MapReduce表连接之半连接SemiJoin
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce表连接之半连接SemiJoin相关的知识,希望对你有一定的参考价值。
一:背景
SemiJoin,一般称为半连接,其原理是在Map端过滤掉一些不需要join的数据,从而大大减少了reduce和Shuffle的时间,因为我们知道,如果仅仅使用Reduce端连接,那么如果一份数据,存在大量的无效数据,而这些数据在join中并不需要,但是因为没有做过预处理,所以这些数据直到真正执行reduce函数时,才被定义为无效数据,但是这个时候已经执行过了Shuffle、merge还有sort操作,所以这部分无效的数据就浪费了大量的网络IO和磁盘IO,所以在整体来讲,这是一种降低性能的表现,如果存在的无效数据越多,那么这种趋势就越明显。之所以会出现半连接,这其实是reduce端连接的一个变种,只不过是我们在Map端过滤掉了一些无效的数据,所以减少了reduce过程的Shuffle时间,所以能获取一个性能的提升。
二:技术实现
(1):利用DistributedCache将小表分发到各个节点上,在Map过程的setup()函数里,读取缓存里的文件,只将小表的连接键存储在hashSet中。
(2):在map()函数执行时,对每一条数据进行判断,如果这条数据的连接键为空或者在hashSet里不存在,那么则认为这条数据无效,使条数据也不参与reduce的过程。
注:从以上步骤就可以发现,这种做法很明显可以提升join性能,但是要注意的是小表的key如果非常大的话,可能会出现OOM的情况,这时我们就需要考虑其他的连接方式了。
测试数据如下:
/semi_jon/a.txt:
- 1,三劫散仙,13575468248
- 2,凤舞九天,18965235874
- 3,忙忙碌碌,15986854789
- 4,少林寺方丈,15698745862
/semi_join/b.txt:
- 3,A,99,2013-03-05
- 1,B,89,2013-02-05
- 2,C,69,2013-03-09
- 3,D,56,2013-06-07
- 5,E,100,2013-09-09
- 6,H,200,2014-01-10
#需求就是对上面两个表做半连接。
实现代码如下:
- public class SemiJoin {
- // 定义输入路径
- private static String INPUT_PATH1 = "";
- private static String INPUT_PATH2 = "";
- // 定义输出路径
- private static String OUT_PATH = "";
- public static void main(String[] args) {
- try {
- // 创建配置信息
- Configuration conf = new Configuration();
- // 获取命令行的参数
- String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
- // 当参数违法时,中断程序
- if (otherArgs.length != 3) {
- System.err.println("Usage:Semi_join<in1> <in2> <out>");
- System.exit(1);
- }
- // 给路径赋值
- INPUT_PATH1 = otherArgs[0];
- INPUT_PATH2 = otherArgs[1];
- OUT_PATH = otherArgs[2];
- // 把小表添加到共享Cache里
- DistributedCache.addCacheFile(new URI(INPUT_PATH1), conf);
- // 创建文件系统
- FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf);
- // 如果输出目录存在,我们就删除
- if (fileSystem.exists(new Path(OUT_PATH))) {
- fileSystem.delete(new Path(OUT_PATH), true);
- }
- // 创建任务
- Job job = new Job(conf, SemiJoin.class.getName());
- // 设置成jar包
- job.setJarByClass(SemiJoin.class);
- //1.1 设置输入目录和设置输入数据格式化的类
- FileInputFormat.setInputPaths(job, INPUT_PATH2);
- job.setInputFormatClass(TextInputFormat.class);
- //1.2设置自定义Mapper类和设置map函数输出数据的key和value的类型
- job.setMapperClass(SemiJoinMapper.class);
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(CombineEntity.class);
- //1.3 设置分区和reduce数量(reduce的数量,和分区的数量对应,因为分区为一个,所以reduce的数量也是一个)
- job.setPartitionerClass(HashPartitioner.class);
- job.setNumReduceTasks(1);
- //1.4 排序
- //1.5 归约
- //2.1 Shuffle把数据从Map端拷贝到Reduce端。
- //2.2 指定Reducer类和输出key和value的类型
- job.setReducerClass(SemiJoinReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- //2.3 指定输出的路径和设置输出的格式化类
- FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
- job.setOutputFormatClass(TextOutputFormat.class);
- // 提交作业 退出
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- /**
- * 自定义Mapper函数
- *
- * @author 廖*民 time : 2015年1月21日下午8:40:43
- * @version
- */
- public static class SemiJoinMapper extends Mapper<LongWritable, Text, Text, CombineEntity> {
- // 创建相关对象
- private CombineEntity combine = new CombineEntity();
- private Text flag = new Text();
- private Text joinKey = new Text();
- private Text secondPart = new Text();
- // 存储小表的key
- private HashSet<String> joinKeySet = new HashSet<String>();
- @Override
- protected void setup(Mapper<LongWritable, Text, Text, CombineEntity>.Context context) throws IOException, InterruptedException {
- // 读取文件流
- BufferedReader br = null;
- String temp = "";
- // 获取DistributedCached里面的共享文件
- Path[] paths = DistributedCache.getLocalCacheFiles(context.getConfiguration());
- System.out.println("=================================>"+paths.length);
- // 遍历path数组
- for (Path path : paths) {
- if (path.getName().endsWith("a.txt")) {
- // 创建读取文件流
- br = new BufferedReader(new FileReader(path.toString()));
- // 读取数据
- while ((temp = br.readLine()) != null) {
- // 按","切割
- String[] splits = temp.split(",");
- // 将key加入小表中
- joinKeySet.add(splits[0]);
- }
- }
- }
- }
- protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, CombineEntity>.Context context) throws IOException,
- InterruptedException {
- // 获取文件输入路径
- String pathName = ((FileSplit) (context.getInputSplit())).getPath().toString();
- System.out.println("Map中获取的路径没有a.txt吧?"+pathName);
- if (pathName.endsWith("a.txt")) {
- String[] valuesTemps = value.toString().split(",");
- System.out.println("进入a.txt==================>a中的字符串:"+value.toString());
- // 在这里过滤必须要连接的字符
- if (joinKeySet.contains(valuesTemps[0])) {
- // 设置标志位
- flag.set("0");
- // 设置连接键
- joinKey.set(valuesTemps[0]);
- // 设置第二部分
- secondPart.set(valuesTemps[1] + "\t" + valuesTemps[1]);
- // 封装实体
- combine.setFlag(flag);
- combine.setJoinKey(joinKey);
- combine.setSecondPart(secondPart);
- // 写出去
- context.write(combine.getJoinKey(), combine);
- } else {
- System.out.println("a.txt里");
- System.out.println("小表中没有此记录");
- for (String v : valuesTemps) {
- System.out.println(v + " ");
- }
- return;
- }
- } else if (pathName.endsWith("b.txt")) {
- System.out.println("进入b.txt==================>b中的字符串:"+value.toString());
- // 切割
- String[] valueItems = value.toString().split(",");
- // 判断是否在集合中
- if (joinKeySet.contains(valueItems[0])) {
- // 设置标志位
- flag.set("1");
- // 设置连接键
- joinKey.set(valueItems[0]);
- // 设置第二部分数据,注意:不同文件的列数不一样
- secondPart.set(valueItems[1] + "\t" + valueItems[2] + "\t" + valueItems[3]);
- // 封装实体
- combine.setFlag(flag);
- combine.setJoinKey(joinKey);
- combine.setSecondPart(secondPart);
- // 写出去
- context.write(combine.getJoinKey(), combine);
- } else {
- System.out.println("b.txt里");
- System.out.println("小表中没有此记录");
- for (String v : valueItems) {
- System.out.println(v + " ");
- }
- return;
- }
- }
- }
- }
- /**
- * 自定义Reducer函数
- *
- * @author 廖*民 time : 2015年1月21日下午8:41:01
- * @version
- */
- public static class SemiJoinReducer extends Reducer<Text, CombineEntity, Text, Text> {
- // 存储一个分组中左表信息
- private List<Text> leftTable = new ArrayList<Text>();
- // 存储一个分组中右表数据
- private List<Text> rightTable = new ArrayList<Text>();
- private Text secondPart = null;
- private Text outPut = new Text();
- // 一个分组调用一次reduce()函数
- protected void reduce(Text key, Iterable<CombineEntity> values, Reducer<Text, CombineEntity, Text, Text>.Context context) throws IOException,
- InterruptedException {
- // 清空分组数据
- leftTable.clear();
- rightTable.clear();
- // 将不同文件的数据,分别放在不同的集合中;注意数据过大时,会出现OOM
- for (CombineEntity val : values) {
- this.secondPart = new Text(val.getSecondPart().toString());
- System.out.println("传到reduce中的secondPart部分:" + this.secondPart);
- System.out.println("难道A表中就没有数据:" + val.getFlag().toString().trim().equals("0"));
- // 左表
- if (val.getFlag().toString().trim().equals("0")) {
- leftTable.add(secondPart);
- } else if (val.getFlag().toString().trim().equals("1")) {
- rightTable.add(secondPart);
- }
- }
- for (Text val : leftTable){
- System.out.println("A 表中的数据为:" + val);
- }
- for (Text val : rightTable){
- System.out.println("B 表中的数据为:" + val);
- }
- // 做笛卡尔积输出我们想要的连接数据
- for (Text left : leftTable) {
- for (Text right : rightTable) {
- outPut.set(left + "\t" + right);
- // 将数据写出
- context.write(key, outPut);
- }
- }
- }
- }
- }
- /**
- * 自定义实体
- *
- * @author 廖*民 time : 2015年1月21日下午8:41:18
- * @version
- */
- class CombineEntity implements WritableComparable<CombineEntity> {
- // 连接key
- private Text joinKey;
- // 文件来源标志
- private Text flag;
- // 除了键外的其他部分的数据
- private Text secondPart;
- // 无参构造函数
- public CombineEntity() {
- this.joinKey = new Text();
- this.flag = new Text();
- this.secondPart = new Text();
- }
- // 有参构造函数
- public CombineEntity(Text joinKey, Text flag, Text secondPart) {
- this.joinKey = joinKey;
- this.flag = flag;
- this.secondPart = secondPart;
- }
- public Text getJoinKey() {
- return joinKey;
- }
- public void setJoinKey(Text joinKey) {
- this.joinKey = joinKey;
- }
- public Text getFlag() {
- return flag;
- }
- public void setFlag(Text flag) {
- this.flag = flag;
- }
- public Text getSecondPart() {
- return secondPart;
- }
- public void setSecondPart(Text secondPart) {
- this.secondPart = secondPart;
- }
- public void write(DataOutput out) throws IOException {
- this.joinKey.write(out);
- this.flag.write(out);
- this.secondPart.write(out);
- }
- public void readFields(DataInput in) throws IOException {
- this.joinKey.readFields(in);
- this.flag.readFields(in);
- this.secondPart.readFields(in);
- }
- public int compareTo(CombineEntity o) {
- return this.joinKey.compareTo(o.joinKey);
- }
- }
打成jar包,运行命令如下:
- hadoop jar join.jar /semi_join/a.txt /semi_join/* /out
注:a.txt是要加入到内存的表,/semi_join/*是要进入map()函数进行比对的目录,/out是输出目录。
程序运行的结果为:
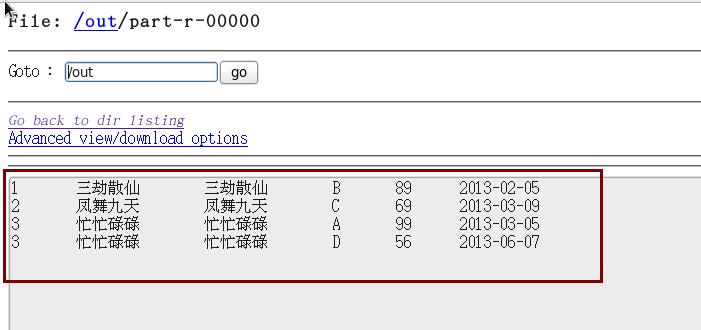
以上是关于MapReduce表连接之半连接SemiJoin的主要内容,如果未能解决你的问题,请参考以下文章