python中的zipmapreduce lambda函数的使用。
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python中的zipmapreduce lambda函数的使用。相关的知识,希望对你有一定的参考价值。
lambda只是一个表达式,函数体比def简单很多。
lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
lambda表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。
如下例子:

定义了一个lambda表达式,求三个数的和。
再看一个例子:
用lambda表达式求n的阶乘。

------------------------------
lambda表达式也可以用在def函数中。
看例子:

这里定义了一个action函数,返回了一个lambda表达式。其中lambda表达式获取到了上层def作用域的变量名x的值。
a是action函数的返回值,a(22),即是调用了action返回的lambda表达式。
这里也可以把def直接写成lambda形式。如下

zip()函数用法
zip()是Python的一个内建函数,它接受一系列可迭代的对象作为参数,将对象中对应的元素打包成一个个tuple(元组),然后返回由这些tuples组成的list(列表)。若传入参数的长度不等,则返回list的长度和参数中长度最短的对象相同。利用*号操作符,可以将list unzip(解压),看下面的例子就明白了:
1 2 3 4 5 6 7 8 9 |
|
对于这个并不是很常用函数,下面举几个例子说明它的用法:
* 二维矩阵变换(矩阵的行列互换)
比如我们有一个由列表描述的二维矩阵
a = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
通过python列表推导的方法,我们也能轻易完成这个任务
1 2 |
|
另外一种让人困惑的方法就是利用zip函数:
1 2 3 4 5 |
|
这种方法速度更快但也更难以理解,将list看成tuple解压,恰好得到我们“行列互换”的效果,再通过对每个元素应用list()函数,将tuple转换为list
Python函数式编程——map()、reduce()
1.map()
格式:map( func, seq1[, seq2...] )
Python函数式编程中的map()函数是将func作用于seq中的每一个元素,并用一个列表给出返回值。如果func为None,作用同zip()。
当seq只有一个时,将func函数作用于这个seq的每个元素上,得到一个新的seq。下图说明了只有一个seq的时候map()函数是如何工作的(本文图片来源:《Core Python Programming (2nd edition)》)。
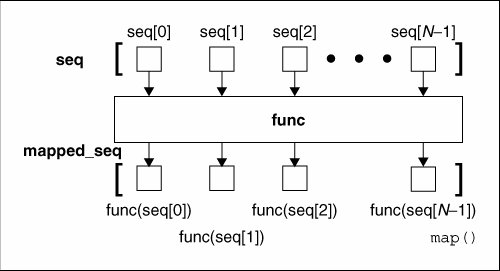
可以看出,seq中的每个元素都经过了func函数的作用,得到了func(seq[n])组成的列表。
下面举一个例子进行说明。假设我们想要得到一个列表中数字%3的余数,那么可以写成下面的代码。
|
1
2
3
4
5
6
|
# 使用map
print map( lambda x: x%3, range(6) ) # [0, 1, 2, 0, 1, 2]
#使用列表解析
print [x%3 for x in range(6)] # [0, 1, 2, 0, 1, 2]
|
这里又和上次的filter()一样,使用了列表解析的方法代替map执行。那么,什么时候是列表解析无法代替map的呢?
原来,当seq多于一个时,map可以并行地对每个seq执行如下图所示的过程:
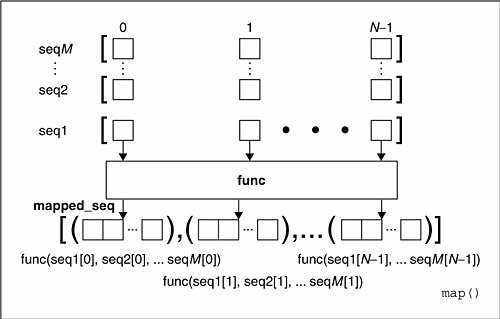
也就是说每个seq的同一位置的元素在执行过一个多元的func函数之后,得到一个返回值,这些返回值放在一个结果列表中。
下面的例子是求两个列表对应元素的积,可以想象,这是一种可能会经常出现的状况,而如果不是用map的话,就要使用一个for循环,依次对每个位置执行该函数。
|
1
|
print map( lambda x, y: x * y, [1, 2, 3], [4, 5, 6] ) # [4, 10, 18]
|
上面是返回值是一个值的情况,实际上也可以是一个元组。下面的代码不止实现了乘法,也实现了加法,并把积与和放在一个元组中。
|
1
|
print map( lambda x, y: ( x * y, x + y), [1, 2, 3], [4, 5, 6] ) # [(4, 5), (10, 7), (18, 9)]
|
还有就是上面说的func是None的情况,它的目的是将多个列表相同位置的元素归并到一个元组,在现在已经有了专用的函数zip()了。
|
1
2
3
|
print map( None, [1, 2, 3], [4, 5, 6] ) # [(1, 4), (2, 5), (3, 6)]
print zip( [1, 2, 3], [4, 5, 6] ) # [(1, 4), (2, 5), (3, 6)]
|
需要注意的是,不同长度的多个seq是无法执行map函数的,会出现类型错误。
2.reduce()
格式:reduce( func, seq[, init] )
reduce函数即为化简,它是这样一个过程:每次迭代,将上一次的迭代结果(第一次时为init的元素,如没有init则为seq的第一个元素)与下一个元素一同执行一个二元的func函数。在reduce函数中,init是可选的,如果使用,则作为第一次迭代的第一个元素使用。
简单来说,可以用这样一个形象化的式子来说明:reduce( func, [1, 2,3] ) = func( func(1, 2), 3)
下面是reduce函数的工作过程图:
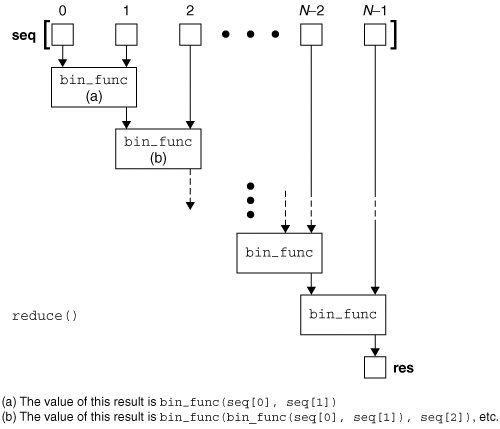
举个例子来说,阶乘是一个常见的数学方法,Python中并没有给出一个阶乘的内建函数,我们可以使用reduce实现一个阶乘的代码。
|
1
2
|
n = 5
print reduce(lambda x, y: x * y, range(1, n + 1)) # 120
|
那么,如果我们希望得到2倍阶乘的值呢?这就可以用到init这个可选参数了。
|
1
2
3
|
m = 2
n = 5
print reduce( lambda x, y: x * y, range( 1, n + 1 ), m ) # 240
|
以上是关于python中的zipmapreduce lambda函数的使用。的主要内容,如果未能解决你的问题,请参考以下文章