初识pipeline
Posted midhillzhou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识pipeline相关的知识,希望对你有一定的参考价值。
1、pipeline的产生
从一个现象说起,有一家咖啡吧生意特别好,每天来的客人络绎不绝,客人A来到柜台,客人B紧随其后,客人C排在客人B后面,客人D排在客人C后面,客人E排在客人D后面,一直排到店面门外。老板和三个员工首先为客人A准备食物:员工甲拿了一个干净的盘子,然后员工乙在盘子里装上薯条,员工丙再在盘子里放上豌豆,老板最后配上一杯饮料,完成对客人A的服务,送走客人A,下一位客人B开始被服务。然后员工甲又拿了一个干净的盘子,员工乙又装薯条,员工丙又放豌豆,老板又配上了一杯饮料,送走客人B,客人C开始被服务。一直重复下去。

从效率方面观察这个现象,当服务客人A时,在员工甲拿了一个盘子后,员工甲一直处于空闲状态,直到送走客人A,客人B被服务。老板自然而然的就会想到如果每个人都不停的干活,就可以服务更多的客人,赚到更多的钱。老板通过不停的尝试想出了一个办法。以客户A,B为例阐述这个方法:员工甲为客户A准备好了盘子后,在员工乙开始为客户A装薯条的同时,员工甲开始为客户B准备托盘。这样员工甲就可以不停的进行生产。整个过程如下图,客户们围着咖啡吧台排队,因为有四个生产者,一个老板加三个员工,所以可以同时服务四个客户。我们将目光转向老板,单位时间从他那里出去的客户数提高了将近四倍,也就是说效率提高将近四倍。

pipeline的概念可以从这里抽象出来:将一件需要重复做的事情(这里指为客户准备一份精美的食物)切割成各个不同的阶段(这里是四个阶段:盘子,薯条,豌豆,饮料),每一个阶段由独立的单元负责(四个生产者分别负责不同的环节)。所有待执行的对象依次进入作业队列(这里是所有的客户排好队依次进入服务,除了开始和结尾的一段时间,任意时刻,四个客户被同时服务)。对应到CPU中,每一条指令的执行过程可以切割成:fetch instruction、decode it、find operand、perform action、store result 5个阶段。
2、将pipeline应用到CPU的计算单元中
在未将pipeline应用到CPU之前,假如一个计算单元耗时300ps,将结果写入到寄存器耗时20ps,那么一条指令的执行时间为320ps。吞吐量定义为单位时间内执行的指令的条数,一般其单位为GIPS(giga-instruction per second),那么其吞吐量为3.12 GIPS,也就是说每秒执行3.12 giga条指令,1 giga 个= 10^9 个。
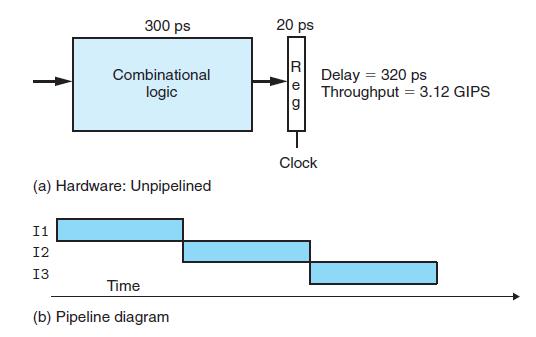
下面将pipeline应用到CPU,看计算单元的吞吐量会提高多少。我们将上图的组合逻辑单元切割成三个小的组合逻辑单元,每个组合逻辑单元耗时100ps,另外为了使前后组合逻辑单元的执行不相互影响,需要在每一对的小单元中间插入一个寄存器(对于这一点的理解,看完下面关于使用pipeline的CPU的运行过程就可以理解)如下图所示:
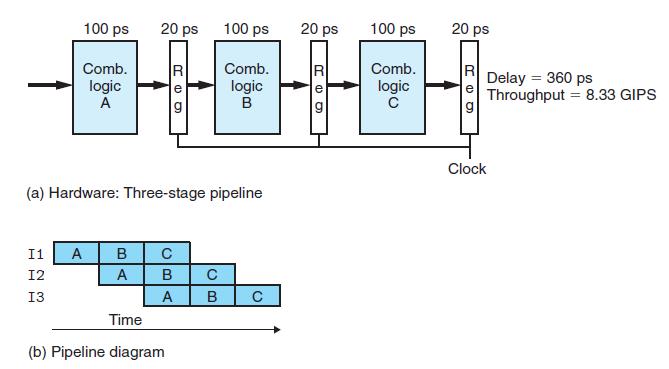
运行原理:首先这里非常值得指出的是,这里对寄存器的模型表示有些不细腻,因为从上图中并不能看出每个寄存器由输入,状态,和输出三个小单元组成。对于I1,I2,I3三条指令,当时钟迎来第一个上升沿时,I1首先进入组合逻辑A(如果这里不理解时钟,暂且忽略,下面会讲解),经过100ps后将结果花20ps写入到第一个寄存器的输入;当时钟迎来第二个上升沿时,更新第一个寄存器的状态和输出,即把I1指令经过组合逻辑A 后的结果更新到第一个寄存器以作为组合逻辑单元B的输入。与此同时,I2进入组合逻辑单元A,并在100ps后将结果花20ps写入到第一个寄存器的输入,这里注意,第一个寄存器的状态和输出并没有发生变化。这种机制保证了前后指令的互不干扰性。当时钟第三个上升沿来到时,I1进入逻辑单元C,I2进入逻辑单元B,I3开始进入逻辑单元A。
下面我们来计算使用pipeline的计算单元的吞吐量,由于每个阶段都需要100ps+20ps=120ps的时间,我们可以选用使得系统吞吐量最大的周期为120ps的时钟1/120*1000=8.3 GIPS,即每秒钟执行8.3 giga条指令相比于未使用pipeline的3.12 GIPS,提高了2.67倍,大家可能有疑问为什么不是3倍,因为我们为了让前后指令互不影响插入了两个寄存器,所以达不到最大极限3。
上面两幅图中的两幅b图是专门用来表示pipeline中各个时刻各个指令所处状态的pipeline diagram。
3、决定计算单元速度的是pipeline而不是系统时钟的频率
我们以第2部分为背景来阐述这个问题,三个阶段,每一阶段耗时120 ps,如果时钟周期高于120ps,那么将会出现寄存器值由于没有来得及更新导致的指令执行混乱的情况。对于更一般的情况,比如从左向右,三个计算单元的执行时间是(120+20)+(80+20)+(100+20)=360,那么时钟周期必须大于最大的单个组合逻辑单元的执行时间,否则就会出现阶段执行不完整的情况,即140ps,所以说决定计算单元速度的是pipeline,更精确的说是pipeline中的最大的组合逻辑单元的执行时间。对于如何将计算单元切割成更小的执行时间几乎相同的阶段,对硬件设计者来说,是一个挑战。
4、delay slot
在上面的讨论中我们都假设连续的指令间并没有依赖关系,现在引入指令间的依赖关系。依赖关系可以分为两种:data dependency, control dependency。
对于data dependency,我们用下面的指令序列作为例子

图中的小圆圈加箭头表示了这种依赖关系,比如第二条指令的执行需要用到第一条指令的结果,所以第二条指令必须推迟进入pipeline的时间,称为load/store delay slot,以获得eax更新后的值,2条与第3条的数据依赖关系同理。
对于control dependency,我们用下面的指令序列作为例子

第3条指令为跳转指令,第4条指令是否执行依赖于第三条指令的结果,即是否跳转,所以第四条指令必须延迟进入pipeline的时间,称为branch delay slot。
5、 参考资料
《see mips run》
《computer system: a programmer\'s perspective》p391-p400
以上是关于初识pipeline的主要内容,如果未能解决你的问题,请参考以下文章