Suggestion(搜索建议)产品和技术
Posted 大熊先生| 关注互联网后端技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Suggestion(搜索建议)产品和技术相关的知识,希望对你有一定的参考价值。
今天来简单聊聊Suggestion产品
什么是Suggestion服务? 一图胜千言:
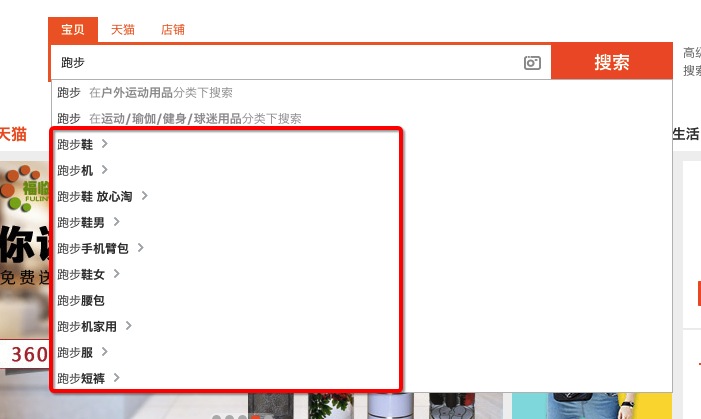
当你想要搜索某个长词语或者一句话输入部分时,Suggestion服务预测你极大可能的候选项,并罗列出来,供你选择。
产品的意义:
1. 降低用户搜索的输入成本,用户总是懒惰的,谁能让用户最懒惰还能帮他把事办好,这就是好的产品。当然如果真有一天能用脑电波搜索了,这个产品功能就没意义了.
2. 为用户提供提示,因为有部分用户多一个长词组很有可能只能记住部分。如有部电影叫"心急吃不了热豆腐",朋友A推荐给朋友B,只记得"心急吃不了啥"了
3. 提高搜索转化率,用户在任何过程中都有可能流失,打字打完"心急吃不了",一个朋友说别看这个了,看<冰与火之歌>吧,可能还差那最后3个字就能转战别的电影了
什么样的词应该纳入到Suggestion里面去呢?
如果把所用所有的搜索记录都作为suggestion服务,那用户输入完一个前缀后,就会出现满屏的词语;在这种场景下,尽量提供好用的suggestion而保持简洁的结果的秘诀在于把控数量并提高转化率,所以一般可以用双重法则
1. 如果这个前缀的所有搜索词不超过N个,按转化概率从大到小排序
2. 如果超过N个, 放弃掉用户转化率小于a的搜索词,按转化概率从大到小排序
整体技术上怎么实现呢?
如果你在做一个Suggestion总词语量较小的产品. (<千万级)
短平快,直接用小脚本扫每天的用户搜索日志,然后根据策略得出整个搜索词表,放到mysql中;
查询直接用 select XXX from TABLE_XXX where SuggestionWords like {QUERY}% 进行查询
访问量大怎么办?
mysql 的查询成为瓶颈,在前面加一层缓存,来存储结果List即可.
访问量极大怎么办?
这里极大的意思时,一瞬间的某个词语的缓存未命中(失效或者DB更新后delete)查询会拖死Mysql
两个思路
1. mysql加从库 Master-Slave集群
2. 更新时主动生成缓存,让前端查询任何时刻都看不到缓存未命中
如果你在做一个Suggestion总词语量较大的产品. (>千万级)
类似的场景我之前遇到的是百度的帐号注册时的Suggestion, N亿的注册用户,新用户上来了想注册abcd这个帐号,已经被占用了,所以一般推荐abcd作为前缀能用的帐号如abcd1,abcd11等,类似的场景如域名注册服务商的推荐。
技术实现上可以用Tire树,Tire树的每个条边就是每个词,从非根节点到根节点经过的所有的边组成了一个词,如下图的最长词dcba
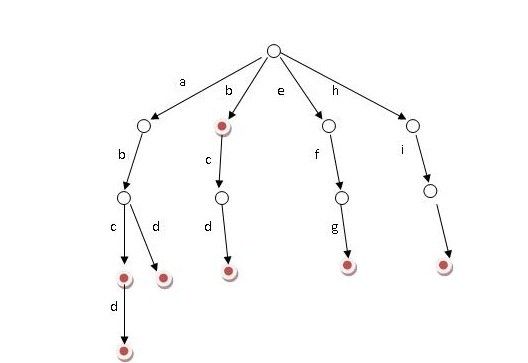
通过这种方式就能对海量基数词进行Suggestion服务了。
另外tire树的插入、查找、删除的时间复杂度都是o(N),N为待插入、查找、删除字符串的长度。
以上是关于Suggestion(搜索建议)产品和技术的主要内容,如果未能解决你的问题,请参考以下文章