关于线性模型你可能还不知道的二三事(二也谈民主)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于线性模型你可能还不知道的二三事(二也谈民主)相关的知识,希望对你有一定的参考价值。
目录
1 如何更新权值向量?
2 最小均方法(LMS)与感知机:低效的民主
3 最小二乘法:完美的民主
4 支持向量机:现实的民主
5 总结
6 参考资料
1 如何更新权值向量?
在关于线性模型你可能还不知道的二三事(一、样本)中我已提到如何由线性模型产生样本,在此前提下,使用不同机器学习算法来解决回归问题的本质都是求解该线性模型的权值向量W。同时,我们常使用线性的方式来解决分类问题:求解分隔不同类别个体的超平面的法向量W。不论回归还是分类,都是求解向量W,而求解的核心思想也英雄所见略同:向量W倾向于指向某些“重要”的个体。然而哪些个体是重要的呢?不同的机器学习算法有不同的定义。
2 最小均方法(LMS)与感知机:低效的民主
最小均方法(LMS)使用的随机梯度下降法与感知机的训练法则类似,两者都是迭代更新的方式。假设本次迭代中的权值为W,那么更新后的权值W‘为(eta为更新率):
随机梯度下降法:
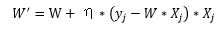
感知机:
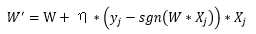
通过观察可知,权值更新是一个迭代的过程,不论是回归(最小均方法)还是分类(感知机),权值更新时视当前轮次中误差大的个体为“重要”的个体。这种权值更新办法比较直观,但是同时也比较低效:人人都有发言的权利,每次只考虑部分人,容易顾此失彼。
3 最小二乘法:完美的民主
二乘即是平方,最小二乘法旨在于求解权值向量W使得误差平方和最小:
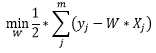
通过对权值向量的每个分量进行求导可得:
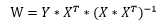
至此,我们可以发现最小二乘法可解的条件为特征矩阵X是可逆的。假设特征矩阵X的样本容量n=m,那么上式进一步化简得:
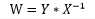
使用求解出来的权值向量W‘对未知个体x‘进行预测,本质就是计算:
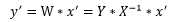
在《关于线性模型你可能还不知道的二三事(一、样本)》中我们已经揭开了特征矩阵X的逆矩阵的意义,因此以上的计算过程可以概括为:首先使用X的逆矩阵乘以未知个体x‘,得到可以准确描述未知个体x‘与特征矩阵X中已知个体相似度的列向量,然后以此为基础,使用加权求和的方法来计算未知个体x‘的目标值。
到此,最小二乘法所诠释的完美民主已显见:在每个人都不能由其他人代表的前提下,看未知的个体与谁更相似,那么目标值也与之更相似。
没错,之前我们假设了特征矩阵X的样本容量n=m,但是大多数情况下n是大于m的。这种情况下权值向量计算公式无法进一步化简。同样在《关于线性模型你可能还不知道的二三事(一、样本)》中我们提到,可以转化原问题为:
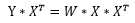
这时,我们可以设新的特征矩阵X‘和新的目标值向量Y‘为:
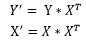
到此,新的特征矩阵X‘是m×m的方阵,可以求其逆矩阵了(当然,这还是在原特征矩阵的秩等于m的前提下)。因此有:
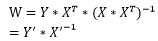
不难看到,上式同样也是诠释了完美的民主,只是特征矩阵X变成了X‘,目标值向量Y变成了Y‘而已。
4 支持向量机:现实的民主
完美的民主可遇而不可求,如果特征矩阵X的秩小于m呢?此时最小二乘法便不奏效了。我们期望无论特征矩阵X的秩是否小于m,仍然可以高效地求解权值向量W。
我们可以利用支持向量机解决该问题。不妨直接看到权值向量的最终结果(具体推导可参考《支持向量机通俗导论(理解SVM的三层境界)》):
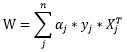
使用上式计算出来的权值向量W对未知个体x‘进行预测的原理是显见的:首先将未知个体与特征矩阵X中的个体相乘得到对应的相似度,然后以此相似度乘以alpha的分量,最后在此基础上以加权求和的方法来计算未知个体x‘的目标值。然而,alpha到底是什么呢?
对支持向量机有一定了解的同学肯定会有一个基本的认识:支持向量为间隔边界上的点,相对应的alpha的分量为0。也就是说,最终的权值只会考虑作为支持向量的样本!然而,进一步,很少有人会去思考:间隔边界上的点都是支持向量吗?支持向量所对应的alpha的分量值大小服从什么规律吗?支持向量为什么叫支持向量呢?
我们通过一个简单的例子来进一步解答以上的问题,首先生成特征矩阵X和目标向量y:
1 import numpy as np 2 from sklearn.svm import SVC 3 from matplotlib import pyplot as plt 4 5 X1_positive_border = np.random.uniform(-10, 10, size=10) 6 X2_positive_border = X1_positive_border + 1 7 X_positive_border = np.hstack((X1_positive_border.reshape(-1,1), X2_positive_border.reshape(-1,1))) 8 9 X1_positive = np.random.uniform(-10, 10, size=10) 10 X2_positive = X1_positive + np.random.uniform(2, 10, size=10) 11 X_positive = np.hstack((X1_positive.reshape(-1,1), X2_positive.reshape(-1,1))) 12 13 X1_negative_border = np.random.uniform(-10, 10, size=10) 14 X2_negative_border = X1_negative_border - 1 15 X_negative_border = np.hstack((X1_negative_border.reshape(-1,1), X2_negative_border.reshape(-1,1))) 16 17 X1_negative = np.random.uniform(-10, 10, size=10) 18 X2_negative = X1_negative + np.random.uniform(-10, -2, size=10) 19 X_negative = np.hstack((X1_negative.reshape(-1,1), X2_negative.reshape(-1,1))) 20 21 X = np.vstack((X_positive_border, X_positive, X_negative_border, X_negative)) 22 y = np.hstack((np.ones(20), -np.ones(20)))
使用线性核的SVC进行训练:
1 model = SVC(C=0.1, kernel=‘linear‘) 2 model.fit(X, y)
对训练的结果绘图:
1 #绘制边界正例 2 plt.plot(X_positive_border[:,0], X_positive_border[:,1], ‘g.‘, markersize=12, label=‘Positive X At Border‘) 3 #绘制正例 4 plt.plot(X_positive[:,0], X_positive[:,1], ‘g^‘, markersize=12, label=‘Positive X‘) 5 #绘制边界反例 6 plt.plot(X_negative_border[:,0], X_negative_border[:,1], ‘r.‘, markersize=12, label=‘Negative X At Border‘) 7 #绘制反例 8 plt.plot(X_negative[:,0], X_negative[:,1], ‘rv‘, markersize=12, label=‘Negative X‘) 9 #绘制正边界 10 plt.plot(np.arange(-10, 11), np.arange(-10, 11) + 1, ‘c--‘) 11 #绘制超平面 12 plt.plot(np.arange(-10, 11), np.arange(-10, 11), ‘k-‘) 13 #绘制负边界 14 plt.plot(np.arange(-10, 11), np.arange(-10, 11) - 1, ‘m--‘) 15 #绘制座标轴 16 plt.plot(np.arange(-10, 11), np.zeros(21), ‘k-‘) 17 plt.plot(np.zeros(41), np.arange(-20, 21), ‘k-‘) 18 #给每个支持向量进行标注 19 for i in range(len(model.support_vectors_)): 20 x = model.support_vectors_[i] 21 a = model.dual_coef_[0][i] * y[model.support_[i]] 22 plt.annotate(‘a[%d]=%.2f‘ % (i, a), xy=(x[0], x[1]), xytext=(x[0]-1, x[1]+1), arrowprops=dict(arrowstyle="->",connectionstyle="arc3"))23 24 plt.legend(loc=‘best‘, shadow=True) 25 plt.show()
显示结果如下:
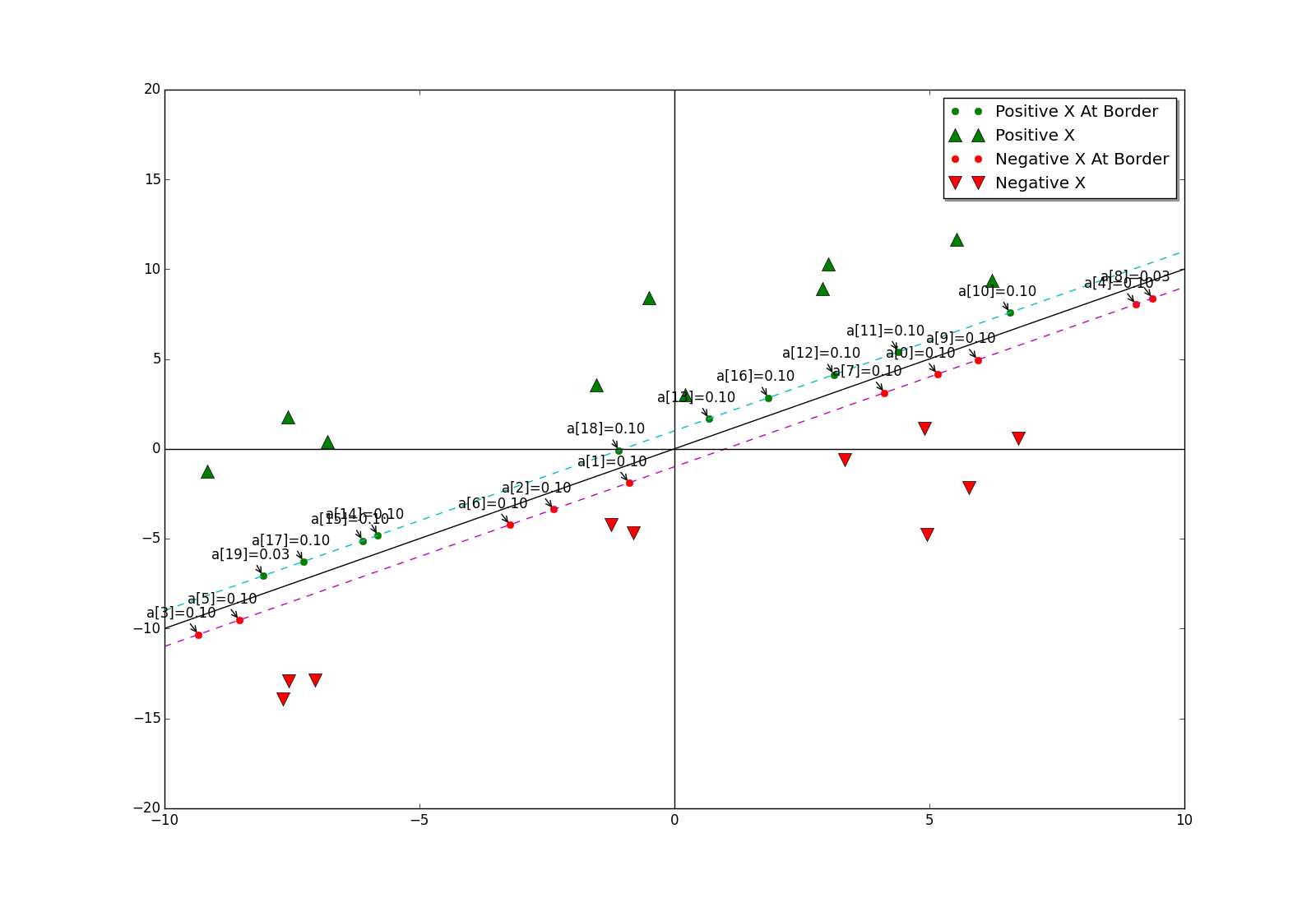
我们可以看到,当参数C=0.1时,边界上几乎所有的点都是支持向量。再设C=1.0时,显示结果如下:
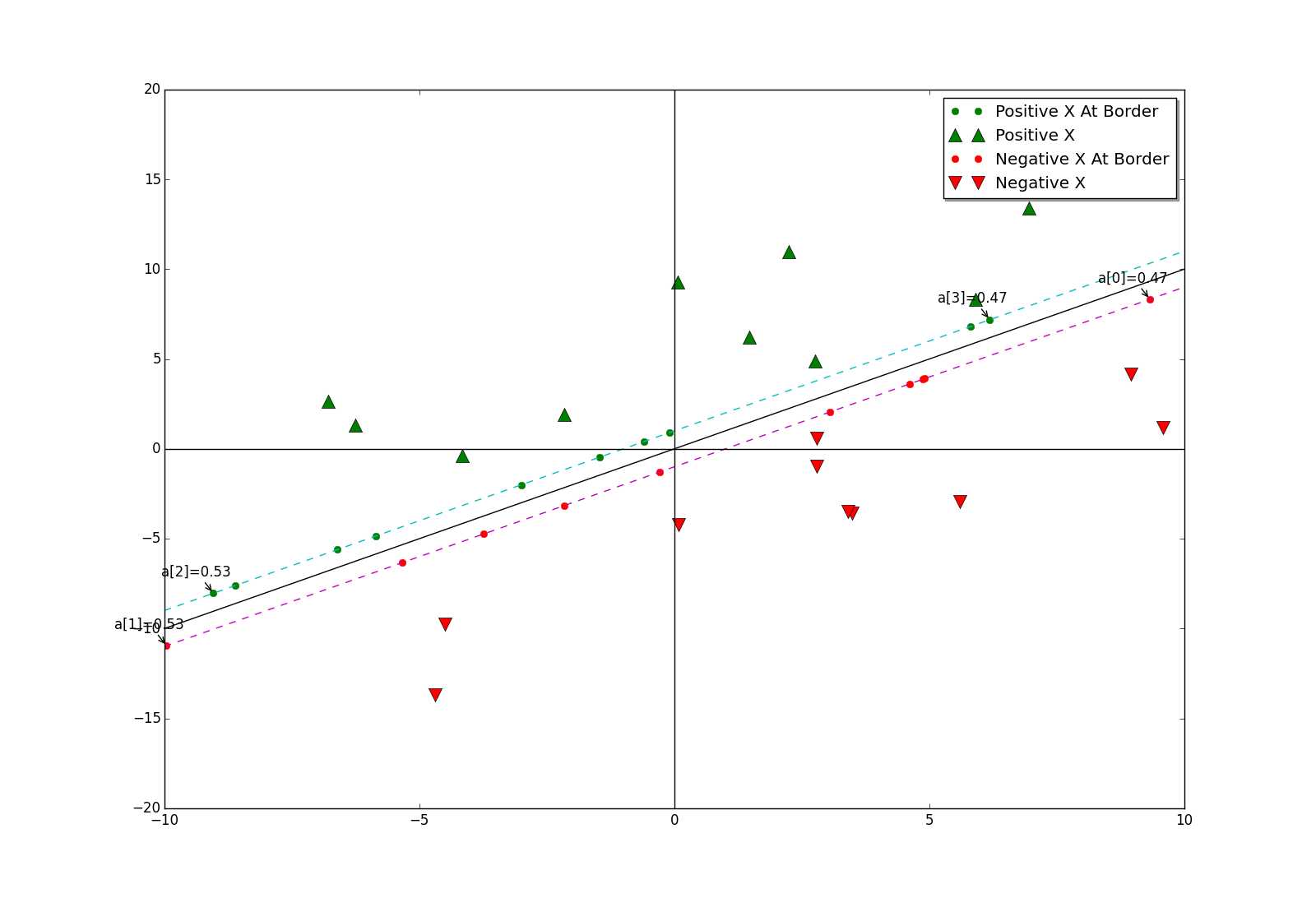
此时,只有少数边界上几个点是支持向量了。参数C的变化为什么会影响支持向量的个数呢?官方文档中对参数C的说明是惩罚系数,不同于对权值向量的惩罚,这里的惩罚是针对于alpha的。C越大,惩罚就越大,那么alpha的非零项就越少。当边界上只有少数点为支持向量时,通常来说,边界上靠近两端的点更适合作为支持向量,例如上图中的a[0]至a[3]。如何解释呢?
先看负边界上靠近两端的点,当它们与目标向量y的分量(值为-1,反向)相乘后,相当于正边界上的点。正边界上,对靠近两端的点进行向量求和,这样便可方便得到超平面的法向量,即权值向量。通俗一点说,靠近两端的点都是一些特色的点(不能被其他点代表),其他点可以由这些有特色的点的线性表示。或者更通俗一点来说,靠近两端的点可以看成是各行各业的先进人士,由于职业不同,他们都不能被彼此代表,但是他们可以代表自己的行业的其他人,他们的组合甚至可以代表一些跨行业的人!
此时,我们可以引出结论:支持向量机代表的是一种现实的民主,我国的人民代表大会制也是如此。
最后,我们还需要回答一个显见问题,支持向量的名称由来:一组能够”撑起“分隔边界的向量。
5 总结
这次,我们探讨了3种常见的线性模型权值向量求解思路。从LMS和随机梯度下降到最小二乘,再到支持向量机,人们求解自然科学问题的思路与求解社会科学问题的思路走到了一起。最近的一件小事带给我启发:居住的小区需要对某一些问题进行决策,一开始由热心居民每家每户听取意见,结果迟迟拿不定主意,越听越糊涂。到最后,只好选出业主委员会,由业主委员会代表各个特色群体,问题才得以解决。
之前对线性模型的权值求解过程和结果都“记得”非常熟悉,但是其真正意义(特别是最小二乘)没有去深究。而这次能够受到启发,并且联系到现实生活中,也算是对线性模型有了更进一步的认识吧。
6 参考资料
以上是关于关于线性模型你可能还不知道的二三事(二也谈民主)的主要内容,如果未能解决你的问题,请参考以下文章