模块与包
Posted 独角兕大王
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模块与包相关的知识,希望对你有一定的参考价值。
一、模块
-
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀,但其实import加载的模块分为四个通用类别:
- 使用python编写的代码(.py文件)
- 已被编译为共享或DLL的C或C++扩展
- 包好一组模块的包
- 使用C编写并链接到python解释器的内置函数
-
如果你退出Python解释器然后再进入,那么你之前定义的函数或变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python 文件.py ,此时执行的文件就叫做script。当文件脚本很多时,我们将程序分成一个个文件,这样程序的结构就更清晰,方便管理,这时我们不仅仅可以把这些文件当成脚本文件,还可以把他们当作模块来导入到其他模块,实现功能的重用
-
使用模块: 我们可以从sys.modules中找到当前已经加载的模块
-
模块的导入相当于执行了整个文件
-
一个模块不能被多次导入,一旦导入原文件中的修改也不会生效,且各个模块的变量于本模块不冲突
x#测试一:money与my_module.money不冲突import my_module # 默认有以下属性money=10print(my_module.money) #属性和方法都可以my_moudle.方法()my_moudle.read()\'\'\'执行结果:from the my_module.py1000\'\'\'import my_moudle # 次文件中有print(\'123\')import my_moudle# 打印一个 123 -
一个模块不会被多次执行,只执行一遍,再两个模块相互调用时要分清。:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载大内存中的模块对象增加了一次引用,不会重新执行模块内的语句。
-
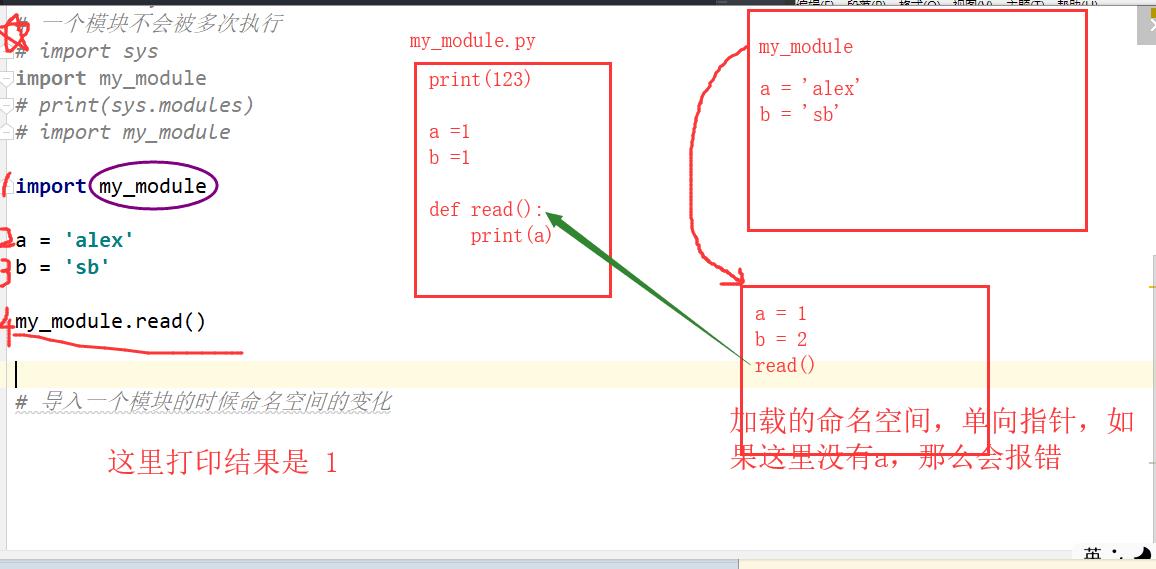
导入一个模块的时候命名空间的变化:
- 创建了一个要导入模块的命名空间
- 创建一个变量指向这个命名空间,其实相当于加载文件类(个人理解)
- 执行这个文件,注意这个关系是单向引用,也就是说,如果不是函数传参的形式,是不能把本文件的变量a传给模块中的变量a
-
模块虽然一行可以导入多个,但是不推荐这样使用。如:import time,os,random,my_module
-
as语法的使用:
xxxxxxxxxx#1、time这个名字就失效的,只剩下t了import time as tt.time()#2、用来做兼容,当要根据判断取模块时,我们可以先判断,再以同样的as名字mode = \'pickle\' #不确定是 json还是 pickleif mode == \'pickle\':import pickle as modeelse:import json as modedef dump():mode.dump(obj,f)def load():mode.load(f)#其他用法:#1from my_module import read1 as read#2from my_module import (read1,read2,money) 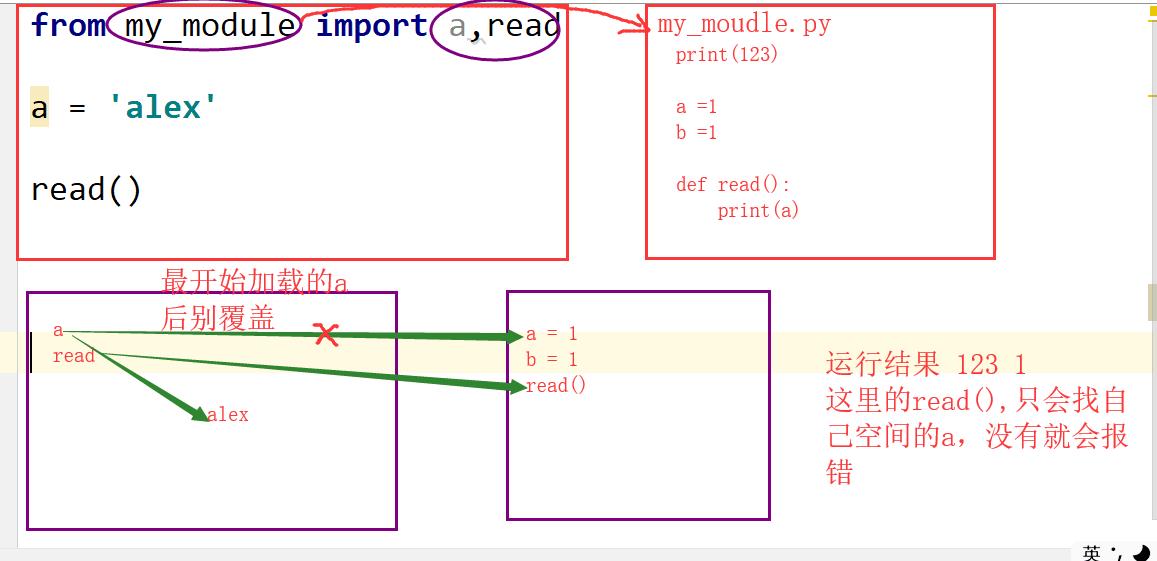
-
from …… import ……from 语句相当于import,也会创建新的名称空间,但是将my_module中的名字直接导入到当前的名称空间中,在当前名称空间中,直接使用名字就可以了
xxxxxxxxxx#1测试一:导入的函数read1,执行时仍然回到my_module.py中寻找全局变量moneyfrom my_module import read1money=1000read1()\'\'\'执行结果:from the my_module.pyspam->read1->money 1000\'\'\'#测试二:导入的函数read2,执行时需要调用read1(),仍然回到my_module.py中找read1()from my_module import read2def read1():print(\'==========\')read2()\'\'\'执行结果:from the my_module.pymy_module->read2 calling read1my_module->read1->money 1000\'\'\'#测试三:导入的函数read1,被当前位置定义的read1覆盖掉了from my_module import read1def read1():print(\'==========\')read1()\'\'\'执行结果:from the my_module.py==========\'\'\'#from my_module import * 把my_module中所有的不是以下划线(_)开头的名字都导入到当前位置,大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题#在my_module.py中新增一行:__all__=[\'money\',\'read1\']#这样在另外一个文件中用from my_module import *就这能导入列表中规定的两个名字#__all__=[] 和 * 配合使用#补充:#如果my_module.py中的名字前加_,即_money,则from my_module import *,则_money不能被导入
-
二、模块导入的三大问题
-
模块的搜索路径:
-
python解释器在启动时会自动加载一些模块,可以使用sys.modules查看,在第一次导入某个模块时(比如my_module),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用.如果没有,解释器则会查找同名的内建模块,如果还没有找到就从sys.path给出的目录列表中依次寻找my_module.py文件。
xxxxxxxxxx#1、所以总结模块的查找顺序是:内存中已经加载的模块 -> 内置模块 -> ys.path路径中包含的模块#2、需要特别注意的是:我们自定义的模块名不应该与系统内置模块重名#3、搜索时按照sys.path中从左到右的顺序查找,位于前的优先被查找,sys.path中还可能包含.zip归档文件和.egg文件,python会把.zip归档文件当成一个目录去处理。在pycharm中会自动为我们加载本地路径import syssys.path.append(\'/a/b/c/d\')sys.path.insert(0,\'/x/y/z\') #排在前的目录,优先被搜索
-
-
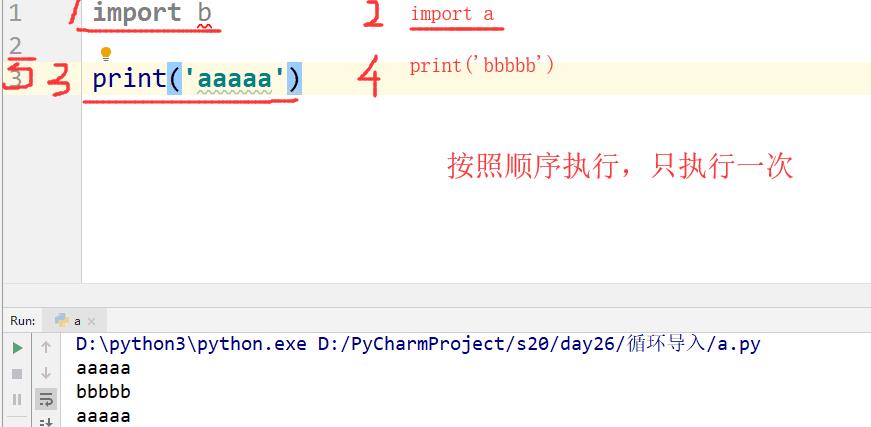
模块能不能被循环导入:
-
xxxxxxxxxx#能不能 在 a.py import b#在 b.py import a# 以主程序为主,加载顺序从上至下,可引用 
-
把模块当做脚本执行:
-
当做脚本运行:
__name__ 等于\'__main__\':__name__等于模块名xxxxxxxxxxdef fib(n):a, b = 0, 1while b < n:print(b, end=\' \')a, b = b, a+bprint()if __name__ == "__main__": #只有在当前文件下执行,如果是模块调用则不会执行print(__name__)num = input(\'num :\')fib(int(num))
-
三、包
-
包是一种通过使用\'模块名\'来组织python模块名称空间的方式。
-
无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警觉:这是关于包才有的导入语法
-
包是目录级的(文件夹级),文件夹是用来组成py文件(包的本质就是一个包含
__init__.py文件的目录 -
import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的
__init__.py,导入包本质就是在导入该文件 -
在python3中,即使包下没有
__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错 -
创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包即模块
-
import 包:相当于执行了这个包下的init文件
-
具体使用:
xxxxxxxxxximport glance.api.policy as policy #假设glance是包,api是文件,policy是py文件 用别名policy.get()#也可以:import glance.api.policy.get() 但是太长了,每个都要写# 根据包的导入要精确到模块名,不能精确到具体的函数或者变量,然后使用glance.api.policy或者重命名的方式,来使用这个模块中的所有名字#from……import 在包中的用法from glance.api import policy #import后面不能有. 且至少要精确到模块policy.get()#orfrom glance.api.policy import getget()#使用from……import import后面至少是精确到模块的,import后面不能有。from后面可以有.,但是.的左边永远是包名#import 直接导入包时,再导入时执行了包中的__init__.py文件(类似于实例化),我们可以在__init__.py中写相应的路由,假如我想直接import 一个包,就需要配置__init__.py文件:# 1、现在glance(包)中的__init__.py,需要配置: -
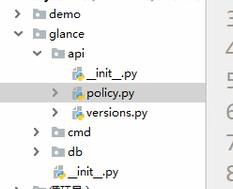
__init__.py文件:不管是哪种方式,只要是第一次导入包或者是包的任何其他部分,都会依次执行包下的init.py文件(我们可以在每个包的文件内都打印一行内容来验证一下),这个文件可以为空,但是也可以存放一些初始化包的代码
-
首先要想使用import glance 里面的如api下的policy中的方法,先配置glance文件下的
__init__.pyxxxxxxxxxx# /glance/__init__.pyfrom glance import apifrom glance import cmdfrom glance import db # 此时在包外一个文件import glance,可以调用api,cmd,db,但是还不能导入其中的具体方法#test/my_moudleimport glanceprint(glance) # <moudle \'glance\' from \'D:\\\\\'>print(glance.api) #<moudle \'glance.api\' from \'D:……>print(glance.api.policy) #不行 如何解决,因为没有在api文件的init中配置路径#此时在api/__init__.py中输入from api import policy # 之后再运行还是报错,问题出在from api这里,找不到api,这时候可以通过sys.path 查看路径,显示只能查看能找到glance,也就是说能执行glance中的__init__.py文件,但是不能执行api中的init文件,所以这里有两种方法解决这个问题:#方案一: 在api文件中的__init.py文件中添加路径import syssys.path.append(r\'D:\\……\\glance\') #将glace文件加载到系统路径中,于是会查找其中的各个文件from api import policy # 导入glance后,api文件就会被找到,一层一层的from api import versions#此时api文件下的文件都可以使用了,但是如果要导入cmd文件下的文件,就还需要在它文件下的init文件做同样的处理。麻烦#方案二:绝对路径,不需要添加路经,使用绝对导入、#/glance/api/__init__.pyfrom glance.api import policy #效果相同,不需要让api的上一级成为环境变量中from glance.api import versions#总结: 在包中的__init__.py文件中的就是在import时要执行的文件,各级子文件的__init__.py文件最好使用绝对导入,这样,想导入的时候才能找到
-
五、绝对导入和相对导入
-
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
xxxxxxxxxx#在glance/api/version.py#绝对导入from glance.cmd import managemanage.main()#相对导入from ..cmd import managemanage.main()#可以用import导入内置或者第三方模块(已经在sys.path中),但是要绝对避免使用import来导入自定义包的子模块(没有在sys.path中),应该使用from... import ...的绝对或者相对导入,且包的相对导入只能用from的形式。 -
单独导入包:单独导入包名称时不会导入包中所有包含的所有子模块
x
#在与glance同级的test.py中import glanceglance.cmd.manage.main()\'\'\'执行结果:AttributeError: module \'glance\' has no attribute \'cmd\'\'\'\'#解决办法: 规划路经,使用__init__.py,__all__是用于控制from...import *#glance/__init__.pyfrom . import cmd#glance/cmd/__init__.pyfrom . import manage#执行#在于glance同级的test.py中import glanceglance.cmd.manage.main()
六、软件开发规范
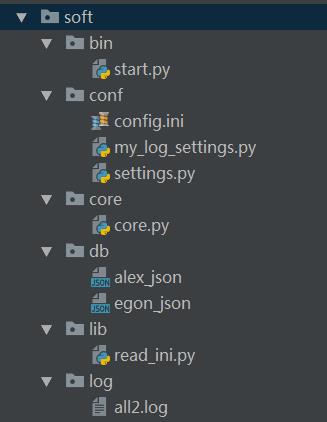
七、补充:
x
# 同一大文件下(项目目录),如何导入各个小文件中的py文件的导入: __file__:当前文件路径
#项目开始的文件中导入
import os
start_path = __file__
bin_path = os.path.dirname(start_path) # 翻一层
project_path = os.path.dirname(bin_path) # 再翻
sys.path.append(project_path) # 添加路径,可以迁移文件
#规定
Base_path = os.path.dirname(os.path.dirname(__file__))
sys.path.append(project_path)
#注意的是:在每个模块的开头,需要导入时,都需要使用from 父目录 import ……,也就是说现在项目的所有小目录能找到,所以,我们的子目录都是要记录这些小目录开始 from。