[项目实战派]花40分钟写一个-CBIR引擎-代码公开
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[项目实战派]花40分钟写一个-CBIR引擎-代码公开相关的知识,希望对你有一定的参考价值。
浏览网页的时候发现一篇不错的文章"用Python和OpenCV创建一个图片搜索引擎的完整指南"http://python.jobbole.com/80860/.作者在浏览自己旅游的照片的时候,发现照片太多了分类不过来,一时技痒写了个分类软件,虽然简单但是有用。关键的是我发现他在原文中使用了半个小时就写出来了。
蛮快的嘛,我想。那么我要用多长时间写出来了,毕竟对于CBIR也是研究过的。
那么立即来做,首先我要找到是图片。我没有那么多旅游图片(汗),但是别人的照片也是可以一样用的。找到了之前专门用于测试CBIR的图片集,大概是这个样子
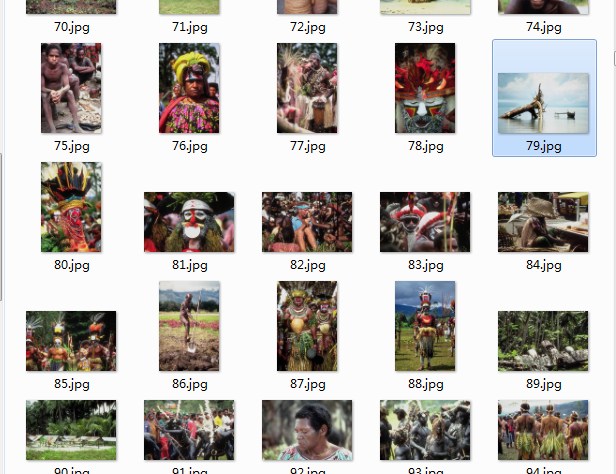
就是各种奇奇怪怪的照片。然后搭建opencv的基本框架。我们python用的不熟,但是c++下面自己是有类库的,所以用起来也不是很复杂
首先是读入所有的图片:
//递归读取目录下全部文件
void getFiles(string path, vector<string>& files,string flag){
//文件句柄
long hFile = 0;
//文件信息
struct _finddata_t fileinfo;
string p;
if((hFile = _findfirst(p.assign(path).append("\\*").c_str(),&fileinfo)) != -1){
do{
//如果是目录,迭代之,如果不是,加入列表
if((fileinfo.attrib & _A_SUBDIR)){
if(strcmp(fileinfo.name,".") != 0 && strcmp(fileinfo.name,"..") != 0 && flag=="r")
getFiles( p.assign(path).append("\\").append(fileinfo.name), files,flag );
}
else{
files.push_back(p.assign(path).append("\\").append(fileinfo.name) );
}
}while(_findnext(hFile, &fileinfo) == 0);
_findclose(hFile);
}
}
//递归读取目录下全部图片
void getFiles(string path, vector<Mat>& files,string flag){
vector<string> fileNames;
getFiles(path,fileNames,flag);
for (int i=0;i<fileNames.size();i++){
Mat tmp = imread(fileNames[i]);
if (tmp.rows>0)//如果是图片
files.push_back(tmp);
}
}
//递归读取目录下全部图片和名称
void getFiles(string path, vector<pair<Mat,string>>& files,string flag){
vector<string> fileNames;
getFiles(path,fileNames,flag);
for (int i=0;i<fileNames.size();i++){
Mat tmp = imread(fileNames[i]);
if (tmp.rows>0){
pair<Mat,string> apir;
apir.first = tmp;
apir.second = fileNames[i];
files.push_back(apir);
}
}
}
void getFiles(string path, vector<string>& files,string flag){
//文件句柄
long hFile = 0;
//文件信息
struct _finddata_t fileinfo;
string p;
if((hFile = _findfirst(p.assign(path).append("\\*").c_str(),&fileinfo)) != -1){
do{
//如果是目录,迭代之,如果不是,加入列表
if((fileinfo.attrib & _A_SUBDIR)){
if(strcmp(fileinfo.name,".") != 0 && strcmp(fileinfo.name,"..") != 0 && flag=="r")
getFiles( p.assign(path).append("\\").append(fileinfo.name), files,flag );
}
else{
files.push_back(p.assign(path).append("\\").append(fileinfo.name) );
}
}while(_findnext(hFile, &fileinfo) == 0);
_findclose(hFile);
}
}
//递归读取目录下全部图片
void getFiles(string path, vector<Mat>& files,string flag){
vector<string> fileNames;
getFiles(path,fileNames,flag);
for (int i=0;i<fileNames.size();i++){
Mat tmp = imread(fileNames[i]);
if (tmp.rows>0)//如果是图片
files.push_back(tmp);
}
}
//递归读取目录下全部图片和名称
void getFiles(string path, vector<pair<Mat,string>>& files,string flag){
vector<string> fileNames;
getFiles(path,fileNames,flag);
for (int i=0;i<fileNames.size();i++){
Mat tmp = imread(fileNames[i]);
if (tmp.rows>0){
pair<Mat,string> apir;
apir.first = tmp;
apir.second = fileNames[i];
files.push_back(apir);
}
}
}
然后是编写hsv距离,这个参考以前的资料
double GetHsVDistance(Mat src_base,Mat src_test1){
Mat hsv_base;
Mat hsv_test1;
/// Convert to HSV
cvtColor( src_base, hsv_base, COLOR_BGR2HSV );
cvtColor( src_test1, hsv_test1, COLOR_BGR2HSV );
/// Using 50 bins for hue and 60 for saturation
int h_bins = 50; int s_bins = 60;
int histSize[] = { h_bins, s_bins };
// hue varies from 0 to 179, saturation from 0 to 255
float h_ranges[] = { 0, 180 };
float s_ranges[] = { 0, 256 };
const float* ranges[] = { h_ranges, s_ranges };
// Use the o-th and 1-st channels
int channels[] = { 0, 1 };
/// Histograms
MatND hist_base;
MatND hist_test1;
/// Calculate the histograms for the HSV images
calcHist( &hsv_base, 1, channels, Mat(), hist_base, 2, histSize, ranges, true, false );
normalize( hist_base, hist_base, 0, 1, NORM_MINMAX, -1, Mat() );
calcHist( &hsv_test1, 1, channels, Mat(), hist_test1, 2, histSize, ranges, true, false );
normalize( hist_test1, hist_test1, 0, 1, NORM_MINMAX, -1, Mat() );
/// Apply the histogram comparison methods
double base_test1 = compareHist( hist_base, hist_test1, 0 );
return base_test1;
}
Mat hsv_base;
Mat hsv_test1;
/// Convert to HSV
cvtColor( src_base, hsv_base, COLOR_BGR2HSV );
cvtColor( src_test1, hsv_test1, COLOR_BGR2HSV );
/// Using 50 bins for hue and 60 for saturation
int h_bins = 50; int s_bins = 60;
int histSize[] = { h_bins, s_bins };
// hue varies from 0 to 179, saturation from 0 to 255
float h_ranges[] = { 0, 180 };
float s_ranges[] = { 0, 256 };
const float* ranges[] = { h_ranges, s_ranges };
// Use the o-th and 1-st channels
int channels[] = { 0, 1 };
/// Histograms
MatND hist_base;
MatND hist_test1;
/// Calculate the histograms for the HSV images
calcHist( &hsv_base, 1, channels, Mat(), hist_base, 2, histSize, ranges, true, false );
normalize( hist_base, hist_base, 0, 1, NORM_MINMAX, -1, Mat() );
calcHist( &hsv_test1, 1, channels, Mat(), hist_test1, 2, histSize, ranges, true, false );
normalize( hist_test1, hist_test1, 0, 1, NORM_MINMAX, -1, Mat() );
/// Apply the histogram comparison methods
double base_test1 = compareHist( hist_base, hist_test1, 0 );
return base_test1;
}
封装成函数。这个函数比原文中作者提出的方法要简单,我偷懒了。
然后就是要编写主函数程序,这个比较麻烦的地方就是要比较出最前面的10 个图片 。我采用比较笨的方法,赶时间嘛:
int _tmain(int argc, _TCHAR* argv[])
{
vector<pair<Mat,string>> imagepairs;
vector<double> dresult;
double dmax = 0;
int imax = -1;
//读入图片
getFiles("images",imagepairs);
Mat src = imread("images/0.jpg");
//距离测算
for (int i=0;i<imagepairs.size();i++){
double tmp = GetHsVDistance(src,imagepairs[i].first);
if (tmp ==1)
tmp =0;//不能搞自己
char cbuf[1024];
sprintf_s(cbuf,"dst/%d.jpg",i);
dresult.push_back(tmp);//推入vecresult中
}
//寻找前10个图片
for (int index = 0;index<10;index++){
for (int i=0;i<imagepairs.size();i++){
if (dresult[i]>dmax){
dmax = dresult[i];
imax = i;
}
}
char cbuf[1024];
sprintf_s(cbuf,"dst/%d.jpg",index);
imwrite(cbuf,imagepairs[imax].first);
dresult[imax] = 0;//剔出队列
dmax = 0;
imax = -1;
}
printf("OK");
waitKey();
return 0;
}
{
vector<pair<Mat,string>> imagepairs;
vector<double> dresult;
double dmax = 0;
int imax = -1;
//读入图片
getFiles("images",imagepairs);
Mat src = imread("images/0.jpg");
//距离测算
for (int i=0;i<imagepairs.size();i++){
double tmp = GetHsVDistance(src,imagepairs[i].first);
if (tmp ==1)
tmp =0;//不能搞自己
char cbuf[1024];
sprintf_s(cbuf,"dst/%d.jpg",i);
dresult.push_back(tmp);//推入vecresult中
}
//寻找前10个图片
for (int index = 0;index<10;index++){
for (int i=0;i<imagepairs.size();i++){
if (dresult[i]>dmax){
dmax = dresult[i];
imax = i;
}
}
char cbuf[1024];
sprintf_s(cbuf,"dst/%d.jpg",index);
imwrite(cbuf,imagepairs[imax].first);
dresult[imax] = 0;//剔出队列
dmax = 0;
imax = -1;
}
printf("OK");
waitKey();
return 0;
}
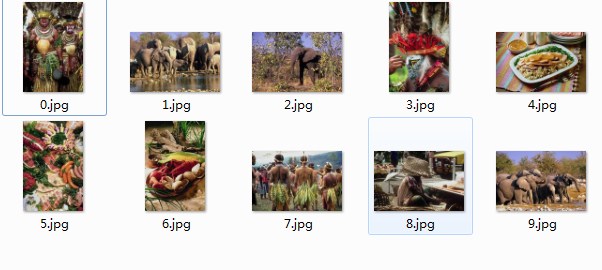
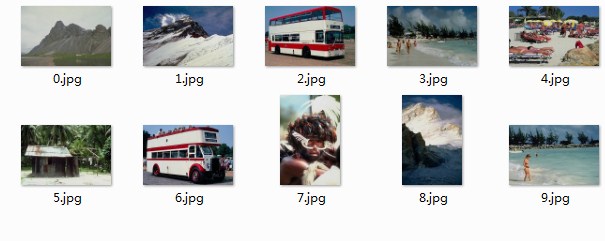
前后花了40-50分钟时间,最后的效果不如作者的效果。主要差距在核心算法上面。看来日常的算法总结重构的确很有价值。
这篇文章先写到这里,最近事多,等到闲下来再进行重构。欢迎大家批评指正。
以上是关于[项目实战派]花40分钟写一个-CBIR引擎-代码公开的主要内容,如果未能解决你的问题,请参考以下文章