python基础
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python基础相关的知识,希望对你有一定的参考价值。
目录:
1、简单模块调用
2、编码转换
3、字符操作
4、列表、元祖、元素
5、字典操作
一、简单模块调用
python有各种各样的库,大体分为内置库和第三方库。如:sys os为内置库,paramiko pycrypto为第三方库。简单调用如下:
import命令:
‘‘‘ import sys, os #path环境变量 print (sys.path) #打印脚本名字,及后面加的参数,以list形式存放 print(sys.argv) #os.system 调用系统命令,输出到屏幕,存不到变量 cmd_res = os.system("dir") #os.popen 调用系统命令,将命令存到内存 .read()可读 #cmd_res = os.popen("dir") cmd_res = os.popen("dir").read() #建立文件夹 # #os.mkdir("new_dir") print (‘-->‘,cmd_res) ‘‘‘
二、编码转换介绍
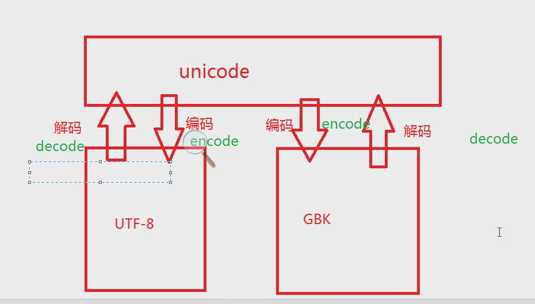
unicode是最底层、最纯的,会根据终端的编码进行转化展示
一般硬盘存储或传输为utf-8(因为省空间、省带宽),读入内存中为unicode,二者如何转换
a = ‘你好‘ ‘\xe4\xbd\xa0\xe5\xa5\xbd‘ <type ‘str‘>
b = u‘你好‘ u‘\u4f60\u597d‘ <type ‘unicode‘>
a.decode(‘utf-8‘) u‘\u4f60\u597d‘ (utf-8格式解码为unicode)
b.encode(‘utf-8‘) ‘\xe4\xbd\xa0\xe5\xa5\xbd‘ (unicode格式加密为utf-8)
注:在python2.7版本中需要如上转换,在脚本中如要显示中文,
只要在文件开头加入 # _*_ coding: UTF-8 _*_ 或者 #coding=utf-8 就行了
在python3.4以后版本,无需转换
三、字符操作


#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Shu Yang Wang name = "wangshuyang" #首字母大写 print(name.capitalize()) #统计字母数 print(name.count("a")) #50字节,name剧中,空字符补“-” print(name.center(50,"-")) #.encode,在python3中转成二进制 #.endswith,结尾判断 print(name.endswith("ng")) #.expandtabs tabsize,tab键转换多少空格 #print(name.expandtabs("tabsize=30")) #字符串切片 print(name[name.find("shu"):]) #.format格式化输出 #.formatm_map({‘name‘:‘alex‘,‘year‘:12})字典用的。 #.index ?? #.isalnum()英文加十进制数字,为真,小数和特殊字符等为假 print (‘ab23‘.isalnum()) print (‘ab23/‘.isalnum()) #.isdirgit() 是否为整数 #.isidentifier() 判断是不是一个合法的表示符(变量名) #.islower() 是不是小写 #.isnumeric() 判断只有数字 #.isspace() 是不是一个空格 #.istitle() 是不是一个标题 #.isprintable() 是不是一个可以打印的字符 除了tty file,drive file #.isupper() 是不是大写 #.join() list类型变成字符串 print(‘+‘.join([‘1‘,‘2‘,‘3‘])) #ljust,50字符长度,左补*号 print name.ljust(50,‘*‘) #rjust,50字符长度,右补-号 print name.rjust(50,‘-‘) #.lower() 变小写 print(‘WangShuYang‘.lower()) #.upper()变大写 print(‘wangshuyang‘.upper()) #.lstrip()左边去掉回车 #.rstrip()右边去掉回车 #.strip()去掉所有空格回车 #.maketrans python3密码对加密 #p = str.maketrans("abcdef",‘123456‘) #print("wang shu yang".translate(p)) #.replace() 替换 print (‘wang shu yang‘.replace("a","A",1)) #.rfind() 从左往右,找到最后一个值的下标返回 #.split() 字符转list print(‘1+2+3+4‘.split(‘+‘)) #.splitlines()换行字符转list print (‘1+2\n+3+4‘.splitlines(‘+‘)) #swapcase() 大写小写互换 #.title() 变成一个title,首字母大写 #.zfill() 不够用0填充,忘记吧
四、列表、元祖、元素
列表list是python中最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储、修改等操作[]为可变列表,()为不可变列表
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Shu Yang Wang #names = "1 2 3 4 5" names =["1","2","3","4","5"] #添加 names.append("6") #插入 names.insert(1,"6") names.insert(3,"7") #替换 names[2] = "8" #删除 names.remove("6") del names[1] #=names.pop(1) #默认删除最后一个,输入下标,删掉下标内容 names.pop() print(names) #反向查找 print(names.index("4")) print(names[names.index("4")]) #统计同名元素 print(names.count("6")) #names.clear[] 清空 #names.reverse 反转 #names.sort() 排序(!-+,0-9 a-z A-Z) #names.extend("列表名") 合并列表 #del 列表名 删除列表 #复制 #names2 = names.copy() 浅复制,只复制第一层,列表可以嵌套列表,内层嵌套更改,复制跟着改(联合账号) #names2 = names 浅复制,完全使用一块内存 import copy #names2 = copy.copy() 浅复制,只复制第一层,列表可以嵌套列表,内层嵌套更改,复制跟着改 #names2 = copy.deepcopy() 完全复制 #完全切片(复制) #names[:] #names2=names[:] 浅复制,只复制第一层,列表可以嵌套列表,内层嵌套更改,复制跟着改 #names2=list(names2) 浅复制,只复制第一层,列表可以嵌套列表,内层嵌套更改,复制跟着改 print(names[0],names[2]) #切片 print(names[1:3]) #切片 print(names[0:3]) print(names[:3]) #切片 print(names[-3:-1]) print(names[-2:]) #跳着步长切片 = range(0,10,2) print names[0:-1:2] print names[::2] #list_for for i in names[0:-1:2]: print (i)
不可变列表,元祖操作
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Shu Yang Wang #不可变列表 names=(‘wangshuyang‘,‘wang‘) #统计重名 print names.count(‘wang‘) #查询位置 print names.index(‘wangshuyang‘)
五、字典操作
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
字典的特性:
- dict是无序的
- key必须是唯一的,so 天生去重
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:Shu Yang Wang info = { ‘stu1101‘:‘TengLan Wu‘, ‘stu1102‘:‘LongZe Luola‘, ‘stu1103‘:‘XiaoZe Maliya‘, } print(info) #print(info["stu1101"]) #更改 info["stu1101"] = ‘武藤兰‘ #添加 info["stu1104"] = ‘CangJingKong‘ #del #del info["stu1101"] #info.pop("stu1101") #随机删除 #info.popitem() #安全获取方法 print (info.get(‘stu1103‘)) #判断key是否存在方法 print(‘stu1103‘ in info) print(info) #推荐使用 for i in info: print(i,info[i]) #会先把dict转成list,数据里大时莫用 for k,v in info.items(): print(k,v) #info.values #info.key #设置一个默认值,有值跳过 #info.setdefault #可以字典间的更新,字典合并 #info.update() #items是字典转成列表 #info.items() #初始化一个新的字典 #dict.fromkeys() ‘‘‘ #多级字典 av_catalog = { "欧美":{ "www.youporn.com": ["很多免费的,世界最大的","质量一般"], "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"], "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"], "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"] }, "日韩":{ "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"] }, "大陆":{ "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"] } } av_catalog["大陆"]["1024"][1]="可以镜像" ‘‘‘
以上是关于python基础的主要内容,如果未能解决你的问题,请参考以下文章