Directx11教程(14) D3D11管线
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Directx11教程(14) D3D11管线相关的知识,希望对你有一定的参考价值。
下面我们来了解一些GPU memory的知识,主要参考资料:http://fgiesen.wordpress.com/0211/07/02/a-trip-through-the-graphics-pipeline-2011-part-2
现在gpu上常用的video memory是GDDR5,和主机上常用的内存ddr3比起来,它具有带宽高,时延长的特点。 DRAM芯片通常被组织成2维grid的形式,每个交叉点都是由一个晶体管和电容组成,每个交叉点表示memory一个地址位。比如1G GDDR5显存,它被组织32个GDDR5 块:

每个32M的block,包括4个bank 分组,每个bank分组包括16个(或者32)bank。

每个bank由一个2维grid的DRAM芯片组成:

行地址是A0-A11,共4k,列地址A0-A5,共64,所以一个bank内space是256k
通常DRAM是按照行读写的,所以我们要得到好的读写效率,最好一次把一行数据读完。GDDR5的Pagesize通常是2k。
【注:上面对DRAM的理解有些错误,正在学习DRAM的知识,请参考另一篇日志,老狼:2012-11-13:http://www.cnblogs.com/mikewolf2002/archive/2012/11/13/2768804.html】
下面我们看下memory 如何与GPU和 host连接,了解video memory的工作flow:
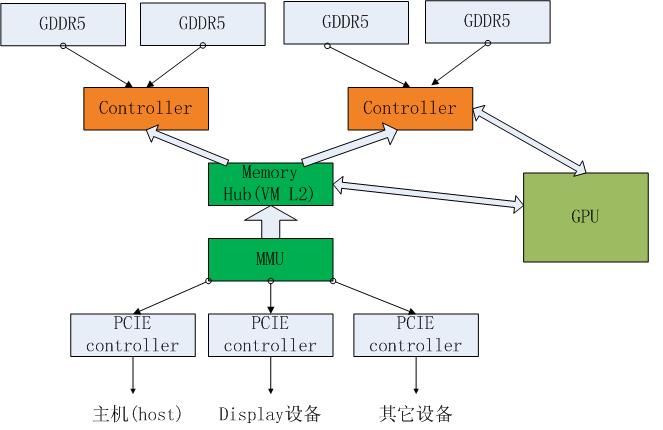
GPU中一些快速的client,比如Depth block,color block,texture block等都是直接和MC连接,而一些数据量不是很大的block,比如command processor(CP)要经过hub,然后再到传到相应的MC(Memory controller)。
在hub中,也许有VM L2, 会进行一些page table的查找,之后请求被路由到相应的MC,MC中主要包括client interface, VM L1, arb等模块。Client infterface会和不同的client打交道,然后把它们传递到VM L1,进行page table的查找,最后进过ARB仲裁,进入到相应的GDDR中。GPU的MC通常都是32bit的,而DDR3的MC通常是64位,我们可以通过下面公式计算得到gpu的memory带宽:mclk * datarate* channelwidth*channel number/8/1000, 简化即为:mclk*4*32*channel number/8/1000, 假设显卡有12 个mc channel,则memory带宽为:1375*4*12*32/8/1000=264GB/s

其它的一些PCIE设备和主机,都是通过PCIE总线,然后进入MMU(内存管理单元),再进入hub,这儿MMU是一个总称,在不同实现中,可能MMU包括很多block。
GPU和主机以及其它设备的交互都是通过PCIE总线进行的,GPU和主机之间通常使用PCIE2.0 16 lane(最新的显卡使用PCIE3.0), 上行、下行都达到了8GB/s,其它慢速设备,比如display可能只需要4lane就够了。
PCIE的详细介绍见:http://www.cnblogs.com/mikewolf2002/archive/2012/03/20/2408389.html
以上是关于Directx11教程(14) D3D11管线的主要内容,如果未能解决你的问题,请参考以下文章
DirectX11第二篇 DirectX11渲染管线(2016.05.09更新)