动态规划中 策略迭代 和 值迭代 的一个小例子
Posted Hello_BeautifulWorld
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了动态规划中 策略迭代 和 值迭代 的一个小例子相关的知识,希望对你有一定的参考价值。
强化学习中动态规划是解决已知状态转移概率和奖励值情况下的解决方法,这种情况下我们一般可以采取动态规划中的 策略迭代和值迭代的方式来进行求解,下面给出一个具体的小例子。
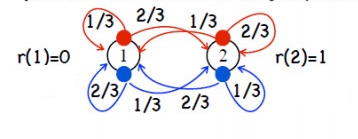
动态规划可以看成是构成强化学习问题的一个子问题, 与其说是一个子问题更不如说是一种特殊情况,动态规划中我们是知道 reward 和 state transiton probability , 用强化学习的语言表示就是说在动态规划中我们是已知模型的,就是说 在不同状态 state 时我们选择任意行为 action, 所获得的奖励reward和跳转到的新状态是已知的, 不需要我们抽样来学习。而在强化学习问题中我们往往是不知道 奖励值和跳转到的新状态的。
也就是说,这里面我们要说的 策略迭代 和 值迭代 都是在已知模型的情况下,因为这里我们讨论的是动态规划问题,而在强化学习中我们往往不知道模型的情况下我们一般采用 蒙特卡洛 和 时序差分的方法, 其中蒙特卡洛方法需要采样一次完整的决策过程才可以对过程中的决策动作更新Q值,计算量较大,计算不方便,不能单步的改进动作Q值, 因此我们往往采用时序差分的方法,如 Q-learnging 和 Sarsa 方法。这里我们主要讲的是动态规划中的策略迭代和值迭代方法, 也可以看做是强化学习中已知模型的情况下求解最优策略的方法。
策略迭代 方法的代码为:
#encoding:UTF-8 #!/usr/bin/env python3 import random #状态 states=["1", "2"] #动作 actions=["a", "b"] # 奖励的折扣因子 gama=0.99 """ 状态值 v_value v_value={ "1":0, "2":0 }""" v_value={} for state in states: v_value[state]=0 # 动作值 ("1", "a"):0 q_value={} def p_state_reward(state, action): # 输入当前状态,及行为 # return 跳转概率,下一状态, 奖励 if state=="1": if action=="a": return ((1.0/3, "1", 0), (2.0/3, "2", 1)) else: return ((2.0/3, "1", 0), (1.0/3, "2", 1)) if state=="2": if action=="a": return ((1.0/3, "1", 0), (2.0/3, "2", 1)) else: return ((2.0/3, "1", 0), (1.0/3, "2", 1)) # q_value 初始值 """q_value={ ("1", "a"):(1.0/3*()), ("1", "b"):0, ("2", "a"):0, ("2", "b"):0 }""" def q_value_fun(): q_value.clear() for state in states: for action in actions: temp=0 for t in p_state_reward(state, action): temp+=t[0]*(t[2]+gama*v_value[t[1]]) q_value[(state, action)]=temp #q_value初始化 q_value_fun() #策略 pi 初始化 "1":{"a":0.5, "b":0.5} pi={} for state in states: temp={} for action in actions: temp[action]=1.0/len(actions) pi[state]=temp #print(v_value) #print(pi) #print(q_value) #策略评估 得出 v_value 值 def policy_evalue(): global v_value v_value_new={} def v_update(): nonlocal v_value_new v_value_new={} for state in states: temp=0 for action, p in pi[state].items(): temp+=p*q_value[(state, action)] v_value_new[state]=temp #print("v_value: "+str(v_value)) #print("v_value_new: "+str(v_value_new)) def stop_judge(): flag=True for state, value in v_value.items(): if abs(v_value_new[state]-value)>0.0001: flag=False return flag # 计算 v_value_new v_update() while stop_judge()!=True: # 更新 v_value v_value=v_value_new # 更新 q_value q_value_fun() # 再次迭代 计算v_value_new v_update() #策略改进 max def policy_improve(): flag=True for state in states: #L=[] #for action in actions: # L.append((q_value[state, action], action)) #action=max(L)[-1] action=max((q_value[state, action], action) for action in actions)[-1] for k in pi[state]: if k==action: if pi[state][k]!=1.0: pi[state][k]=1.0 flag=False else: pi[state][k]=0.0 return flag if __name__=="__main__": """ policy_evalue() print("*"*30) print(v_value) print("*"*30) print(q_value) print("*"*30) print(pi) """ policy_evalue() flag=policy_improve() i=1 while flag!=True: i+=1 policy_evalue() flag=policy_improve() print("*"*30+"\\n") print("总共运行次数:"+str(i)+"\\n") print("状态值为:") print(v_value) print("") print("行为值为:") print(q_value) print("策略为:") print(pi)
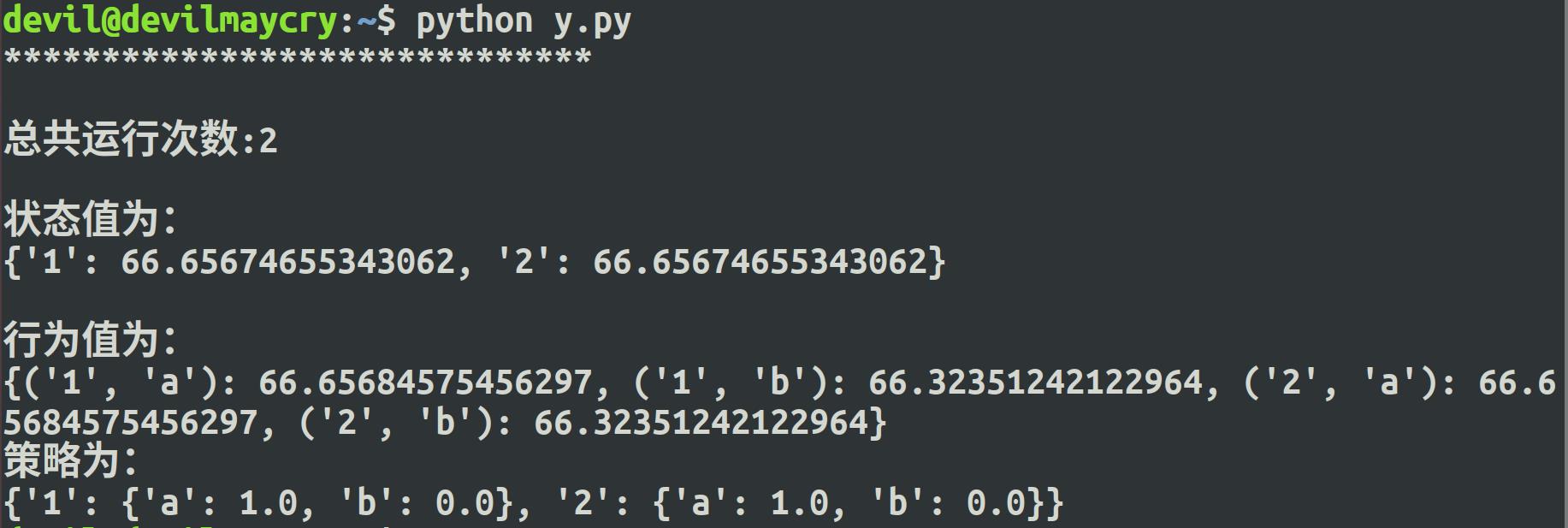
在折扣因子 gama 设置为0.99的情况下, 状态“1”的状态值为66.65674655343062,
状态“2”的状态值为66.65674655343062 。
值迭代 方法的代码为:
#encoding:UTF-8 #!/usr/bin/env python3 import random #状态 states=["1", "2"] #动作 actions=["a", "b"] # 奖励的折扣因子 gama=0.99 """ 状态值 v_value v_value={ "1":0, "2":0 }""" v_value={} for state in states: v_value[state]=0 # 动作值 ("1", "a"):0 q_value={} def p_state_reward(state, action): # 输入当前状态,及行为 # return 跳转概率,下一状态, 奖励 if state=="1": if action=="a": return ((1.0/3, "1", 0), (2.0/3, "2", 1)) else: return ((2.0/3, "1", 0), (1.0/3, "2", 1)) if state=="2": if action=="a": return ((1.0/3, "1", 0), (2.0/3, "2", 1)) else: return ((2.0/3, "1", 0), (1.0/3, "2", 1)) # q_value 初始值 """q_value={ ("1", "a"):(1.0/3*()), ("1", "b"):0, ("2", "a"):0, ("2", "b"):0 }""" def q_value_fun(): q_value.clear() for state in states: for action in actions: temp=0 for t in p_state_reward(state, action): temp+=t[0]*(t[2]+gama*v_value[t[1]]) q_value[(state, action)]=temp #q_value初始化 q_value_fun() # 值迭代方法 def value_iteration(): global v_value flag=True v_value_new={} for state in states: v_value_new[state]=max(q_value[(state, action)] for action in actions) if abs(v_value_new[state]-v_value[state])>0.0001: flag=False if flag==False: v_value=v_value_new q_value_fun() return flag if __name__=="__main__": i=1 flag=value_iteration() while flag!=True: i+=1 flag=value_iteration() #策略 pi pi={} for state in states: act=max((q_value[(state, action)],action) for action in actions)[-1] temp={} for action in actions: if action==act: temp[action]=1.0 else: temp[action]=0.0 pi[state]=temp print("*"*30+"\\n") print("总共运行次数:"+str(i)+"\\n") print("状态值为:") print(v_value) print("") print("行为值为:") print(q_value) print("策略为:") print(pi)
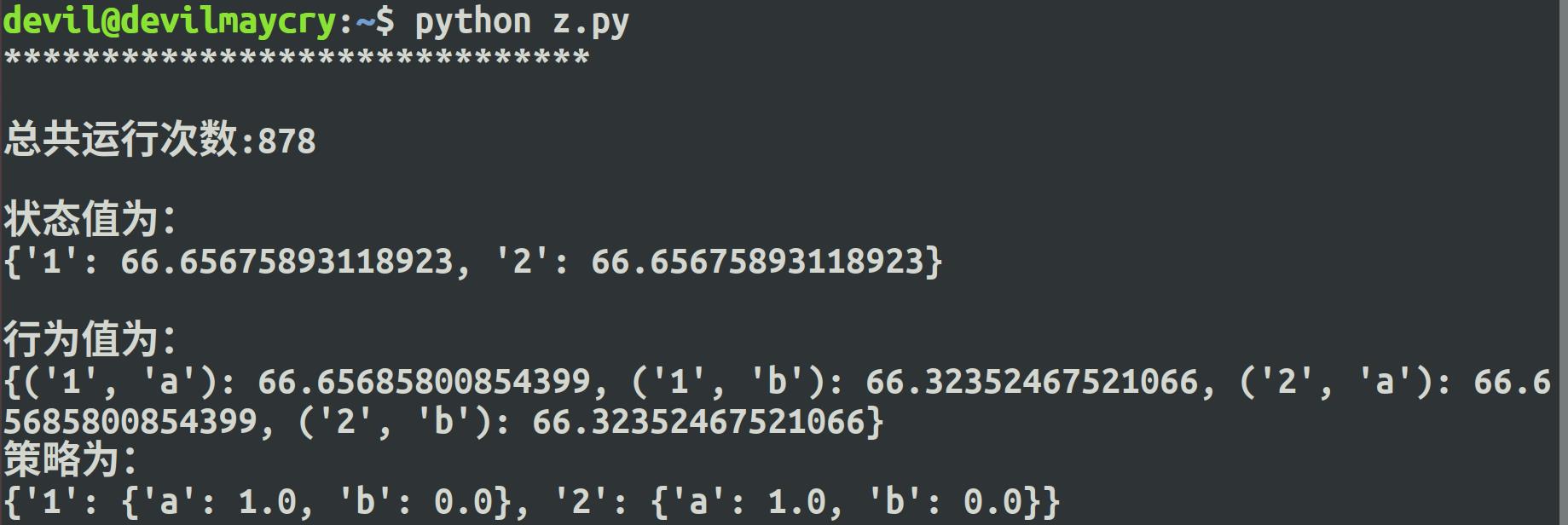
从结果可知:
在折扣因子 gama 设置为0.99的情况下, 状态“1”的状态值为66.65674655343062,
状态“2”的状态值为66.65674655343062 。
可以发现 在超参数相同, gama折扣因子都为0.99 , 两浮点数相同的判断规格都为0.0001, 这时候 策略迭代和值迭代都可以得到相同的策略,同时 状态值v, 和 动作值 q 也都是完全相同的。 在求解上可以视为 策略迭代法和值迭代法是等价的。(允许存在一定误差)
如果假设我们是不知道 奖励值和跳转状态的, 那么我们可以把这个动态规划问题或者说是已知模型的强化学习问题看做是未知模型的强化学习问题。
下面给出这个问题的在未知模型下采用强化学习中的时序差分方法如何解决:
Q—Learning 方法:
#encoding:UTF-8 #!/usr/bin/env python3 import random #动作 actions=["a", "b"] #状态 states=["1", "2"] #构建环境 s, a r s a def next_state_reward(state, action): alfa=random.random() if state=="1": if action=="a": if alfa<=1.0/3: new_state="1" reward=0 else: new_state="2" reward=1 else: if alfa>1.0/3: new_state="1" reward=0 else: new_state="2" reward=1 else: if action=="a": if alfa<=1.0/3: new_state="1" reward=0 else: new_state="2" reward=1 else: if alfa>1.0/3: new_state="1" reward=0 else: new_state="2" reward=1 return new_state, reward # q_value state:{ action:0 } q_value={} for state in states: temp={} for action in actions: temp[action]=0.0 q_value[state]=temp def action_max(state): temp=list(q_value[state].items()) random.shuffle(temp) return max(temp, key=lambda p:p[-1])[0] def action_greedy(state): if random.random()<epsilon: return random.choice(actions) else: return action_max(state) epsilon=0.4 gama=0.99 learning_rate=0.1 def q_learning(): state=random.choice(states) action=action_greedy(state) next_state, reward=next_state_reward(state, action) next_action=action_max(next_state) q_estimate = reward + gama*q_value[next_state][next_action] td_error=q_estimate - q_value[state][action] q_value[state][action]+=learning_rate*td_error if __name__=="__main__": for episode in range(10**6): q_learning() epsilon=0.01 for episode in range(10**5): q_learning() print(q_value)
Sarsa 方法:
#encoding:UTF-8 #!/usr/bin/env python3 import random #动作 actions=["a", "b"] #状态 states=["1", "2"] #构建环境 s, a r s a def next_state_reward(state, action): alfa=random.random() if state=="1": if action=="a": if alfa<=1.0/3: new_state="1" reward=0 else: new_state="2" reward=1 else: if alfa>1.0/3: new_state="1" reward=0 else: new_state="2" reward=1 else: if action=="a": if alfa<=1.0/3: new_state="1" reward=0 else: new_state="2" reward=1 else: if alfa>1.0/3: new_state="1" reward=0 else: new_state="2" reward=1 return new_state, reward # q_value state:{ action:0 } q_value={} for state in states: temp={} for action in actions: temp[action]=0.0 q_value[state]=temp def action_max(state): temp=list(q_value[state].items()) random.shuffle(temp) return max(temp, key=lambda p:p[-1])[0] def action_greedy(state): if random.random()<epsilon: return random.choice(actions) else: return action_max(state) epsilon=0.4 gama=0.99 learning_rate=0.1 def sarsa_learning(): state=random.choice(states) action=action_greedy(state) next_state, reward=next_state_reward(state, action) #next_action=action_max(next_state) next_action=action_greedy(next_state) q_estimate = reward + gama*q_value[next_state][next_action] td_error=q_estimate - q_value[state][action] q_value[state][action]+=learning_rate*td_error if __name__=="__main__": for episode in range(10**6): sarsa_learning() #epsilon=0.01 #for episode in range(10**5): # q_learning() #print(q_value)
分别运行 Q-Learning 和 Sarsa 方法多次,发现 Q-Learning估计的结果确实普遍比真实值高,但是一个新的发现是Sarsa方法估计的V值普遍比真实值低,至于为什么评估出的结果和真实值有这样的误差也是搞不清楚的,不过这个问题是强化学习这几十年来最火的一个问题,各种说法都有,今年NIPS会议上最佳论文之一也是讨论如何解决和解释这个问题的, Q-Learning和Sarsa 方法很简单,但是为了说明它居然用了几十年还没有解决,这确实要人不好说呀。
==========================================================================
以上是关于动态规划中 策略迭代 和 值迭代 的一个小例子的主要内容,如果未能解决你的问题,请参考以下文章