python scrapy 简单的爬虫
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python scrapy 简单的爬虫相关的知识,希望对你有一定的参考价值。
1 scrapy的文档 比较简单
http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
我假定你已经安装了Scrapy。假如你没有安装,你可以参考这篇文章。
在本文中,我们将学会如何使用Scrapy建立一个爬虫程序,并爬取指定网站上的内容
1. 创建一个新的Scrapy Project
scrapy creatproject "project-name"
2. 定义你需要从网页中提取的元素Item
3.实现一个Spider类,通过接口完成爬取URL和提取Item的功能
4. 实现一个Item PipeLine类,完成Item的存储功能
我将会用腾讯招聘官网作为例子。
Github源码:https://github.com/maxliaops/scrapy-itzhaopin
目标:抓取腾讯招聘官网职位招聘信息并保存为JSON格式。
新建工程
首先,为我们的爬虫新建一个工程,首先进入一个目录(任意一个我们用来保存代码的目录),执行:
scrapy startproject yiou
最后的itzhaopin就是项目名称。这个命令会在当前目录下创建一个新目录itzhaopin,结构如下:
.
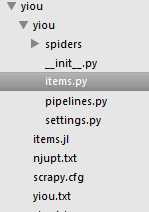
scrapy.cfg: 项目配置文件
items.py: 需要提取的数据结构定义文件
pipelines.py:管道定义,用来对items里面提取的数据做进一步处理,如保存等
settings.py: 爬虫配置文件
spiders: 放置spider的目录
定义Item
在items.py里面定义我们要抓取的数据:
|
1
2
3
4
5
6
7
8
|
import scrapy
|
实现Spider
Spider是一个继承自scrapy.contrib.spiders.CrawlSpider的Python类,有三个必需的定义的成员
name: 名字,这个spider的标识
start_urls:一个url列表,spider从这些网页开始抓取
parse():一个方法,当start_urls里面的网页抓取下来之后需要调用这个方法解析网页内容,同时需要返回下一个需要抓取的网页,或者返回items列表
所以在spiders目录下新建一个spider,tencent_spider.py:
|
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
# -*- coding:utf-8 -*- import scrapy from yiou.items import YiouItem import logging class YiouSpider(scrapy.Spider): def parse(self, response):
|
实现PipeLine
PipeLine用来对Spider返回的Item列表进行保存操作,可以写入到文件、或者数据库等。
PipeLine只有一个需要实现的方法:process_item,例如我们将Item保存到JSON格式文件中:
pipelines.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import json class YiouPipeline(object): |
到现在,我们就完成了一个基本的爬虫的实现,可以输入下面的命令来启动这个Spider:
|
1
|
scrapy crawl yiou |
爬虫运行结束后,在当前目录下将会生成一个名为items.json的文件,其中以JSON格式保存了职位招聘信息。
以上是关于python scrapy 简单的爬虫的主要内容,如果未能解决你的问题,请参考以下文章