模式识别(Pattern Recognition)学习笔记(二十七)-- 基于树搜索算法的快速近邻法
Posted eternity1118_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模式识别(Pattern Recognition)学习笔记(二十七)-- 基于树搜索算法的快速近邻法相关的知识,希望对你有一定的参考价值。
近邻法中计算距离需要遍历,带来很大的计算量和存储量,为了改善这两方面的性能,有人提出采用分枝界定算法(Branch-Bound Algorithm)来改进近邻法,主要分为两个阶段:1)利用人工划分或K-means聚类算法或其他动态聚类算法将样本集X划分成层级形式,形成一个树结构;2)利用树搜索算法找出与未知样本的最近邻。
1.层级划分
1)将样本集X划分成l个子集,每个子集再分成l个子集,不断这样划分下去,形成一个树状结构,如图:
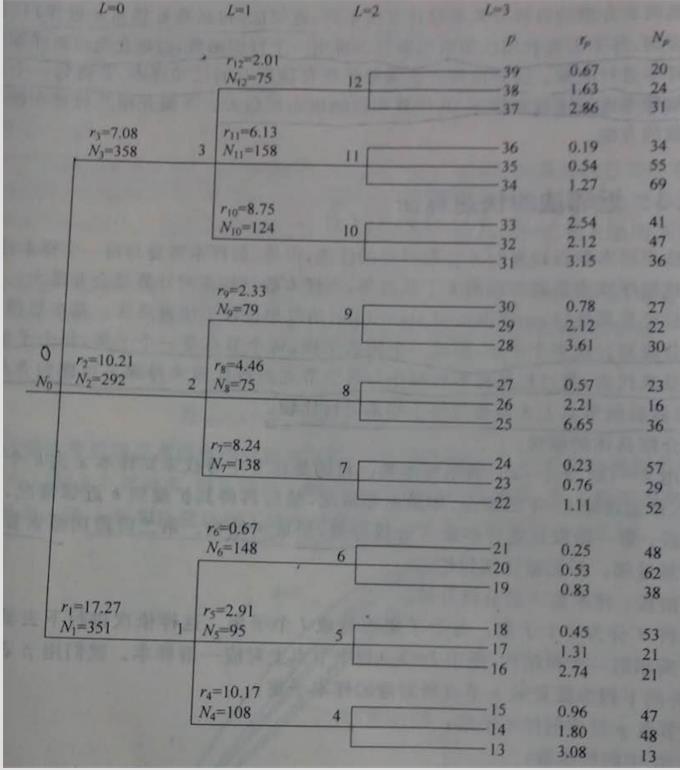
这样划分完后,每个节点上都会有一部分样本;
2)将节点记作p,并对每个节点计算以下参数:
p节点上拥有的子集:Xp
p节点上样本子集Xp的样本数:Np
Xp中所有样本的样本均值(可看做是样本Centroid或圆心):Mp
Xp中离样本中心Mp最远样本和Mp之间的距离,相当于以Mp为圆心的圆的半径:
2.判断某未知样本x的最近邻是否在某个节点的子集上
对于该判断,有两个规则:
1)规则一:若满足:,则
不可能是x的最近邻;
其中,B是Xp中当前搜索到的样本到待识样本x的最近距离,该值在算法初始时置为;
该规则的解释是:如果Xp中的某一个样本xi到圆心Mp的距离比其中到圆心Mp最大的距离(即半径)与上一次搜索中找到的最近邻距离之和还要大很多,说明样本xi必然是远离Xp中样本组成的圆的,所以不可能是x的最近邻,如图可示:

2)规则二:若满足:,则
不可能是x的最近邻;
这条规则是针对最后一层树枝节点提出的,如果搜索算法进行到了最后一层节点,那么为了避免把最后一层的所有节点都计算一次距离,就可以利用这一规则来进行剔除;
该规则的解释意义同规则一类似:如果待识样本x与圆心Mp的距离大于Xp中某个样本xi到圆心Mp的距离与当前B的和,表明x离xi所在节点比较远,xi也不会是x的最近邻,同样可以根据上图来理解。
3.树搜索算法
1)从第一级开始,即L=0,p=0,当前初始最近邻距离B=0;
2)对当前节点分别计算圆心Mp和半径rp;
3)对当前节点p的所有直接后继子节点进行保存,分别计算其到圆心Mp的距离D(x,Mp);
4)根据规则一,对当前节点的所有直接后继子节点进行判断,将所有满足规则一的节点直接剔除;
5)如果保存的节点当前为空,则回退到上一层,即L=L-1;如果L=0,就停止,否则跳至4);如果保存的节点中有多于一个的节点存在,则跳至6);
6)在已保存的节点中找到最近节点p1,方法是计算D(x,Mp),值最小的就是最近的节点p1,因而将p1节点置为当前节点,并清空已保存的节点目录;如果当前节点p1处于的层级是最后一级,就跳至7),否则L=L+1,跳至2);
7)对当前节点p1中的每个样本xi使用规则二来进行最近邻的判断;只要满足规则二的样本xi,就可以不用计算D(x,xi),不满足就计算,并将其与当前得到的最近B进行比较,如果比当前的最近还小,那么就认为找到了比当前最近还要近的样本,则更新B:B=D(x,xi),并把这个最近样本的下标位置保存下来:NN=i;对所有样本进行上述判断后,跳至4);
8)输出待识未知样本x的最近邻,以及距离
:
;
4.对于k近邻的改进
上面是对最近邻做了计算上的改进,对于k近邻,基本上与上面介绍的算法类似,只需要稍稍做些小改动:
1)首先根据最近邻得到的最邻近距离,按照实际情况给出恰当的k个邻近距离表;
2)首先B的初始值:设为x到k个近邻中的最远的那个近邻之间的距离;
3)在上面步骤7)中,每计算一个距离后,就与邻近距离表中的k歌距离进行比较,如果这个距离比表中任何一个距离都要小,那么就果断剔除掉表中距离最大的而一个,也就是放弃第k个;
5.其它的近邻法
除了已经介绍的这几种近邻法之外,还有别的,如剪辑近邻法和压缩近邻法。对于剪辑近邻法,其实就是主要针对那种两类样本数据出现重叠而导致不可分的情况,在这种情况下,如果能够把重叠区域的已知样本剔除出去,决策时就不会受到那些错分样本的干扰,可以让决策面更接近于最优分类面,用一句话说就是把边界上的样本区分开。而对于压缩近邻法,其基于的思想是这样的,尽管剪辑近邻可以将边界处容易引起错分的样本剔除干净,使得分类边界清晰可见,但是仔细想会发现,那些原理分类边界的样本其实对于最后的决策是没有用处的,只要能够找出各类样本中最有利于用来与其他类区分的代表性样本,就可以把很多干扰无用样本去掉,简化计算,其具体做法也很简单:将训练样本分为两个子集,储存集和候选集,先从候选集中取出一个样本放入储存集,对于候选集中的每一个样本,储存集中的这个样本都可以将他们正确分类,那么这些样本都保留在候选集中,否则把不能正确分类的移到储存集,以此类推,直到没有样本再需要移动。
以上是关于模式识别(Pattern Recognition)学习笔记(二十七)-- 基于树搜索算法的快速近邻法的主要内容,如果未能解决你的问题,请参考以下文章