论文笔记--Fast RCNN
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记--Fast RCNN相关的知识,希望对你有一定的参考价值。
很久之前试着写一篇深度学习的基础知识,无奈下笔之后发现这个话题确实太大,今天发一篇最近看的论文Fast RCNN。这篇文章是微软研究院的Ross Girshick大神的一篇作品,主要是对RCNN的一些改进,但是效果十分明显,paper和项目的地址都能从Ross Girshick的主页找到:http://people.eecs.berkeley.edu/~rbg/
刚刚接触深度学习,难免纰漏很多,还请大神指教。
自己的百度云里也有一些相关内容http://pan.baidu.com/s/1o79NZ2E
文字内容大多是自己讲解时的PPT的内容。
背景介绍
Fast rcnn是针对RCNN+SPP-NET的改进,改进的原因是:
1.RCNN在训练时是一个多阶段,各个pipeline是隔离的。
2.RCNN在训练时很消耗时间和空间。
3.物体检测很慢。
1.RCNN
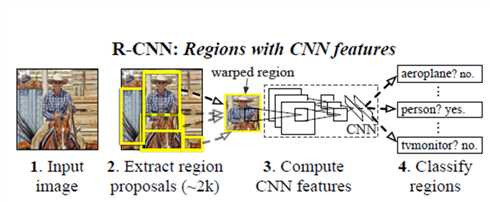
RCNN的结构示意图
首先看一下RCNN的框架图,大概的工作过程是:
- takes an input image,
- extracts around 2000 bottom-up region proposals,
- computes features for each proposal using a large convolutional neural network (CNN)
- classifies each region using class-specific linear SVMs.
详细的说一下就是:首先输入一张图片,通过selective search获得约2K个proposal(也就是candidate object locations),之后对图像进行伸缩变换,把图像变为固定尺寸的照片,之后把固定尺寸之后的图片传入CNN网络中进行提取特征等操作,之后使用SVM分类器进行分类。
由此可以看出RCNN有这样的缺点:
- 训练的时候,pipeline是隔离的,先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression。
- 训练时间和空间开销大。RCNN中ROI-centric的运算开销大,所以FRCN用了image-centric的训练方式来通过卷积的share特性来降低运算开销;RCNN提取特征给SVM训练时候需要中间要大量的磁盘空间存放特征,FRCN去掉了SVM这一步,所有的特征都暂存在显存中,就不需要额外的磁盘空间了。
由此看一看出RCNN的问题所在,首先在提取完proposal之后,整个网络对提取到的RCNN中的所有的proposal都进行了整套的提取特征这些操作,这些操作是非常耗时,耗费空间的。事实上我们并不需要对每个proposal都进行CNN操作,只需要对原始的整张图片进行CNN操作即可,因为我们所提取到的proposal属于整张图片,因此对整张图片提取出feature map之后,再找出对应proposal在feature map中对应的区域,进行对比分类即可。第二个问题所在就是在框架中2-3过程中的对提取到的区域进行变形,我们知道CNN提取特征的过程对图像的大小并无要求,只是在提取完特征,进行全连接的时候才需要固定尺寸的特征,然后使用SVM等分类器进行分类操作,当然这两个问题在SPP -NET中得到了很好的解决。
2.SPP NET
引入原因:在RCNN中,使用完ss提取proposal之后,对每个proposal都进行了CNN提取特征+SVM分类。
解决方法:因为region proposal都是图像的一部分,我们只需要对图像提一次卷积层特征,然后将region proposal在原图的位置映射到卷积层特征图上,这样对于一张图像我们只需要提一次卷积层特征,然后将每个region proposal的卷积层特征输入到全连接层做后续操作。
更直白的讲就是SPP-NET代替卷积网络中最后一个pooling层,而且这pooling层是多scale的。
接下来看一下SPPNET的框架图
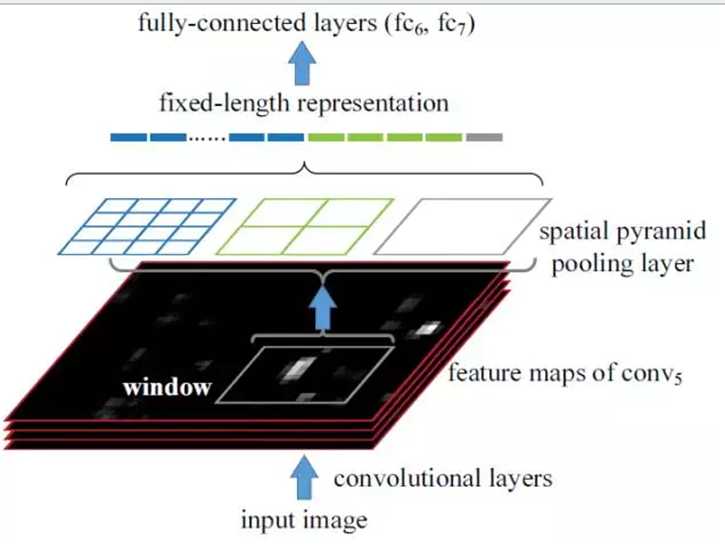
SPPNET框架图
图中叠在一起的四个黑色方框是输入图像经过卷积层得到的特征图(feature maps of conv5),图中叫window的方框就是我们proposal在feature map中的对应位置,之后我们使用空间金字塔pooling层对这块区域进行池化,得到一个固定尺寸的向量,之后再加入到全连接层中。
(这一篇论文正在看,先写一部分大概内容,以后进行系统点补充)
关于Fast RCNN
FRCNN针对RCNN在训练时是multi-stage pipeline和训练的过程中很耗费时间空间的问题进行改进。
- 最后一个卷积层后加了一个ROI pooling layer。ROI pooling layer首先可以将image中的ROI定位到feature map,然后是用一个单层的SPP layer将这个feature map patch池化为固定大小的feature之后再传入全连接层。
- 损失函数使用了多任务损失函数(multi-task loss),将边框回归直接加入到CNN网络中训练。
接下来看一下FRCNN的框架图
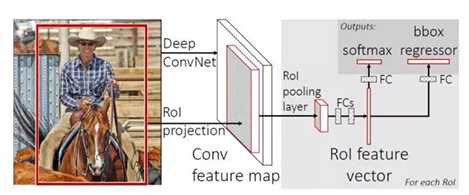
FRCNN的框架图
图中省略了通过ss获得proposal的过程,第一张图中红框里的内容即为通过ss提取到的proposal,中间的一块是经过深度卷积之后得到的conv feature map,图中灰色的部分就是我们红框中的proposal对应于conv feature map中的位置,之后对这个特征经过ROI pooling layer处理,之后进行全连接。在这里得到的ROI feature vector最终被分享,一个进行全连接之后用来做softmax回归,用来进行分类,另一个经过全连接之后用来做bbox回归。
关于multi-task loss
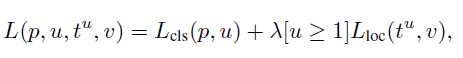
参数含义:
p = (p0; : : : ; pK), over K + 1 categories.P是通过k+1个全连接层输出使用softmax计算得到的。
v=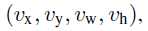
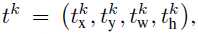
未完待续....
以上是关于论文笔记--Fast RCNN的主要内容,如果未能解决你的问题,请参考以下文章
读论文系列:Object Detection ICCV2015 Fast RCNN