ThreadPoolExecutor的一点理解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ThreadPoolExecutor的一点理解相关的知识,希望对你有一定的参考价值。
整个ThreadPoolExecutor的任务处理有4步操作:
- 第一步,初始的poolSize < corePoolSize,提交的runnable任务,会直接做为new一个Thread的参数,立马执行
- 第二步,当提交的任务数超过了corePoolSize,就进入了第二步操作。会将当前的runable提交到一个block queue中
- 第三步,如果block queue是个有界队列,当队列满了之后就进入了第三步。如果poolSize < maximumPoolsize时,会尝试new 一个Thread的进行救急处理,立马执行对应的runnable任务
- 第四步,如果第三步救急方案也无法处理了,就会走到第四步执行reject操作。
- block queue有以下几种实现:
1. ArrayBlockingQueue : 有界的数组队列
2. LinkedBlockingQueue : 可支持有界/无界的队列,使用链表实现
3. PriorityBlockingQueue : 优先队列,可以针对任务排序
4. SynchronousQueue : 队列长度为1的队列,和Array有点区别就是:client thread提交到block queue会是一个阻塞过程,直到有一个worker thread连接上来poll task。 - RejectExecutionHandler是针对任务无法处理时的一些自保护处理:
1. Reject 直接抛出Reject exception
2. Discard 直接忽略该runnable,不可取
3. DiscardOldest 丢弃最早入队列的的任务
4. CallsRun 直接让原先的client thread做为worker线程,进行执行
maximumPoolSize >= corePoolSize =期望的最大线程数。 (我曾经配置了corePoolSize=1, maximumPoolSize=20, blockqueue为无界队列,最后就成了单线程工作的pool。典型的配置错误)
http://www.iteye.com/topic/1118660
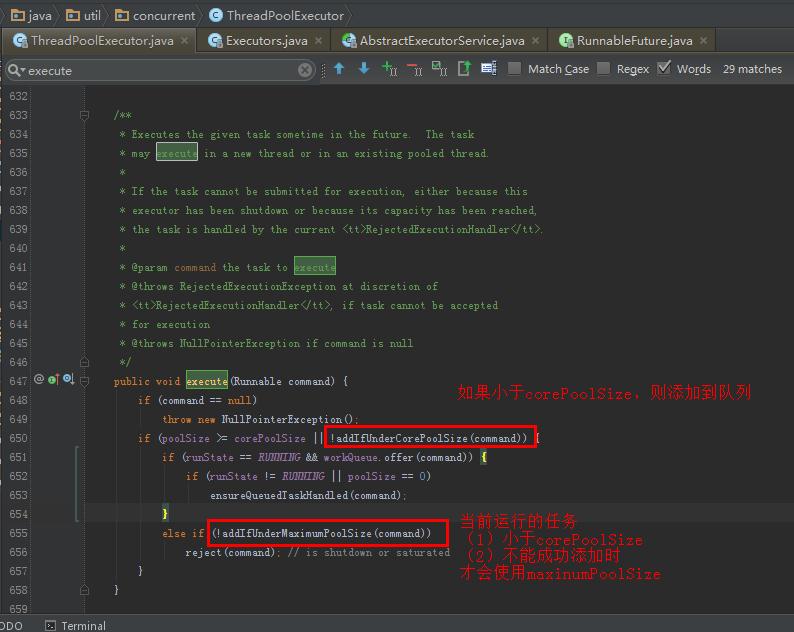
/** * Creates and starts a new thread running firstTask as its first * task, only if fewer than corePoolSize threads are running * and the pool is not shut down. * @param firstTask the task the new thread should run first (or * null if none) * @return true if successful */ private boolean addIfUnderCorePoolSize(Runnable firstTask) { Thread t = null; final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { if (poolSize < corePoolSize && runState == RUNNING) t = addThread(firstTask); } finally { mainLock.unlock(); } return t != null; }
/** * Creates and starts a new thread running firstTask as its first * task, only if fewer than maximumPoolSize threads are running * and pool is not shut down. * @param firstTask the task the new thread should run first (or * null if none) * @return true if successful */ private boolean addIfUnderMaximumPoolSize(Runnable firstTask) { Thread t = null; final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { if (poolSize < maximumPoolSize && runState == RUNNING) t = addThread(firstTask); } finally { mainLock.unlock(); } return t != null; }
/** * Creates and returns a new thread running firstTask as its first * task. Call only while holding mainLock. * * @param firstTask the task the new thread should run first (or * null if none) * @return the new thread, or null if threadFactory fails to create thread */ private Thread addThread(Runnable firstTask) { Worker w = new Worker(firstTask); Thread t = threadFactory.newThread(w); boolean workerStarted = false; if (t != null) { if (t.isAlive()) // precheck that t is startable throw new IllegalThreadStateException(); w.thread = t; workers.add(w); int nt = ++poolSize;//唯一操作poolSize的地方 if (nt > largestPoolSize) largestPoolSize = nt; try { t.start(); workerStarted = true; } finally { if (!workerStarted) workers.remove(w); } } return t; }
/** * A handler for rejected tasks that runs the rejected task * directly in the calling thread of the <tt>execute</tt> method, * unless the executor has been shut down, in which case the task * is discarded. */ public static class CallerRunsPolicy implements RejectedExecutionHandler { /** * Creates a <tt>CallerRunsPolicy</tt>. */ public CallerRunsPolicy() { } /** * Executes task r in the caller‘s thread, unless the executor * has been shut down, in which case the task is discarded. * @param r the runnable task requested to be executed * @param e the executor attempting to execute this task */ public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { r.run(); } } } /** * A handler for rejected tasks that throws a * <tt>RejectedExecutionException</tt>. */ public static class AbortPolicy implements RejectedExecutionHandler { /** * Creates an <tt>AbortPolicy</tt>. */ public AbortPolicy() { } /** * Always throws RejectedExecutionException. * @param r the runnable task requested to be executed * @param e the executor attempting to execute this task * @throws RejectedExecutionException always. */ public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { throw new RejectedExecutionException(); } } /** * A handler for rejected tasks that silently discards the * rejected task. */ public static class DiscardPolicy implements RejectedExecutionHandler { /** * Creates a <tt>DiscardPolicy</tt>. */ public DiscardPolicy() { } /** * Does nothing, which has the effect of discarding task r. * @param r the runnable task requested to be executed * @param e the executor attempting to execute this task */ public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { } } /** * A handler for rejected tasks that discards the oldest unhandled * request and then retries <tt>execute</tt>, unless the executor * is shut down, in which case the task is discarded. */ public static class DiscardOldestPolicy implements RejectedExecutionHandler { /** * Creates a <tt>DiscardOldestPolicy</tt> for the given executor. */ public DiscardOldestPolicy() { } /** * Obtains and ignores the next task that the executor * would otherwise execute, if one is immediately available, * and then retries execution of task r, unless the executor * is shut down, in which case task r is instead discarded. * @param r the runnable task requested to be executed * @param e the executor attempting to execute this task */ public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { e.getQueue().poll(); e.execute(r); } } }
看一眼Executors代码的基本就清楚了,手机客户端时多线程处理数据尤其注意要reject丢弃老的请求就好了,服务端的考虑服务器并发能力,和处理的延迟做一个权衡。
客户端:如果客户端线程池采取拉的方式,因为切换一个页面前面请求其实可以丢弃,设置成大致这样表示客户端只处理最近的请求,大致可以设置成如下这样
new ThreadPoolExecutor(1, 3, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(5),new ThreadPoolExecutor.DiscardOldestPolicy());
服务端一般这两种情况使用比较多,一种请求及时性要求比较高并不希望被前面请求阻塞一般就是
Executors.newCachedThreadPool(threadFactory);
另一种就是类似,邮件,消息服务,大多数时间请求量大,但是可以接受延迟
Executors.newFixedThreadPool(2*coreSize+1)
还有就是定制,被拒绝的和抛弃放入可持久化队列,后面根据情况处理。
Btrace容量规划
再提供一个btrace脚本,分析线上的thread pool容量规划是否合理,可以运行时输出poolSize等一些数据。
import static com.sun.btrace.BTraceUtils.addToAggregation; import static com.sun.btrace.BTraceUtils.field; import static com.sun.btrace.BTraceUtils.get; import static com.sun.btrace.BTraceUtils.newAggregation; import static com.sun.btrace.BTraceUtils.newAggregationKey; import static com.sun.btrace.BTraceUtils.printAggregation; import static com.sun.btrace.BTraceUtils.println; import static com.sun.btrace.BTraceUtils.str; import static com.sun.btrace.BTraceUtils.strcat; import java.lang.reflect.Field; import java.util.concurrent.atomic.AtomicInteger; import com.sun.btrace.BTraceUtils; import com.sun.btrace.aggregation.Aggregation; import com.sun.btrace.aggregation.AggregationFunction; import com.sun.btrace.aggregation.AggregationKey; import com.sun.btrace.annotations.BTrace; import com.sun.btrace.annotations.Kind; import com.sun.btrace.annotations.Location; import com.sun.btrace.annotations.OnEvent; import com.sun.btrace.annotations.OnMethod; import com.sun.btrace.annotations.OnTimer; import com.sun.btrace.annotations.Self; /** * 并行加载监控 * * @author jianghang 2011-4-7 下午10:59:53 */ @BTrace public class AsyncLoadTracer { private static AtomicInteger rejecctCount = BTraceUtils.newAtomicInteger(0); private static Aggregation histogram = newAggregation(AggregationFunction.QUANTIZE); private static Aggregation average = newAggregation(AggregationFunction.AVERAGE); private static Aggregation max = newAggregation(AggregationFunction.MAXIMUM); private static Aggregation min = newAggregation(AggregationFunction.MINIMUM); private static Aggregation sum = newAggregation(AggregationFunction.SUM); private static Aggregation count = newAggregation(AggregationFunction.COUNT); @OnMethod(clazz = "java.util.concurrent.ThreadPoolExecutor", method = "execute", location = @Location(value = Kind.ENTRY)) public static void executeMonitor(@Self Object self) { Field poolSizeField = field("java.util.concurrent.ThreadPoolExecutor", "poolSize"); Field largestPoolSizeField = field("java.util.concurrent.ThreadPoolExecutor", "largestPoolSize"); Field workQueueField = field("java.util.concurrent.ThreadPoolExecutor", "workQueue"); Field countField = field("java.util.concurrent.ArrayBlockingQueue", "count"); int poolSize = (Integer) get(poolSizeField, self); int largestPoolSize = (Integer) get(largestPoolSizeField, self); int queueSize = (Integer) get(countField, get(workQueueField, self)); println(strcat(strcat(strcat(strcat(strcat("poolSize : ", str(poolSize)), " largestPoolSize : "), str(largestPoolSize)), " queueSize : "), str(queueSize))); } @OnMethod(clazz = "java.util.concurrent.ThreadPoolExecutor", method = "reject", location = @Location(value = Kind.ENTRY)) public static void rejectMonitor(@Self Object self) { String name = str(self); if (BTraceUtils.startsWith(name, "com.alibaba.pivot.common.asyncload.impl.pool.AsyncLoadThreadPool")) { BTraceUtils.incrementAndGet(rejecctCount); } } @OnTimer(1000) public static void rejectPrintln() { int reject = BTraceUtils.getAndSet(rejecctCount, 0); println(strcat("reject count in 1000 msec: ", str(reject))); AggregationKey key = newAggregationKey("rejectCount"); addToAggregation(histogram, key, reject); addToAggregation(average, key, reject); addToAggregation(max, key, reject); addToAggregation(min, key, reject); addToAggregation(sum, key, reject); addToAggregation(count, key, reject); } @OnEvent public static void onEvent() { BTraceUtils.truncateAggregation(histogram, 10); println("---------------------------------------------"); printAggregation("Count", count); printAggregation("Min", min); printAggregation("Max", max); printAggregation("Average", average); printAggregation("Sum", sum); printAggregation("Histogram", histogram); println("---------------------------------------------"); } }
运行结果:
poolSize : 1 , largestPoolSize = 10 , queueSize = 10
reject count in 1000 msec: 0
说明:
1. poolSize 代表为当前的线程数
2. largestPoolSize 代表为历史最大的线程数
3. queueSize 代表blockqueue的当前堆积的size
4. reject count 代表在1000ms内的被reject的数量
此文基于hotspot1.7.0(build 1.7.0-b147),1.6及以前的版本与1.7的版本实现上差别很大。线程池的逻辑非常复杂,原因在于线程池是有状态的(不是狭隘的指RUNNING,SHUTDOWN这些状态,而是一个类的状态,可以理解成对象的共享字段),而为了保证可伸缩性与效率,很多地方在访问这些状态的时候都没有使用锁来保证互斥访问,而采用的是多次检测。这意味着会有很多竞态条件的出现,在分析某个方法的时候,要同时想到多线程间多个方法的交互,要考虑它们的交错执行。这里只分析核心重要的方法,其它方法相对简单,就不多言了。
首先来看下对外接口中关键的execute方法,其实现如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
先判断传入的参数command是否为null,为null就抛出NullPointerException。然后通过workerCountOf方法从ctl所表示的int值中提取出低29位的值,也就是当前活动的线程数,如果当前活动的线程数小于corePoolSize,则增加一个线程(addWorker,接下来会讲解这个方法,其返回值表示是否新增线程成功)来执行新传入的任务。什么概念?也就是说当池中的线程数小于corePoolSize的时候,不管池中的线程是否有空闲的,每次调用该方法都去增加一个线程,直到池中的数目达到corePoolSize为止。如果新增线程成功,则由新线程执行传入的任务command。在这里有可能出现增加线程失败的情况(原因在解释addWorker的时候讲),那就要当做池中当前线程数超过corePoolSize的情况进行处理。也就是进入第三个if里,若当前线程池的状态为RUNNING状态,且将任务command加入队列成功,就会执行if内的逻辑。先讲此if对应的else里的情况,若在执行execute的时候同时有其它线程执行了shutdown方法,而这两个方法不是互斥的,就有竞态条件问题,execute方法之前判断状态为RUNNING,而执行了几条语句后可能池的状态已经变掉了,因此,如果池的状态不为RUNNING或在将command加入队列失败的时候(失败可能是有界队列满了),两种情况要分开处理,当只是状态仍为RUNNING,而队列满的时候,若池中当前活动的线程数小于maximumPoolSize,则会往池中添加线程,若添线程数已经达到了maximumPoolSize或其它原因导致新增线程失败,就会拒绝该任务(reject(command))。 当状态不为RUNNING的时候,if里的addWorker(command, false)操作将直接返回false,使得if条件为true,也会拒绝这个任务。再继续前面往队列里加入任务成功的处理方式。加入任务成功后,会再次检测池的状态是否为RUNNING,若不是,则从池中移出并拒绝该任务,这也就是说,当池的被SHUTDOWN后,将不再接受新任务。这些检查若都没问题,还需要看看池中的活动线程数有没有变成0(执行的任务抛出异常等导致),若为0,则往里加入一个线程,该线程回去队列里拿任务执行。如果一次性往队列里提交了很多任务,而池中的每个任务执行都抛出异常,那么会不会导致剩余的任务得不到执行?显然不会,这个在后面再讲。
接下来介绍上面提到的addWorker方法,方法实现如下:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
Worker w = new Worker(firstTask);
Thread t = w.thread;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int c = ctl.get();
int rs = runStateOf(c);
if (t == null ||
(rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null))) {
decrementWorkerCount();
tryTerminate();
return false;
}
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
} finally {
mainLock.unlock();
}
t.start();
if (runStateOf(ctl.get()) == STOP && ! t.isInterrupted())
t.interrupt();
return true;
}
这个代码有点儿长,addWorker有两个参数:Runnable类型的firstTask,用于指定新增的线程执行的第一个任务;boolean类型的core,true表示在新增线程时会判断当前活动线程数是否少于corePoolSize,false表示新增线程前需要判断当前活动线程数是否少于maximumPoolSize。该方法的返回值代表是否成功新增一个线程。这个方法为for循环加了一个标签,for循环里,做了很多事情。首先通过runStateOf方法取出存储在ctl中的状态值,第一个if里的条件有些小复杂:rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty()),又是与又是非的,转换成一个等价实现:rs >= SHUTDOWN && (rs != SHUTDOWN || firstTask != null || workQueue.isEmpty()),如果已经调用了SHUTDOWN,池的状态改变后,第一个条件rs >= SHUTDOWN就为true,后面括号里只要有一个条件为真就返回一个新增线程失败的标识。rs != SHUTDOWN结合前面的rs >= SHUTDOWN,表示线程池的状态已经由SHUTDOWN转为剩余的三个状态之一了,此时就要拒绝这个传入的任务;括号里的第二个条件表示状态已经为非运行状态了,却传入了一个任务,这个任务也要拒绝;括号里的第三个条件表示线程池的状态不为RUNNING,但队列中没有任务了,就不需要新增线程了。然后使用一个嵌套循环,来解析下这个循环吧,纵观下,有break标签,continue标签,是不是很不好理解?所以,写代码时避免使用标签。跑题了,继续解释。这个嵌套循环里首先用workerCountOf方法取出当前活动的线程数。若当前活动线程数超过低29位能表示的最大值(也就是容量)时就不能再加线程了,因为再加就会影响状态的值了!若传入的参数core参数为true,则当前活动的线程数要小于corePoolSize才能创建新线程,大于或等于corePoolSize就不能再创建了;若core参数为false,则当前活动的线程数要小于maximumPoolSize才能创建新线程,大于或等于maximumPoolSize就不能再创建了。接下来使用CAS操作将当前活动线程数加一(compareAndIncrementWorkerCount方法,使用原子的compareAndSet来替换旧值。但并不保证成功,若成功,该方法返回true;若失败,则返回false),当加一成功,则跳出大循环,进入循环体后面的真正新增线程的地方;若加一不成功,判断下当前状态改变没有,若改变了则重新开始外层循环的下一次迭代,若状态没有改变,只是加一失败,那么就继续内层循环,直到加一成功。往当前活动线程数加一成功后,就会来真的新增线程了(先加一后新增线程可以避免锁的使用,使用CAS原子操作加一后,其它线程看到的就是加一后的值,若达到上限,其它线程就不会去创建新线程了。若先创建线程,再去加一,若不加锁,假如一个使用无界队列的线程池,当前活动线程数为corePoolSize少一,外部线程在执行execute的时候都发现线程数不足corePoolSize,都去创建线程,而最终只能有一个线程进入线程池,其它的都得作废,而加锁可以解决这个问题,但是降低了线程池的可伸缩性)。
接下来看如何新增线程的。Worker w = new Worker(firstTask),在Worker的构造方法中,创建了一个线程对象,但这个线程是没有启动的。在构造方法中启动线程,会导致this对象泄露,让线程看到未完整构建的对象,这个要避免。既然不能在构造方法里启动,那么就把创建的线程对象拿出来吧,也就是赋给了t变量。因为整个过程并不是互斥的,所以创建完线程对象后再来判断下当前池的状态,接下来的判断又比较复杂:t == null || (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null)),转换成一个容易看懂的等价实现:t == null || (rs >= SHUTDOWN && (rs != SHUTDOWN || firstTask != null))。里面有个t==null?为啥会出现t==null? Worker的构造方法是通过调用getThreadFactory().newThread(this)方法来创建线程的,而newThread方法可能会返回null(threadFactory可以通过ThreadPoolExecutor的构造方法传入,如没有传入,有个默认实现)。当创建线程失败要减少当前活动线程数;当池的状态非RUNNING和SHUTDOWN的时候,也需要减少当前活动线程数,并要尝试终止线程池;当线程池的状态为非RUNNING,且有初始任务要执行的时候,因为这个状态要拒绝新进来的任务,所以这个新增的线程也没有用处了。当状态判断没有问题时,就会将创建的Worker对象加入到workers字段中(线程终止时会从里面移除,后面会讲到),当池中的工作线程创新高时,会将这个数记录到largestPoolSize字段中。然后就可以启动这个线程t了。若start后,状态又变成了SHUTDOWN状态(如调用了shutdownNow方法)且新建的线程没有被中断过,就要中断该线程(shutdownNow方法要求中断正在执行的线程),shutdownNow方法本身也会去中断存储在workers中的所有线程,为什么这里还有自己处理下呢?中断所有线程的时候需要持有mainLock锁,而添加Worker对象到workers字段中也要持有mainLock锁,所以存在这样一种很难出现的场景:在将Worker对象加入workers字段,释放mainLock锁之后,Worker对象中的线程(即t)启动前,shutdownNow获得了mainLock锁并完成了所有中断操作,而当线程对象还没调用start之前调用该线程的interrupt方法是无效的。所以,t启动后的这段小代码就是为了防止这种极端情况的出现。
在继续其他方法之前,先说下Worker这个内部类。Worker实现了Runnable接口,可以在后续作为Thread的构造方法参数用以创建线程。同时,Worker还继承了AbstractQueuedSynchronizer类,只是简化每个Worker对象相关的锁的获取,在每次执行一个任务的时候,都需要持有这个锁。在以前的ThreadPoolExecutor实现中,并没有继承AbstractQueuedSynchronizer,而是在Worker内部声明了一个对象字段private final ReentrantLock runLock = new ReentrantLock(),每次执行一个任务的时候,需要对runLock加锁。
接下来我们看一下每次新增一个线程后这个线程都做了些什么,显然需要看看Worker的run方法:
public void run() {
runWorker(this);
}
只是简单的调用了runWorker方法,继续看runWorker:
final void runWorker(Worker w) {
Runnable task = w.firstTask;
w.firstTask = null;
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
clearInterruptsForTaskRun();
try {
beforeExecute(w.thread, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
这个方法逻辑很简单。还记得前面提到的新增线程时指定第一个任务吗?若存在第一个任务,则先执行第一个任务,否则,从队列中拿任务,不断的执行,直到getTask返回null或执行任务出错(中断或任务本身抛出异常),就退出while循环。getTask方法后面会详细讲解。当有任务执行时(之前通过参数传入的第一个任务或从队列中获取的任务),需要做一个状态判断。也就是clearInterruptsForTaskRun方法,来看看这个方法干了什么:
private void clearInterruptsForTaskRun() {
if (runStateLessThan(ctl.get(), STOP) &&
Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))
Thread.currentThread().interrupt();
}
if条件里的内容为runStateLessThan(ctl.get(), STOP) && Thread.interrupted() && runStateAtLeast(ctl.get(), STOP),这里利用了&&的短路特性,当前一个条件为true的时候才去执行后面一个条件。当当前状态小于STOP时,也就是当前状态为RUNNING时,需要清除线程的中断状态(线程池为RUNNING状态,线程却的中断状态却为true,可能在上次执行的任务里调用了类似Thread.currentThread().interrupt()的方法,因此当然不能让接下来执行的任务受之前任务的影响),如果Thread.interrupted()返回false,表示以前没有设置过中断,整个if的结果就是false;如果Thread.interrupted()返回true,那就要考虑为什么会是true了。是RUNNING状态就已经被中断了还是判断第一个条件后另外一个非池中的线程调用了shutdownNow中断了该线程?如果是后者,表示正在执行的任务需要中断,所以第三个条件判断当前池的状态是否不为RUNNING,如果不为RUNNING,那么就要重新中断该线程以维护shutdownNow方法的语义。
在真正执行任务之前,调用了beforeExecute方法,这是一个钩子方法,用户可以继承ThreadPoolExecutor重写beforeExecute方法来做一些事情。接下来就是真正执行任务的时候,执行完了(正常执行结束或抛出异常)会调用afterExecute方法,afterExecute也是个钩子方法,同beforeExecute方法。随后将task变量置为null,让其再从队列里接收任务,若不置为null,就满足while的第一个条件了,结果就是这个任务被死循环执行。然后将该线程完成的任务数自增。只有当线程终止的时候,才会将该线程执行的任务总数加到线程池的completedTaskCount中,所以completedTaskCount这个值并不是一个准确值。在最后有一个将completedAbruptly置为false的操作,如果线程能走到这里来,说明该线程在执行任务过程中没有抛出异常,也就是说该线程并不是异常结束的,而是正常结束的;如果走不到这一步,completedAbruptly的值还是初始值true,表示线程是异常结束的。线程结束时,会调用processWorkerExit方法做一些清理和数据同步的工作:
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // If abrupt, then workerCount wasn‘t adjusted
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
tryTerminate();
int c = ctl.get();
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}
http://www.ticmy.com/?p=243
以上是关于ThreadPoolExecutor的一点理解的主要内容,如果未能解决你的问题,请参考以下文章