day6 反射,hashlib模块,正则匹配,冒泡,选择,插入排序
Posted Jason_wang_2016
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了day6 反射,hashlib模块,正则匹配,冒泡,选择,插入排序相关的知识,希望对你有一定的参考价值。
一.反射(自省)
首先通过一个例子来看一下本文中可能用到的对象和相关概念。
import sys # 模块,sys指向这个模块对象
import inspect
def foo(): pass # 函数,foo指向这个函数对象
class Cat(object): # 类,Cat指向这个类对象
def __init__(self, name=\'kitty\'):
self.name = name
def sayHi(self): # 实例方法,sayHi指向这个方法对象,使用类或实例.sayHi访问
print(self.name), \'says Hi!\' # 访问名为name的字段,使用实例.name访问
cat = Cat()#cat 是Cat类的实例对象
print(Cat.sayHi) # 使用类名访问实例方法时,方法是未绑定的(unbound)
>>> <function Cat.sayHi at 0x101478378>
print(cat.sayHi) # 使用实例访问实例方法时,方法是绑定的(bound)
>>> <bound method Cat.sayHi of <__main__.Cat object at 0x101178e48>>
有时候我们会碰到这样的需求,需要执行对象的某个方法,或是需要对对象的某个字段赋值,而方法名或是字段名在编码代码时并不能确定,需要通过参数传递字符串的形式输入。举个具体的例子:当我们需要实现一个通用的DBM框架时,可能需要对数据对象的字段赋值,但我们无法预知用到这个框架的数据对象都有些什么字段,换言之,我们在写框架的时候需要通过某种机制访问未知的属性。
这个机制被称为反射(反过来让对象告诉我们他是什么),或是自省(让对象自己告诉我们他是什么,好吧我承认括号里是我瞎掰的- -#),用于实现在运行时获取未知对象的信息。反射是个很吓唬人的名词,听起来高深莫测,在一般的编程语言里反射相对其他概念来说稍显复杂,一般来说都是作为高级主题来讲;但在Python中反射非常简单,用起来几乎感觉不到与其他的代码有区别,使用反射获取到的函数和方法可以像平常一样加上括号直接调用,获取到类后可以直接构造实例;不过获取到的字段不能直接赋值,因为拿到的其实是另一个指向同一个地方的引用,赋值只能改变当前的这个引用而已。
1. 访问对象的属性
以下列出了几个内建方法,可以用来检查或是访问对象的属性。这些方法可以用于任意对象而不仅仅是例子中的Cat实例对象;Python中一切都是对象。
def foo(): pass # 函数,foo指向这个函数对象
class Cat(object): # 类,Cat指向这个类对象
def __init__(self, name=\'kitty\'):
self.name = name
def sayHi(self): # 实例方法,sayHi指向这个方法对象,使用类或实例.sayHi访问
print(self.name), \'says Hi!\' # 访问名为name的字段,使用实例.name访问
cat = Cat(\'kitty\')
print(cat.name) # 访问实例属性
>>>kitty
cat.sayHi() # 调用实例方法
>>>kitty
print(dir(cat)) # 获取实例的属性名,以列表形式返回
>>>[\'__class__\', \'__delattr__\', \'__dict__\', \'__dir__\', \'__doc__\', \'__eq__\', \'__format__\', \'__ge__\', \'__getattribute__\', \'__gt__\', \'__hash__\', \'__init__\', \'__le__\', \'__lt__\', \'__module__\', \'__ne__\', \'__new__\', \'__reduce__\', \'__reduce_ex__\', \'__repr__\', \'__setattr__\', \'__sizeof__\', \'__str__\', \'__subclasshook__\', \'__weakref__\', \'name\', \'sayHi\']
if hasattr(cat, \'name\'): # 检查实例是否有这个属性
setattr(cat, \'name\', \'tiger\') # same as: a.name = \'tiger\'
print(getattr(cat, \'name\')) # same as: print a.name
>>>tiger
getattr(cat, \'sayHi\')() # same as: cat.sayHi()
>>>tiger
- dir([obj]):
调用这个方法将返回包含obj大多数属性名的列表(会有一些特殊的属性不包含在内)。obj的默认值是当前的模块对象。
- hasattr(obj, attr):
这个方法用于检查obj是否有一个名为attr的值的属性,返回一个布尔值。
- getattr(obj, attr):
调用这个方法将返回obj中名为attr值的属性的值,例如如果attr为\'bar\',则返回obj.bar。
- setattr(obj, attr, val):
调用这个方法将给obj的名为attr的值的属性赋值为val。例如如果attr为\'bar\',则相当于obj.bar = val。
例子:
自定义模块commons.py如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: Jason Wang
def login():
print(\'登录界面\')
def logout():
print(\'注销界面\')
def home():
print(\'home界面\')
在另外一个index脚本中导入commons模块,具体如下所示
import commons
def run():
inp = input(\'输入你要执行的函数名\')
#inp 字符串类型 eg. inp = \'login\'
# delattr()
# setattr()
#利用字符串对模块进行操作(增加,删除,修改,查询)
if hasattr(commons,inp):#判断commons是否存在inp函数,如果存在获取此函数,否则404
func = getattr(commons,inp)#获取commons下的inp对应的函数
func()#执行对应的函数
else:
print(\'404\')
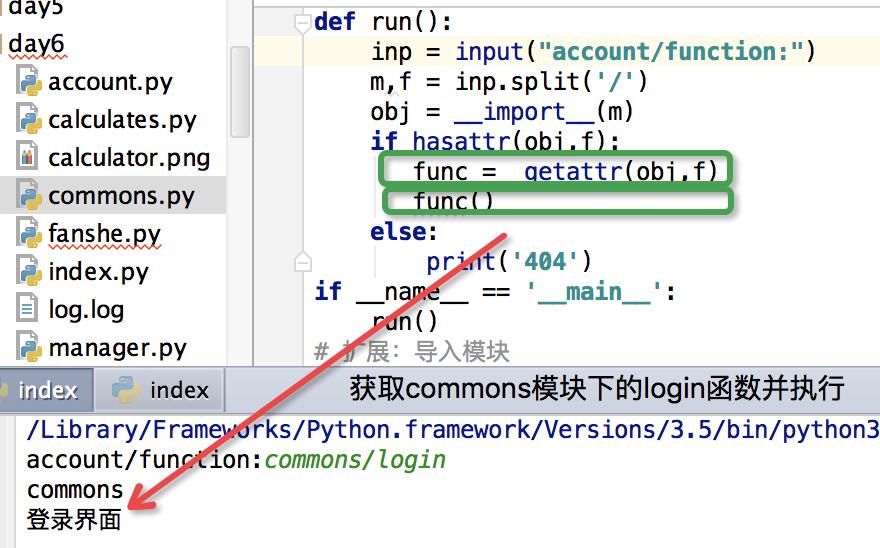
通过__import__字符串方式导入函数,需要输入模块名和此模块下的函数名
def run():
inp = input(\'account/function\')
m,f = inp.split(\'/\')
obj = __import__(m)#导入包及
if hasattr(obj,f):
func = getattr(obj,f)
func()
else:
print(\'404\')
if __name__ == \'__main__\':
run()
*模块内置参数补充说明*
- __doc__: 文档字符串。如果模块没有文档,这个值是None。
- *__name__: 始终是定义时的模块名;即使你使用import .. as 为它取了别名,或是赋值给了另一个变量名。
- *__dict__: 包含了模块里可用的属性名-属性的字典;也就是可以使用模块名.属性名访问的对象
- __file__: 包含了该模块的文件路径。需要注意的是内建的模块没有这个属性,访问它会抛出异常!
commons.py
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author: Jason Wang
# commons.py """ document for fanshe """ def login(): print(\'登录界面\') def logout(): print(\'注销界面\') def home(): print(\'home界面\')
##运行结果 print(__name__) >>>__main__
index脚本导入commons
>>>document for fanshe
print(com.__name__)# commons脚本名
>>>commons
print(com.__file__)
二.hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib m = hashlib.md5() m.update(b"Hello") m.update(b"It\'s me") print(m.digest()) m.update(b"It\'s been a long time since last time we ...") print(m.digest()) #2进制格式hash print(len(m.hexdigest())) #16进制格式hash \'\'\' def digest(self, *args, **kwargs): # real signature unknown """ Return the digest value as a string of binary data. """ pass def hexdigest(self, *args, **kwargs): # real signature unknown """ Return the digest value as a string of hexadecimal digits. """ pass \'\'\' import hashlib # ######## md5 ######## hash = hashlib.md5() hash.update(\'admin\') print(hash.hexdigest()) # ######## sha1 ######## hash = hashlib.sha1() hash.update(\'admin\') print(hash.hexdigest()) # ######## sha256 ######## hash = hashlib.sha256() hash.update(\'admin\') print(hash.hexdigest()) # ######## sha384 ######## hash = hashlib.sha384() hash.update(\'admin\') print(hash.hexdigest()) # ######## sha512 ######## hash = hashlib.sha512() hash.update(\'admin\') print(hash.hexdigest())
还不够吊?python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
import hmac h = hmac.new(\'Jason\') h.update(\'hellowo\') print h.hexdigest()
更多关于md5,sha1,sha256等介绍的文章看这里https://www.tbs-certificates.co.uk/FAQ/en/sha256.html
三.正则表达式
1、Python支持的正则表达式元字符和语法
| 语法 | 说明 | 表达式实例 | 完整匹配的字符串 |
| 字符 | |||
| 一般字符 | 匹配自己 | abc | abc |
| . | 匹配任意字符“\\n”除外 DOTALL模式中(re.DOTALL)也能匹配换行符 |
a.b | abc或abc或a1c等 |
| [...] | 字符集[abc]表示a或b或c,也可以-表示一个范围如[a-d]表示a或b或c或d | a[bc]c | abc或adc |
| [^...] | 非字符集,也就是非[]里的之外的字符 | a[^bc]c | adc或aec等 |
| 预定义字符集(也可以系在字符集[...]中) | |||
| \\d | 数字:[0-9] | a\\dc | a1c等 |
| \\D | 非数字:[^0-9]或[^\\d] | a\\Dc | abc等 |
| \\s | 空白字符:[<空格>\\t\\n\\f\\v] | a\\sc | a b等 |
| \\S | 非空白字符:[^s] | a\\Sc | abc等 |
| \\w | 字母数字(单词字符)[a-zA-Z0-9] | a\\wc | abc或a1c等 |
| \\W | 非字母数字(非单词字符)[^\\w] | a\\Wc | a.c或a_c等 |
| 数量词(用在字符或(...)分组之后) | |||
| * | 匹配0个或多个前面的表达式。(注意包括0次) | abc* | ab或abcc等 |
| + | 匹配1个或多个前面的表达式。 | abc+ | abc或abcc等 |
| ? | 匹配0个或1个前面的表达式。(注意包括0次) | abc? | ab或abc |
| {m} | 匹配m个前面表达式(非贪婪) | abc{2} | abcc |
| {m,} | 匹配至少m个前面表达式(m至无限次) | abc{2,} | abcc或abccc等 |
| {m,n} | 匹配m至n个前面的表达式 | abc{1,2} | abc或abcc |
| 边界匹配(不消耗待匹配字符中的字符) | |||
| ^ | 匹配字符串开头,在多行模式中匹配每一行的开头 | ^abc | abc或abcd等 |
| $ | 匹配字符串结尾,在多行模式中匹配每一行的结尾 | abc$ | abc或123abc等 |
| \\A | 仅匹配字符串开头 | \\Aabc | abc或abcd等 |
| \\Z | 仅匹配字符串结尾 | abc\\Z | abc或123abc等 |
| \\b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, \'er\\b\' 可以匹配"never" 中的 \'er\',但不能匹配 "verb" 中的 \'er\'。 | ||
| \\B | 匹配非单词边界。\'er\\B\' 能匹配 "verb" 中的 \'er\',但不能匹配 "never" 中的 \'er\'。 | ||
| 逻辑、分组 | |||
| | | 或左右表达式任意一个(短路)如果|没有在()中表示整个正则表达式(注意有括号和没括号的区别) | abc|def ab(c|d)ef |
abc或def abcef或abdef |
| (...) | 分组,可以用来引用,也可以括号内的被当做一组进行数量匹配后接数量词 | (abc){2}a | abcabca |
| (?P<name>...) | 分组别名,给分组起个名字,方便后面调用 | ||
| \\<number> | 引用编号为<number>的分组匹配到的字符串(注意是配到的字符串不是分组表达式本身) | (\\d)abc\\1 | 1ab1或5ab5等 |
| (?=name) | 引用别名为name的分组匹配到的字符串(注意是配到的字符串不是分组表达式本身) | (?P<id>\\d)abc(?P=id) | 1ab1或5ab5等 |
一简介:
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,
(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被
编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
二
字符匹配(普通字符,元字符):
普通字符:大多数字符和字母都会和自身匹配
>>> re.findall(\'alex\',\'yuanaleSxalexwupeiqi\')
[\'alex\']
2元字符:. ^ $ * + ? { } [ ] | ( ) \\
我们首先考察的元字符是"[" 和 "]"。它们常用来指定一个字符类别,所谓字符类
别就是你想匹配的一个字符集。字符可以单个列出,也可以用“-”号分隔的两个给定
字符来表示一个字符区间。例如,[abc] 将匹配"a", "b", 或 "c"中的任意一个字
符;也可以用区间[a-c]来表示同一字符集,和前者效果一致。如果你只想匹配小写
字母,那么 RE 应写成 [a-z].
元字符在类别里并不起作用。例如,[akm$]将匹配字符"a", "k", "m", 或 "$" 中
的任意一个;"$"通常用作元字符,但在字符类别里,其特性被除去,恢复成普通字
符。
():
#!python
>>> p = re.compile(\'(a(b)c)d\')
>>> m = p.match(\'abcd\')
>>> m.group(0)
\'abcd\'
>>> m.group(1)
\'abc\'
>>> m.group(2)
\'b\'
[]:元字符[]表示字符类,在一个字符类中,只有字符^、-、]和\\有特殊含义。
字符\\仍然表示转义,字符-可以定义字符范围,字符^放在前面,表示非.
+ 匹配+号前内容1次至无限次
? 匹配?号前内容0次到1次
{m} 匹配前面的内容m次
{m,n} 匹配前面的内容m到n次
*?,+?,??,{m,n}? 前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
从前面的描述可以看到\'*\',\'+\'和\'*\'都是贪婪的,但这也许并不是我们说要的,
所以,可以在后面加个问号,将策略改为非贪婪,只匹配尽量少的RE。示例,
体会两者的区别:
>>> re.findall(r"a(\\d+?)","a23b") # 非贪婪模式
[\'2\']
>>> re.findall(r"a(\\d+)","a23b")
[\'23\']
>>> re.search(\'<(.*)>\', \'<H1>title</H1>\').group()
\'<H1>title</H1>\'
re.search(\'<(.*?)>\', \'<H1>title</H1>\').group()
\'<H1>\'
注意比较这种情况:
>>> re.findall(r"a(\\d+)b","a23b")
[\'23\']
>>> re.findall(r"a(\\d+?)b","a23b") #如果前后均有限定条件,则非匹配模式失效
[\'23\']
\\:
反斜杠后边跟元字符去除特殊功能,
反斜杠后边跟普通字符实现特殊功能。
引用序号对应的字组所匹配的字符串
re.search(r"(alex)(eric)com\\2","alexericcomeric")
\\d 匹配任何十进制数;它相当于类 [0-9]。
\\D 匹配任何非数字字符;它相当于类 [^0-9]。
\\s 匹配任何空白字符;它相当于类 [ \\t\\n\\r\\f\\v]。
\\S 匹配任何非空白字符;它相当于类 [^ \\t\\n\\r\\f\\v]。
\\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]
\\b: 匹配一个单词边界,也就是指单词和空格间的位置。
匹配单词边界(包括开始和结束),这里的“单词”,是指连续的字母、数字和
下划线组成的字符串。注意,\\b的定义是\\w和\\W的交界,
这是个零宽界定符(zero-width assertions)只用以匹配单词的词首和词尾。
单词被定义为一个字母数字序列,因此词尾就是用空白符或非字母数字符来标
示的。
>>> re.findall(r"abc\\b","dzx &abc sdsadasabcasdsadasdabcasdsa")
[\'abc\']
>>> re.findall(r"\\babc\\b","dzx &abc sdsadasabcasdsadasdabcasdsa")
[\'abc\']
>>> re.findall(r"\\babc\\b","dzx sabc sdsadasabcasdsadasdabcasdsa")
[]
例如, \'er/b\' 可以匹配"never" 中的 \'er\',但不能匹配 "verb" 中的 \'er\'。
\\b只是匹配字符串开头结尾及空格回车等的位置, 不会匹配空格符本身
例如"abc sdsadasabcasdsadasdabcasdsa",
\\sabc\\s不能匹配,\\babc\\b可以匹配到"abc"
>>> re.findall("\\babc\\b","abc sdsadasabcasdsadasdabcasdsa")
[]
>>> re.findall(r"\\babc\\b","abc sdsadasabcasdsadasdabcasdsa")
[\'abc\']
\\b 就是用在你匹配整个单词的时候。 如果不是整个单词就不匹配。 你想匹
配 I 的话,你知道,很多单词里都有I的,但我只想匹配I,就是“我”,这个时
候用 \\bI\\b
************************************************
函数:
1
match:re.match(pattern, string, flags=0)
flags 编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,
多行匹配等等。
re.match(\'com\', \'comwww.runcomoob\').group()
re.match(\'com\', \'Comwww.runComoob\',re.I).group()
2
search:re.search(pattern, string, flags=0)
re.search(\'\\dcom\', \'www.4comrunoob.5com\').group()
注意:
re.match(\'com\', \'comwww.runcomoob\')
re.search(\'\\dcom\', \'www.4comrunoob.5com\')
一旦匹配成功,就是一个match object 对象,而match object 对象拥有以下方法:
group() 返回被 RE 匹配的字符串
start() 返回匹配开始的位置
end() 返回匹配结束的位置
span() 返回一个元组包含匹配 (开始,结束) 的位置
group() 返回re整体匹配的字符串,可以一次输入多个组号,对应组号匹配的字符串。
1. group()返回re整体匹配的字符串,
2. group (n,m) 返回组号为n,m所匹配的字符串,如果组号不存在,则返回indexError异常
3.groups()groups() 方法返回一个包含正则表达式中所有小组字符串的元组,从 1 到
所含的小组号,通常groups()不需要参数,返回一个元组,元组中的元就是正则
表达式中定义的组。
import re
a = "123abc456"
re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #123abc456,返回整体
re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) #123
re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) #abc
re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) #456
group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3)
列出第三个括号匹配部分。
-----------------------------------------------
3
findall:
re.findall 以列表形式返回所有匹配的字符串
re.findall可以获取字符串中所有匹配的字符串。如:
p = re.compile(r\'\\d+\')
print p.findall(\'one1two2three3four4\')
re.findall(r\'\\w*oo\\w*\', text);获取字符串中,包含\'oo\'的所有单词。
import re
text = "JGood is a handsome boy,he is handsome and cool,clever,and so on ...."
print re.findall(r\'\\w*oo\\w*\',text) #结果:[\'JGood\', \'cool\']
#print re.findall(r\'(\\w)*oo(\\w)*\',text) # ()表示子表达式 结果:[(\'G\', \'d\'), (\'c\', \'l\')]
finditer():
>>> p = re.compile(r\'\\d+\')
>>> iterator = p.finditer(\'12 drumm44ers drumming, 11 ... 10 ...\')
>>> for match in iterator:
match.group() , match.span()
4
sub subn:
re.sub(pattern, repl, string, max=0)
re.sub("g.t","have",\'I get A, I got B ,I gut C\')
5
split:
p = re.compile(r\'\\d+\')
p.split(\'one1two2three3four4\')
re.split(\'\\d+\',\'one1two2three3four4\')
6
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为
Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符\'|\'
表示同时生效,比如re.I | re.M
可以把正则表达式编译成一个正则表达式对象。可以把那些经常使用的正则
表达式编译成正则表达式对象,这样可以提高一定的效率。下面是一个正则表达式
对象的一个例子:
import re
text = "JGood is a handsome boy, he is cool, clever, and so on..."
regex = re.compile(r\'\\w*oo\\w*\')
print regex.findall(text) #查找所有包含\'oo\'的单词
question:
1 findall能不能返回全组匹配的列表,而不是优先捕获组的列表:yes,
import re
a = \'abc123abv23456\'
b = re.findall(r\'23(a)?\',a)
print b
b = re.findall(r\'23(?:a)?\',a)
print b
>>> re.findall("www.(baidu|xinlang)\\.com","www.baidu.com")
[\'baidu\']
>>> re.findall("www.(?:baidu|xinlang)\\.com","www.baidu.com")
[\'www.baidu.com\']
>>> re.findall("www.(?:baidu|xinlang)\\.com","www.xinlang.com")
[\'www.xinlang.com\']
findall如果使用了分组,则输出的内容将是分组中的内容而非find到的结果,
为了得到find到的结果,要加上问号来启用“不捕捉模式”,就可以了。
2 re.findall(\'\\d*\', \'www33333\')
3 re.split("[bc]","abcde")
4 source = "1 - 2 * ( (60-30 +(-9-2-5-2*3-5/3-40*4/2-3/5+6*3) * (-9-2-5-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )"
re.search(\'\\([^()]*\\)\', source).group()regular=\'\\d+\\.?\\d*([*/]|\\*\\*)[\\-]?\\d+\\.?\\d*\'
re.search(\'\\d+\\.?\\d*([*/]|\\*\\*)[\\-]?\\d+\\.?\\d*\', string).group()
add_regular=\'[\\-]?\\d+\\.?\\d*\\+[\\-]?\\d+\\.?\\d*\'
sub_regular=\'[\\-]?\\d+\\.?\\d*\\-[\\-]?\\d+\\.?\\d*\'
re.findall(sub_regular, "(3+4-5+7+9)")
4 检测一个IP地址:
re.search(r"(([01]?\\d?\\d|2[0-4]\\d|25[0-5])\\.){3}([01]?\\d?\\d|2[0-4]\\d|25[0-5]\\.)","192.168.1.1")
-----------------------------------------------------------
re.I 使匹配对大小写不敏感
re.L 做本地化识别(locale-aware)匹配
re.M 多行匹配,影响 ^ 和 $
re.S 使 . 匹配包括换行在内的所有字符
>>> re.findall(".","abc\\nde")
>>> re.findall(".","abc\\nde",re.S)
re.U 根据Unicode字符集解析字符。这个标志影响 \\w, \\W, \\b, \\B.
re.X 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。
re.S:.将会匹配换行符,默认.逗号不会匹配换行符
>>> re.findall(r"a(\\d+)b.+a(\\d+)b","a23b\\na34b")
[]
>>> re.findall(r"a(\\d+)b.+a(\\d+)b","a23b\\na34b",re.S)
[(\'23\',\'34\')]
>>>
re.M:^$标志将会匹配每一行,默认^只会匹配符合正则的第一行;默认$只会匹配符合正则的末行
>>> re.findall(r"^a(\\d+)b","a23b\\na34b")
[\'23\']
>>> re.findall(r"^a(\\d+)b","a23b\\na34b",re.M)
[\'23\',\'34\']
但是,如果没有^标志,
>>> re.findall(r"a(\\d+)b","a23b\\na34b")
[\'23\',\'43\']
可见,是无需re.M
import re
n=\'\'\'12 drummers drumming,
11 pipers piping, 10 lords a-leaping\'\'\'
p=re.compile(\'^\\d+\')
p_multi=re.compile(\'^\\d+\',re.MULTILINE) #设置 MULTILINE 标志
print re.findall(p,n) #[\'12\']
print re.findall(p_multi,n) # [\'12\', \'11\']
============================
import re
a = \'a23b\'
print re.findall(\'a(\\d+?)\',a) #[\'2\']
print re.findall(\'a(\\d+)\',a) #[\'23\']
print re.findall(r\'a(\\d+)b\',a) #[\'23\']
print re.findall(r\'a(\\d+?)b\',a) # [\'23\']
============================
b=\'a23b\\na34b\'
\'\'\' . 匹配非换行符的任意一个字符\'\'\'
re.findall(r\'a(\\d+)b.+a(\\d+)b\',b) #[]
re.findall(r\'a(\\d+)b\',b,re.M) # [\'23\', \'34\']
re.findall(r\'^a(\\d+)b\',b,re.M) # [\'23\', \'34\']
re.findall(r\'a(\\d+)b\',b) #[\'23\',\'34\'] 可以匹配多行
re.findall(r\'^a(\\d+)b\',b) # [\'23\'] 默认^只会匹配符合正则的第一行
re.findall(r\'a(\\d+)b$\',b) # [\'34\'] 默认$只会匹配符合正则的末行
re.findall(r\'a(\\d+)b\',b,re.M) #[\'23\', \'34\']
re.findall(r\'a(\\d+)b.?\',b,re.M) # [\'23\', \'34\']
re.findall(r"a(\\d+)b", "a23b\\na34b") # [\'23\', \'34\']
---------------------------------------------------------------
推荐:http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
*****关于rawstring以及\\:
\\n是换行,ASCLL码是10
\\r是回车,ASCLL码是13
re.findall("\\","abc\\de")
f=open("C:\\abc.txt")
\\a是 转义字符 007,响铃符 BEL。
f=open(r"D:\\abc.txt")
>>>>>>python自己也需要转义,也是通过\\转义
>>> re.findall(r"\\d","ww2ee")
[\'2\']
>>> re.findall("\\d","ww2ee")
[\'2\']
>>强烈建议用raw字符串来表述正则
你可能已经看到前面关于原始字符串用法的一些例子了。原始字符串的产生正是由于有正则表
达式的存在。原因是ASCII 字符和正则表达式特殊字符间所产生的冲突。比如,特殊符号“\\b”在
ASCII 字符中代表退格键,但同时“\\b”也是一个正则表达式的特殊符号,代表“匹配一个单词边界”。
为了让RE 编译器把两个字符“\\b”当成你想要表达的字符串,而不是一个退格键,你需要用另一个
反斜线对它进行转义,即可以这样写:“\\\\b”。
但这样做会把问题复杂化,特别是当你的正则表达式字符串里有很多特殊字符时,就更容
易令人困惑了。原始字符串就是被用于简化正则表达式的复杂程度。
事实上,很多Python 程序员在定义正则表达式时都只使用原始字符串。
下面的例子用来说明退格键“\\b” 和正则表达式“\\b”(包含或不包含原始字符串)之间的区别:
>>> m = re.search(\'\\bblow\', \'blow\') # backspace, no match #退格键,没有匹配
>>> re.search(\'\\\\bblow\', \'I blow\').group() # escaped \\, now it works #用\\转义后,现在匹
配了
>>> re.search(r\'\\bblow\', \'I blow\').group() # use raw string instead #改用原始字符串
你可能注意到我们在正则表达式里使用“\\d”,没用原始字符串,也没出现什么问题。那是因为
ASCII 里没有对应的特殊字符,所以正则表达式编译器能够知道你指的是一个十进制数字
######################
re模块的常用方法
re.compile(strPattern[, flag])
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags])
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags])
>>> import re
>>> s = \'hello world\'
>>> print(re.match(\'ello\', s))
None
>>> print(re.search(\'ello\',s ))
<_sre.SRE_Match object; span=(1, 5), match=\'ello\'>
说明:可以看到macth只匹配开头,开头不匹配,就不算匹配到,search则可以从中间,只要能有匹配到就算匹配
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。有点像search的扩展,把所有匹配的子串放到一个列表
参数:同match
返回值:所有匹配的子串,没有匹配则返回空列表
>>> import re
>>> s = \'one1two2three3four4\'
>>> re.findall(\'\\d+\', s)
[\'1\', \'2\', \'3\', \'4\']
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
>>> import re >>> s = \'one1two2three3four4\' >>> re.split(\'\\d+\',s) [\'one\', \'two\', \'three\', \'four\', \'\']
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count])
if __name__ == \'__main__\':
import re
s = \'--(1.1+1+1-(-1)-(1+1+(1+1+2.2)))+-----111+--++--3-+++++++---+---1+4+4/2+(1+3)*4.1+(2-1.1)*2/2*3\'
def replace_sign(expression):
\'\'\'
替换多个连续+-符号的问题,例如+-----,遵循奇数个负号等于正否则为负的原则进行替换
:param expression: 表达式,包括有括号的情况
:return: 返回经过处理的表达式
\'\'\'
def re_sign(m):
if m:
if m.group().count(\'-\')%2 == 1:
return \'-\'
else:
return \'+\'
else:
return \'\'
expression = re.sub(\'[\\+\\-]{2,}\', re_sign, expression)
return expression
s = replace_sign(s)
print(s)
执行结果
24 +(1.1+1+1-(-1)-(1+1+(1+1+2.2)))-111+3-1+4+4/2+(1+3)*4.1+(2-1.1)*2/2*3
四.冒泡
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
li = [1,2,33,55,2,77,6,88,9,25]
l = len(li)
冒泡排序
print(l)
for i in range(len(li)):
# print(li[i])
for j in range(l):
if li[i] > li[j]:
tmp = li[i]
li[i] = li[j]
li[j] = tmp
print(li)
#[88, 77, 55, 33, 25, 9, 6, 2, 1]
#选择排序 # #index # max_index = 0 # for j in range(len(li)): # for i in range(len(li)-j): # # print(i,li[i]) # # for j in range(l): # if li[i] > li[max_index]: # max_index = i # print(max_index) # # print(l-i) # # tmp = li[len(li)-j-1] # li[len(li)-j-1] = li[max_index] # li[max_index] = tmp # print(li[len(li)-1]) # print(max_index) # print(li)
以上是关于day6 反射,hashlib模块,正则匹配,冒泡,选择,插入排序的主要内容,如果未能解决你的问题,请参考以下文章