_keys("selenium webdriver") driver.find_element_by_id("su").click() time.sleep(2) def tearDown(self): self.driver.quit() self.assertEqual([], self.verificationErrors) if __name__ == "__main__": print(‘11111111111111111111111111111111111111111111‘) # 定义一个单元测试容器 testunit = unittest.TestSuite() # 将测试用例加入到测试容器中 testunit.addTest(Baidu("test_baidu_search")) # 定义个报告存放路径,支持相对路径 filename = ‘F:\\Python\\workspace\\demo\\result.html‘ fp = open(filename, ‘wb‘) # 定义测试报告 runner = HTMLTestRunner.HTMLTestRunner( stream=fp, title=‘测试报告hahhahahah‘, description=‘用例执行情况hahhaahha:‘ ) # 运行测试用例 runner.run(testunit) # 写完之后必须将fp关闭,否则报告是空的 fp.close()
方法三:定义一个函数,讲main函数中的内容复制到该函数中,在main函数中,运行自己定义的函数,也可以正常生成测试报告
testBaogao.py
import time import unittest import HTMLTestRunner #直接将HTMLTestRunner.py放到python安装目录下的Lib中即可 from selenium import webdriver from demo.Baogao import * class Baidu(unittest.TestCase): def setUp(self): self.driver = webdriver.Chrome(‘F:\\Python\\workspace\\selenium_demo3_test\\drivers\\chromedriver.exe‘) self.driver.implicitly_wait(30) self.base_url = "http://www.baidu.com/" self.verificationErrors = [] self.accept_next_alert = True # 百度搜索用例 def test_baidu_search(self): driver = self.driver driver.get(self.base_url + "/") driver.find_element_by_id("kw").send_keys("selenium webdriver") driver.find_element_by_id("su").click() time.sleep(2) def tearDown(self): self.driver.quit() self.assertEqual([], self.verificationErrors) if __name__ == "__main__": print(‘1111111111111111111111111111111111111‘) test_baogao() #调用另外一个函数
Baogao.py
import HTMLTestRunner from demo.testBaogao import * def test_baogao(): # 定义一个单元测试容器 testunit = unittest.TestSuite() # 将测试用例加入到测试容器中 testunit.addTest(Baidu("test_baidu_search")) # 定义个报告存放路径,支持相对路径 filename = ‘F:\\Python\\workspace\\demo\\result.html‘ fp = open(filename, ‘wb‘) # 定义测试报告 runner = HTMLTestRunner.HTMLTestRunner( stream=fp, title=u‘百度搜索测试报告‘, description=u‘用例执行情况:‘ ) # 运行测试用例 runner.run(testunit) # 写完之后必须将fp关闭,否则报告是空的 fp.close()
如上demo所示,在testBaogao.py文件中随意地方运行文件即可生成测试报告。
以上是关于Python+Selenium----使用HTMLTestRunner.py生成自动化测试报告2(使用PyCharm )的主要内容,如果未能解决你的问题,请参考以下文章