模式识别(Pattern Recognition)学习笔记(二十八)-- 决策树
Posted eternity1118_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模式识别(Pattern Recognition)学习笔记(二十八)-- 决策树相关的知识,希望对你有一定的参考价值。
1.数值特征与非数值特征
学习分类这么久,不知道大家有没有注意一个问题,那就是我们的输入样本数据都是基于数值计算的,因此在近邻法中才可以计算距离这一说,这种可以用数值来描述的对象特征,我们称之为数值特征,但是在我们生活中所涉及的分类问题并非都是用数值特征来描述某个研究对象的,因此与数值特征对应的就是非数值特征,比如男生和女生比较喜欢什么样的颜色等等。
关于非数值特征,主要有以下几种:
1)名词特征:像性别、职业等,这类特征不能比较大小,也不能比较相似性,只能比较相同或不相同;
2)序数特征:像序号、等级等,这类特征虽然本身也是数值,但是却不能彼此计算欧氏距离,而且他们之间可能存在一定顺序;
3)区间特征:像年龄、一门科目的考试成绩等,这类特征它们自身也是数值,但是会存在一个固定的区间段,它们可以比较大小,但是没有多大意义;
因此,当一个实际问题需要使用上述几种非数值特征进行描述时,在使用模式识别方法分类决策时,第一步要做的就是对非数值特征进行数值化,即编码:
1)对名词特征的编码:比如对性别的分类,就可以将男编码为0,女编码为1;这种做法是为了防止人为引入特征元素之间并不存在的相对关系,叫做正交编码,缺点是有时候会使得特征维数增加;
2)对序数特征的编码:比如对一件事故的定性,分为一般事故(一级)、较大事故(二级)、重大事故(三级)和特大事故(四级)四个等级,可以同名词特征相似的编码方式,用四个二值来表示:00,01,10,11,这种编码的缺点是可能会损失层级之间的关系信息,当然还可以根据专业人员对事件的打分来数值化,但是很明显这种做法掺杂了人为因素;
2)对区间特征的编码:比如考试成绩,可以根据需要划定一个界限(即阈值),将考试成绩分为及格和不及格,再对应成二值0和1;也可以划定多个界限将考试成绩变成序数特征;最好的处理方式是引入模糊量,可以很好地反映数据信息;
可以看到,对于上述非数值特征的这种间接处理,都不可避免的带入人为因素,而且会丢失部分数据信息,与其这样倒不如对这些非数值特征直接处理呢,那到底能不能直接使用呢?答案是肯定的,于是决策树华丽丽的来了。。
2.初识决策树
为了更好的理解什么是决策树,我们先来看一个场景。前不久,微软小冰跟主人玩了这样一个游戏,游戏是这样的:首先主人先丢出一个问题,如‘我最喜欢的明星是谁?’;然后小冰会通过不断的问你问题(至多不超过18问),她就能惊人的正确答出你的每一个问题,哈哈,不知道有没有人玩过,反正我是觉得还挺好玩的,每次都能答对。来来来,我们来还原下游戏场景:
我:我最喜欢的明星是谁?
小冰:Ta是男是女?
我:男
小冰:国内的还是国外的?
我:国内的
小冰:内地的还是港台的?
我:港台的
小冰:他有很多歌曲么?
我:是的
小冰:他开过演唱会么?
我:开过
小冰:。。。。(后面的我就省略了,反正我每次都数了下,问我十次她就给出正确答案了)
好辣,让我们回到决策树上来,其实小冰的每一次提问都是一次决策,多次提问就组成了完整的决策过程,这一决策过程可以用一个树状结构图来表示:
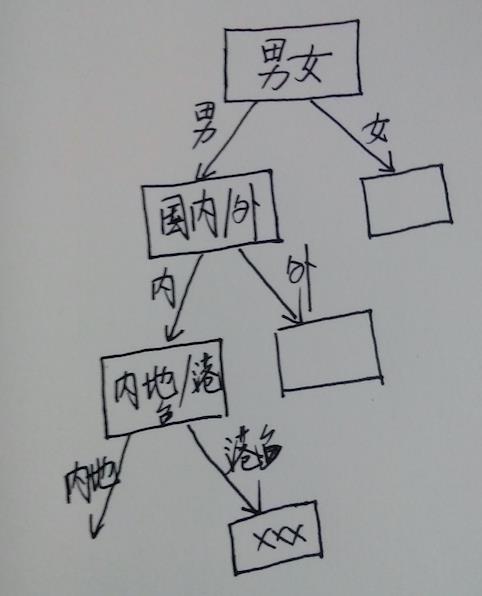
这样的决策过程,相信你在生活中以及各个行业都经常见到,比如医学诊断、工业上的故障诊断、证券分析等;可以说在我们的日常生活中,无时不刻不在进行着这样的决策,比如我今天要吃什么,穿什么,这一树状决策过程,大多是根据相关的专业知识或多年积累的经验常识来进行的,而对于所谓的决策树(Decision Tree)而言,他也在进行着与人类似的行为,人类根据自己做掌握的经验知识来决策,而对于决策树来说就是我们要喂给它一定数量的训练样本,然后它再从这些样本数据中“学习”出决策规则(这个规则就是它学习到的经验知识),最后利用学到的经验知识来构造出决策树。
上图中看出,决策树其实是由一系列节点组成,每一个节点代表一个特征与对应的决策规则,位于顶部的节点是根节点,此时所有的样本都在一起,经过该节点之后就被划分到各个子节点中,然后每个子节点再用新的特征来新一轮决策,直到到达最后的叶节点,在叶节点上,每一个叶节点只包含单一类的样本,因此无须再划分。所以上述过程中,决策树的构建过程其实就是选取关键代表性特征(为了简化决策,需要找到最有代表性的特征来作为根节点特征)和确定恰当的决策规则的过程,而且可以看做一个两类问题的分类。
3.深入决策树
下面,为了阐述明白决策树的构建原理,我们通过一个例子来表达,假定某推销员根据自己多年推销经验知道,消费者是否会买车,与其年龄、性别和收入关系最大。然后该推销员搜集了某一个月里面光顾4S点咨询汽车信息的消费者资料,整理成了下表:

上图这个表格就是训练样本集,目标任务就是构造一个能够准确估计出消费者是否会买车的决策树;
接下来,进行数据的清洗:将年龄分为两个阶段:小于30和30岁以上;收入分为三个档次:3000以下(低)、3000-6000(中)、6000以上(高);清洗工作完成后,训练样本数据变成了下面这样: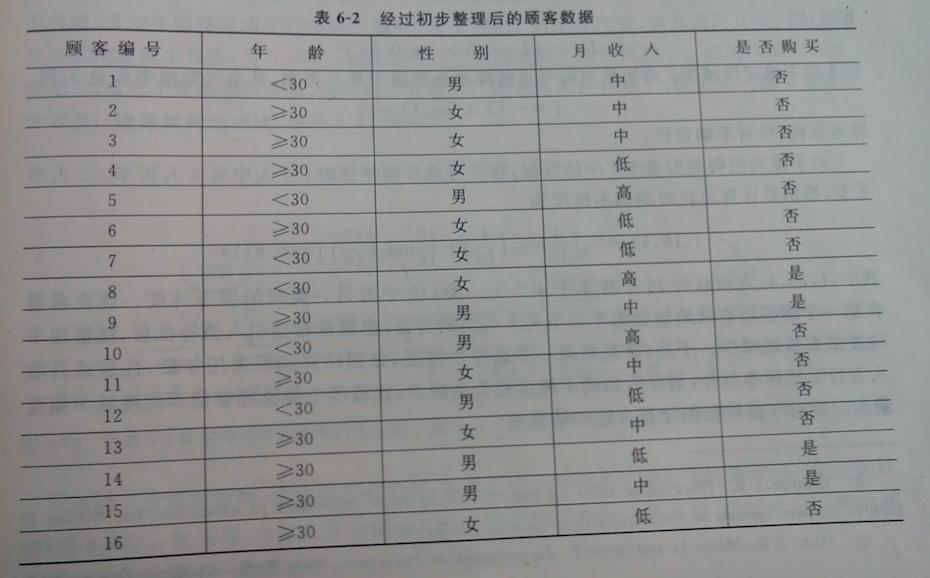
针对上面的例子,这里介绍几种比较出名的构建决策树的方法:ID3方法、C4.5算法;
3.1ID3算法
ID3(Interactive Dichotomizer-3),中文名字叫做交互式二分法,注意,不要被它的名字欺骗了,虽然名字上有二分法,但是它也同样适用于每个节点下划分多个子节点的情况。该方法的原型是Hunt等人提出的概念学习系统(Concept Learning System),通过选择那些具有代表性和辨别力的特征对样本数据进行划分,直到每个叶节点上只包含单一类的数据为止。
该算法依据的基础理论是通信和信息论中的香农熵(Entropy),在信息论中,熵是接收的每条消息中包含的信息的平均量,又称作信息熵、平均自信息量,而通俗的理解就是,熵是信源不确定性的量度,一个信源越是随机其熵就越大,在信息论中我们通常用概率分布来表示一个信源的特征之一,因此慢慢的当人们面对一个不确定性事件或是随机事件时,都可以利用熵这一概念来度量事件的不确定性。
如果一个事件有n种可能的结果,每种结果对应的概率为Pi,i=1,2,...,n,那么我们对此事件的结果进行观察后得到的信息量就可以用熵来度量:
(1)
即熵是概率分布的对数的相反数;
对于某个节点上的样本,我们将上述熵定义为熵不纯度,它反映了该节点上的特征对样本分类的不纯度(impurity),其值为零时,表示样本没有不确定性,纯度最高;值越大表明不确定性越高。
现在针对我们的例子来计算下熵不纯度:
在不考虑任何特征时,可以根据样本出现的比例来作为对概率的估计,16人中有4人买车,因此其熵不纯度为:
(2)
接下来我们的工作是要找到一个具有高辨别度和代表性的特征,可以很好的将买车和不买车区分开,即该特征划分的样本使得样本的熵不纯度可以减小,怎么做呢,没有更好的办法,只能逐一计算三个特征(年龄、性别和收入)划分后的样本的熵不纯度,然后将三个值分别与公式(2)中的结果进行比较,看哪个特征能够将公式(2)中的而结果减小的幅度最大,就采用那个特征作为最先划分的特征(根节点的特征)。
一般来说,如果某特征把N个样本划分为m组,每组Nm个样本,则不纯度减少量的额计算公式为:
其中,;
1)年龄:根据样本分布知道,16人中30岁以上有10人,其中3人买车,而30岁以下有6人,其中只有1人买车,于是以年龄为特征进行划分后的熵不纯度为:
因此减小幅度(信息增益)为:0.8113-0.7946=0.0167
2)性别:16人中有男7个,其中3人买车,而有女9个,其中1人买车,于是以性别为特征进行划分后的熵不纯度为:
因此减小幅度(信息增益)为:0.8113-0.7141=0.0972
3)收入:16人中低等收入有6个,其中1人买车;中等收入有7个,其中2人买车;高等收入有3个,其中1人买车,于是以收入为特征进行划分后的熵不纯度为:
因此减小幅度(信息增益)为:0.8113-0.7936=0.00177
通过比较发现,使用性别作为特征会带来熵不纯度减小的幅度最大,因此决定使用性别来作为决策树的根节点,如图:
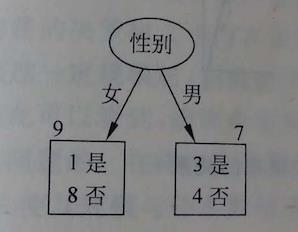
接下来,开始构造决策树的下一层节点,还剩下两个特征(年龄和收入),通过比较发现,男性当中采用年龄作为特征会最大减小不纯度,为0.9852;女性当中,采用收入作为特征会最大减小不纯度,为0.6880,因此据此构建出整个决策树,如图:

有了这棵决策树是不是很开心,不要着急,再仔细往下看,观察上图会发现,将收入分为三个等级对样本数据并没卵用,于是将决策树中左下角的两个叶节点进行合并,简化决策规则。
好辣,构建决策树的过程至此全部结束,感觉怎么样,是不是很简单,没错这个过程就是著名的ID3算法:
1)首先计算当前节点包含的所有样本的熵不纯度;
2)确定样本中的几组候选特征,分别计算每个特征对应的划分后样本的熵不纯度;
3)分别计算每个特征对应的熵不纯度的减小量,即信息增益,并进行比较;
4)选择减小量最大的特征作为决策树根节点的特征,构建出第一级;
5)在剩余特征中进行分析,构建决策树的下一级;
5)如果后继节点中只包含了单一类样本,就停止该枝的生长,该节点为叶节点;
6)如果后继节点仍然包含不同类样本,则再次进行上述步骤,直到每一个枝都到达叶节点;
除了算法中采用熵作为样本不纯度的度量外,还有其他的度量,如:
方差不纯度(Gini不纯度)度量:
误差不纯度度量:
其实很多情况下,不同度量对决策结果没多大影响。
3.2C4.5算法
继ID3算法之后,还有很多改进算法诞生,其中比较有影响的是C4.5算法,它与ID3最大的不同在于两点,首先它没有像ID3那样采用信息增益来分析如何选特征,而是用信息增益率:
(3)
除此之外,C4.5算法还可以处理连续数值特征;
C4.5算法基本原理:
1)对于一个在训练样本上有n种可能取值的数值特征,将其n个取值进行升序排列;
2)给定一个合理阈值,利用二分法将上述取值进行划分,一共可以采取n-1种划分方案;
3)对每一种划分方案分别计算信息增益率;
4)选择信息增益率最大的划分方案将上述连续值特征离散成二值特征(或多值,需要更多的划分方案),再与其他非数值特征一起构建决策树;
3.3CART算法
这一种算法也比较出名,但是本篇博客不打算学习,后续在学习吧。它是一种分类与回归树的算法,核心思想与ID3和C4.5基本相同,不同点在于CART在每一节点都采用二分法,所以最后构成的决策树就是一棵二叉树,另外,该算法除了用作决策分类,还可以用来构造回归树对连续变量进行回归。
以上是关于模式识别(Pattern Recognition)学习笔记(二十八)-- 决策树的主要内容,如果未能解决你的问题,请参考以下文章