大数据开发认知--架构
Posted levyxu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据开发认知--架构相关的知识,希望对你有一定的参考价值。
1、hadoop 工作原理:
a.首先 概括里面的角色(HDFS 、Mapreduce)
b.讲解各个角色的整体架构
HDFS:
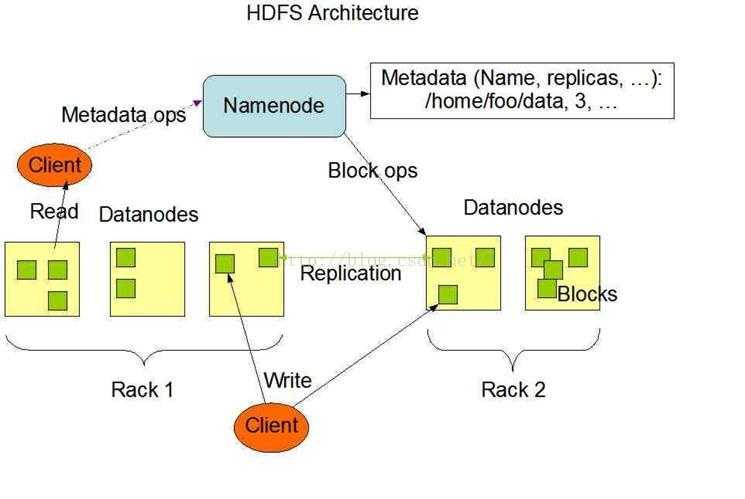
概念:
分布式文件系统,用于海量数据存储。
架构:
master/slave 架构 :1个Namenode和多个Ddatanode。
工作原理:
Namenode:(项目管理)
Namenode是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表, 接收用户的操作请求。
文件包括:
fsimage: 元数据镜像文件。存储某一时段NameNode内存元数据信息(block起始位置与结束位置)。
edits: 操作日志文件。
fstime: 保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中。通过hdfs-site.xml的dfs.namenode.name.dir属性进行设置。
Datanode:(coder)
1. 提供真实文件数据的存储服务。
2.文件块( block): 最基本的存储单位。
3.对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。 HDFS默认Block大小是128MB, 因此,一个256MB文件,共有256/128=2个Block.
4.与普通文件系统不同的是,在 HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
5.Replication:多复本。默认是三个。通过hdfs-site.xml的dfs.replication属性进行设置。
Namenode和Datanode的交互:
主要是读写操作,可以参考:http://www.mamicode.com/info-detail-667421.html
HDFS 如何保证数据安全性简单说下
应用场景:
Mapreduce 工作原理:
应用场景:适合处理海量离线批处理数据
Yarn 工作原理:
Hive 面试题:
0. 它最常见的应用场景:
离线统计分析(非实时的)
1. 为什么 hive 延迟高?
底层与基于mapreduce 框架 会频繁的进行IO读写
2. hive 数据倾斜怎么解决?
数据倾斜很大程度发生于Mapreduce shuffle阶段
Map端:
如果发生倾斜,通过不去解决。也无法解决,甚至无法避免。
Reduce端:
如果发生倾斜 离线集群中的key。如果有groupby语句的话 有个属性可以设置 set xxx=true
3. HQL 里那些字段会作为key?
a. on 条件字段
b. group by 字段
c. count(distincit 字段)
4. 你写过什么比较复杂的业务逻辑语句?
考你的业务
调度系统(Zeus):
Hbase 应用场景:
特点:
在线高频读写,查询时需要毫秒级返回。
缺点:
无法做统计分析类场景。
Hive-hbase接口表:遇到扫描问题?
从hive里面的查询的时候 没有不经过rowkey 导致查询性能差,堵塞IO,造成Hbase 侧查询不稳定
二级索引设计:
场景再现:使用hbase 过程中遇到的问题?
开始的时候 hbase 二级索引使用的不好导致很多表不能重用,覆盖的场景较少,不得不去增加数据存户等
Hbase 表类型:
业务表:
以业务ID(倒序)为rowkey 数据可以供任务地方使用
例如:
比如订单表
rowkey(倒序订单ID) 字段1,字段2,字段3...
二级索引表:
NOTE:
如果涉及业务表的时候,把业务数据和二级索引混合在一起,这张表就报废!!
查询场景:
索引表1 rowkey 是组合条件 无字段
索引表2 rowkey 是组合条件 无字段
索引表3 rowkey 是组合条件 无字段
以上是关于大数据开发认知--架构的主要内容,如果未能解决你的问题,请参考以下文章