有道词典翻译(携带请求头和post参数请求)
Posted 菜鸟SSS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了有道词典翻译(携带请求头和post参数请求)相关的知识,希望对你有一定的参考价值。
一、静态爬取页面信息
有道翻译网址:http://fanyi.youdao.com/
在翻译中输入python
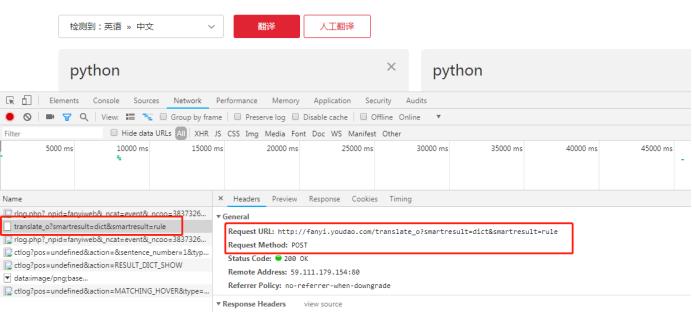
找到接口和请求的方式
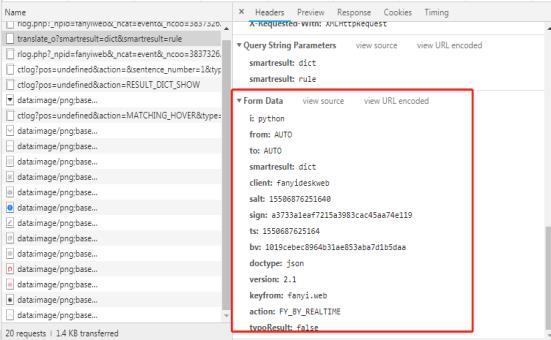
参数是From Data类型
需要把参数数据转换为字典,
复制粘贴后按住Ctrl + r ,然后
Headers
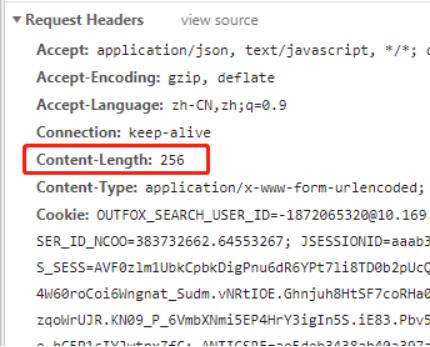
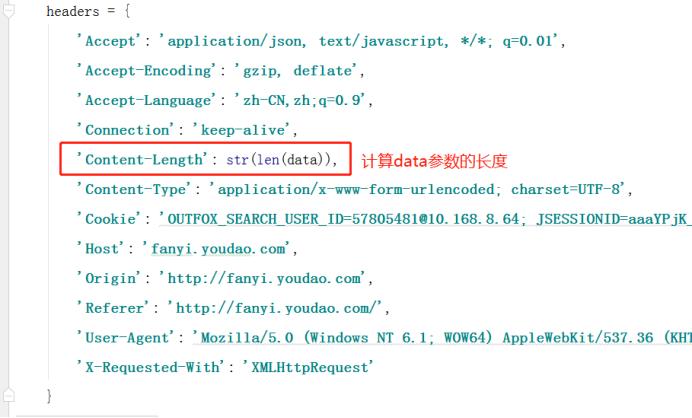
内容的长度是data携带参数的长度

代码实现
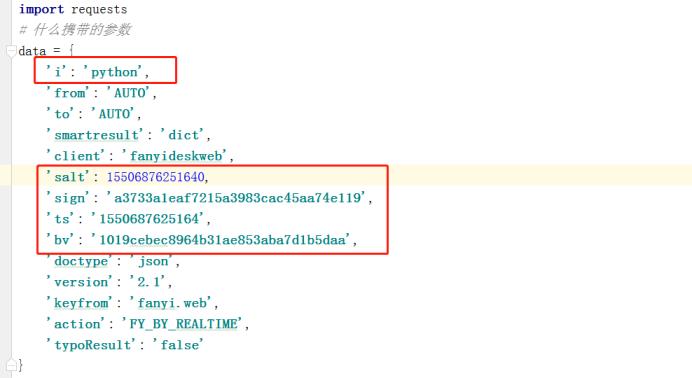
分析:红色圈住的,是会根据要翻译的内容变化而变化


运行结果:

代码:


import requests import json # 定义爬取url地址 base_url = \'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule\' # 定义请求参数 data = { \'i\': \'python\', \'from\': \'AUTO\', \'to\': \'AUTO\', \'smartresult\': \'dict\', \'client\': \'fanyideskweb\', \'salt\': \'15508011658043\', \'sign\': \'8f6d849c13cec811c6b7ab6d0ad41eb6\', \'ts\': \'1550801165804\', \'bv\': \'6f014bd66917f921835d1d6ae8073eb1\', \'doctype\': \'json\', \'version\': \'2.1\', \'keyfrom\': \'fanyi.web\', \'action\': \'FY_BY_REALTIME\', \'typoResult\': \'false\' } # 定义请求头部参数 headers = { \'Accept\': \'application/json, text/javascript, */*; q=0.01\', \'Accept-Encoding\': \'gzip, deflate\', \'Accept-Language\': \'zh-CN,zh;q=0.9\', \'Connection\': \'keep-alive\', \'Content-Length\': \'256\', \'Content-Type\': \'application/x-www-form-urlencoded; charset=UTF-8\', \'Cookie\': \'OUTFOX_SEARCH_USER_ID=-1632754728@10.169.0.84; JSESSIONID=aaavabYot4NQ1fAZH8sKw; \' \'OUTFOX_SEARCH_USER_ID_NCOO=933374763.1142684; ___rl__test__cookies=1550801165800\', \'Host\': \'fanyi.youdao.com\', \'Origin\': \'http://fanyi.youdao.com\', \'Referer\': \'http://fanyi.youdao.com/\', \'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) \' \'Chrome/71.0.3578.98 Safari/537.36\', \'X-Requested-With\': \'XMLHttpRequest\' } # 发起请求 加入headers参数,让服务器知道是浏览器访问的 response = requests.post(base_url, data=data, headers=headers) json_data = response.json() print(json_data)
二、动态爬取页面信息(加密)
输入测试数据,再通过使用F12观察,其中有一条是POST请求,而向服务器发送的请求数据并不是在url里,那么我们可以试着模拟这个POST请求。

1、data字典内容:
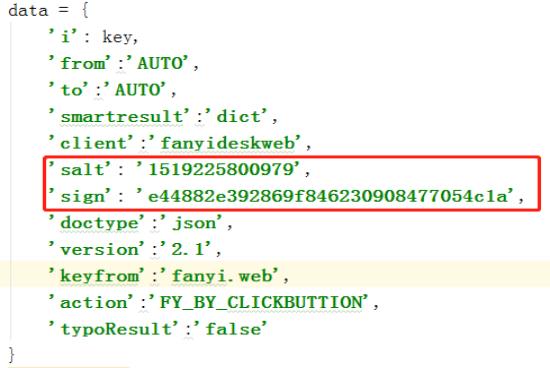
2、headers字典内容:

3、运行结果:根据不同的单词,返回的数据不一样
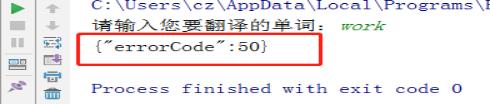
4、解决问题:
从data中的参数中,我们看到”salt“和"sign"两个,这是添加数字签名的标记。也就是这两个参数的值是生成出来的,也就是说随着翻译内容的不同,这两个值可能是会变化的。
像这种动态生成的值一般会写在js脚本文件中。
(1)查找对应的js文件
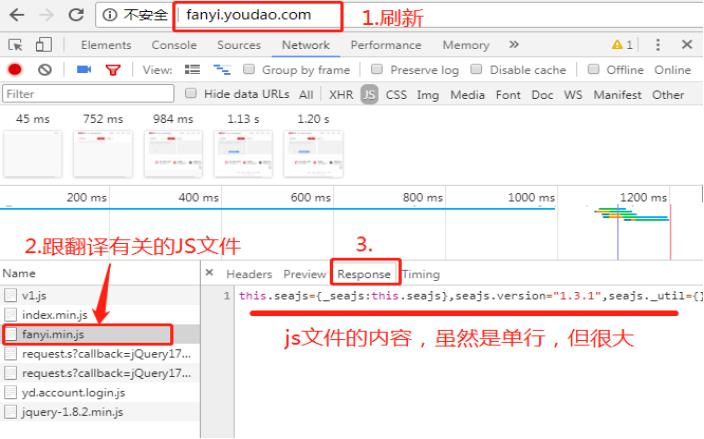
(2)查看文件
双击复制Response中的内容,打开在线格式网页,如下图所示: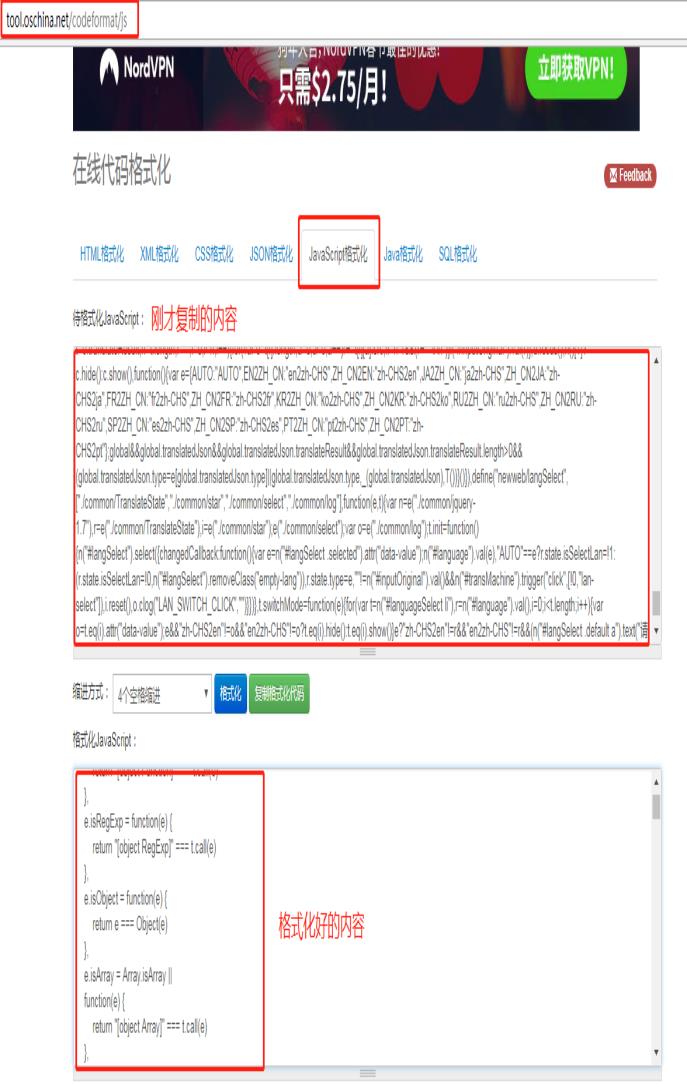
为了方便查看,我们在新建一个js文件,并且搜索与”salt“相关的字符,如下图所示:
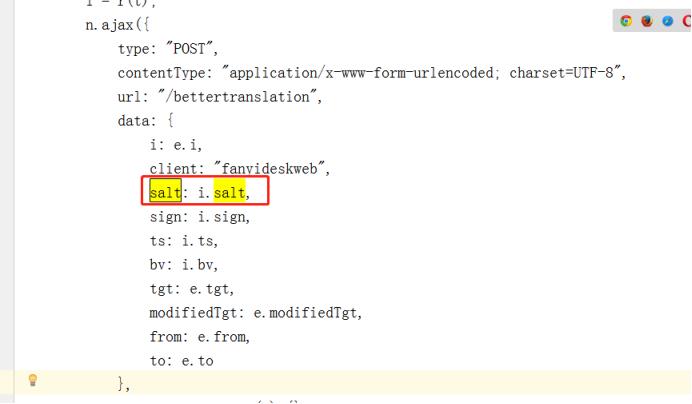
分析:i在这里是什么?

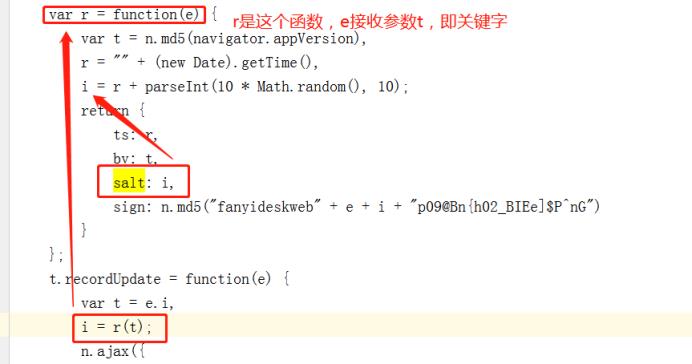
(3)生产salt内容
其中
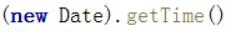
这行语句我们可以在浏览器中的控制台上输出看一下,如下图
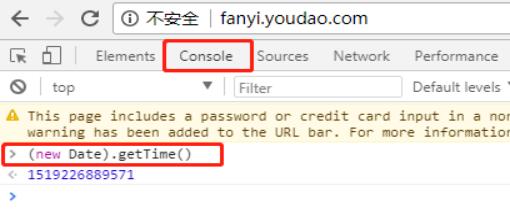
可见是精化到毫秒(1毫秒=0.001秒)的时间戳,(用同样的方式验证:parseInt(10 * Math.random(), 10)),我们可以在python输出一个时间,两者做个对比


保留三位小数,然后把它转换为整形
所以这个在JS中生成的salt值
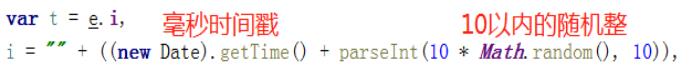
在python中可以这样生成:
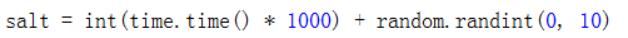
(4)生成sign内容


推导出:sign = i.sign
- sign = n.md5("fanyideskweb" + e + i + "p09@Bn{h02_BIEe]$P^nG")
e = e.i e.i = 需要翻译的关键字
i = r + parseInt(10 * Math.random(), 10)
r = "" + (new Date).getTime()
编写程序:




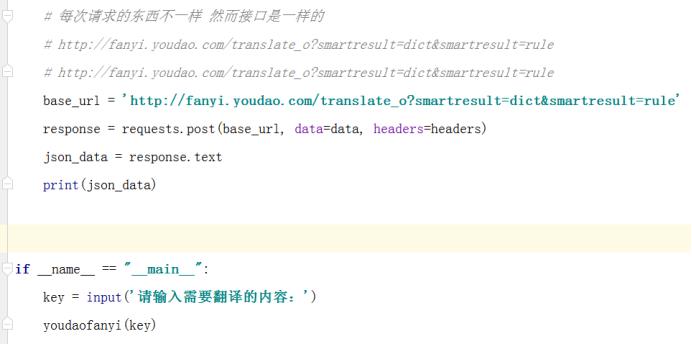
编程当中需要注意的地方:
发送post请求时,需要特别注意headers的一些属性:
Content-Length: 144: 是指发送的表单数据长度为144,也就是字符个数是144个。
X-Requested-With: XMLHttpRequest :表示Ajax异步请求。
Content-Type: application/x-www-form-urlencoded : 表示浏览器提交 Web 表单时使用,表单数据会按照 name1=value1&name2=value2 键值对形式进行编码。
代码如下:
import requests import random import time import hashlib # md5加密函数 def getmd5(value): # 生成MD5对象 md5 = hashlib.md5() # 将值进行编码 编码成字符串 md5.update(bytes(value, encoding="utf-8")) # 对字符串进行加密 sign = md5.hexdigest() return sign def fanyi(key): # 定义起始url base_url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule" # 生成salt和sign参数 salt = int(time.time() * 1000) + random.randint(0, 10) sign_str = "fanyideskweb" + key + str(salt) + "p09@Bn{h02_BIEe]$P^nG" sign = getmd5(sign_str) data = { \'i\': key, # \'from\': \'AUTO\', # \'to\': \'AUTO\', # \'smartresult\': \'dict\', \'client\': \'fanyideskweb\', \'salt\': salt, \'sign\': sign, # \'ts\': \'1550801165804\', # \'bv\': \'6f014bd66917f921835d1d6ae8073eb1\', # \'doctype\': \'json\', # \'version\': \'2.1\', \'keyfrom\': \'fanyi.web\', # \'action\': \'FY_BY_REALTIME\', # \'typoResult\': \'false\' } headers = { # \'Accept\': \'application/json, text/javascript, */*; q=0.01\', # \'Accept-Encoding\': \'gzip, deflate\', # \'Accept-Language\': \'zh-CN,zh;q=0.9\', # \'Connection\': \'keep-alive\', # \'Content-Length\': \'256\', # \'Content-Type\': \'application/x-www-form-urlencoded; charset=UTF-8\', \'Cookie\': \'OUTFOX_SEARCH_USER_ID=-1632754728@10.169.0.84; JSESSIONID=aaavabYot4NQ1fAZH8sKw; OUTFOX_SEARCH_USER_ID_NCOO=933374763.1142684; ___rl__test__cookies=1550801165800\', # \'Host\': \'fanyi.youdao.com\', # \'Origin\': \'http://fanyi.youdao.com\', \'Referer\': \'http://fanyi.youdao.com/\', \'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36\', # \'X-Requested-With\': \'XMLHttpRequest\' } # 发起请求 加入headers参数,让服务器知道是浏览器访问的 response = requests.post(base_url, data=data, headers=headers) json_data = response.json() print(json_data) if __name__ == "__main__": key = input("请输入需要翻译的内容:") fanyi(key)
以上是关于有道词典翻译(携带请求头和post参数请求)的主要内容,如果未能解决你的问题,请参考以下文章