MapReduce过程详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce过程详解相关的知识,希望对你有一定的参考价值。
Hadoop越来越火,围绕Hadoop的子项目更是增长迅速,光Apache官网上列出来的就十几个,但是万变不离其宗,大部分项目都是基于Hadoop Common。
MapReduce更是核心中的核心。那么到底什么是MapReduce,它具体是怎么工作的呢?
关于它的原理,说简单也简单,随便画个图喷一下Map和Reduce两个阶段似乎就完了。但其实这里面还包含了很多的子阶段,尤其是Shuffle,很多资料里都把它称为MapReduce的“心脏”,和所谓“奇迹发生的地方”。真正能说清楚其中关系的人就没那么多了。可是了解这些流程对我们理解和掌握MapReduce并对其进行调优是非常有用的。
首先我们看一幅图,包含了从头到尾的整个过程,后面对所有步骤的解释都以此图作为参考(此图100%原创)
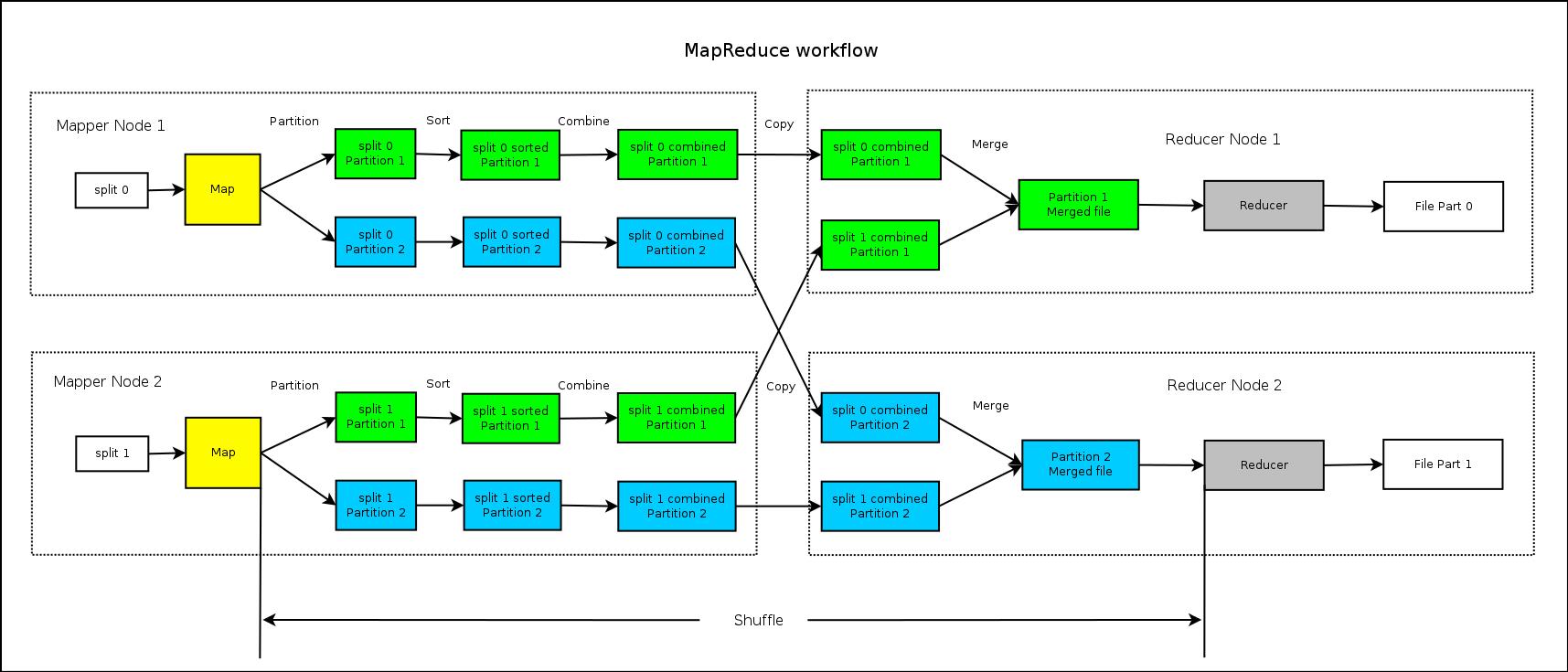
这张图简单来说,就是说在我们常见的Map和Reduce之间还有一系列的过程,其中包括partition、Sort、Combine、copy、merge等,而这些过程往往被统称为“Shuffle”也就是“混洗”,而Shuffle的目的就是对数据进行梳理,排序,以便科学的方式分发给每个Reducer,以便高效的进行计算和处理(难怪人家说这事奇迹发生的地方,原理这里面有这么多花花,能没奇迹嘛?)
如果您是Hadoop的大牛,看了这幅图可能马上就要跳出来了,不对!还有一个spill过程云云。。。
且慢,关于spill,我认为只是一个实现细节,其实就是MapReduce利用内存缓冲的方式提高效率,整个的过程和原理并没有受影响,所以在此忽略掉spill过程,以便更好了解。
光看原理图还是有点费解是吧?没错!我一直认为,没有例子的文章就是耍流氓,所以我们就用大家耳熟能详的WordCount作为例子,开始我们的讨论。
先创建两个文本文件,作为我们例子的输入:
file1 内容为:
- My name is Tony
- My company is pivotal
file2 内容为:
- My name is Lisa
- My company is EMC
第一步:对输入分片进行map()处理
首先我们的输入就是两个文件,默认情况下是两个split,对应前面图中的split0,split1。两个split默认会分给两个Mapper来处理,WordCount例子相当地暴力,这一步里面就是把文件内容分解为单词和1,其中的单词就是我们的key,后面的数字就是对应的值,也就是value【在此假设各位都对WordCount程序烂熟于心】。
那么对应两个Mapper的输出就是:
split0被处理后的数据为:
- My 1
- name 1
- is 1
- Tony 1
- My 1
- company 1
- is 1
- Pivotal 1
split1被处理后的数据为:
- My 1
- name 1
- is 1
- Lisa 1
- My 1
- company 1
- is 1
- EMC 1
第二步:对map()的输出结果进行Partition
partition是什么?partition就是分区。
为什么要分区?因为有时候会有多个Reducer,partition就是提前对输入进行处理,根据将来的Reducer进行分区,到时候Reducer处理的时候,只需要处理分给自己的数据就可以了。
如何分区?主要的分区方法就是按照key不同,把数据分开,其中很重要的一点就是要保证key的唯一性,因为将来做Reduce的时候很可能是在不同的节点上做的,如果一个key同时存在两个节点上,Reduce的结果就会出问题,所以很常见的partition方法就是哈希。
结合我们的例子,我们这里假设有两个Reducer,前面两个Split做完Partition的结果就会如下:
split0的数据经过map()后再进行分区
partition 1:
- company 1
- is 1
- is 1
Partition 2:
- My 1
- My 1
- name 1
- Pivotal 1
- Tony 1
注:按Key进行hash并且对reducer数量(这里设置为2)取模,所以结果只能是两个。
split1的数据经过map()后再进行分区(同split0):
partition 1:
- company 1
- is 1
- is 1
- EMC 1
Partition 2:
- My 1
- My 1
- name 1
- Lisa 1
注:其中partition1是给Reducer1处理的,partition2是给Reducer2处理的。这里我们可以看到,partition只是把所有的条目按照key分了一个区,没有其他任何处理,每个区里面的key都不会出现在另外一个区里面。
第三步:sort
sort就是排序咯,其实这个过程在我看来并不是必须的,完全可以交给客户端自己的程序来处理。那为什么还要排序呢?可能是写MapReduce的大牛们想,“大部分reduce程序应该都希望输入的是已经按key排序号的数据,如果是这样,那么我们就干脆顺手帮你做掉啦!”
那么我们假设对前面的数据再进行排序,结果如下:
split0 的partition 1中的数据排序后如下:
- company 1
- is 1
- is 1
split0的partition 2中的数据排序后如下:
- My 1
- My 1
- name 1
- Pivotal 1
- Tony 1
split1的partition 1中的数据排序后如下:
- company 1
- EMC 1
- is 1
- is 1
split1的partition 2中的数据排序后如下:
- Lisa 1
- My 1
- My 1
- name 1
注:这里可以看到,每个partition里面的条目都按照key的顺序做了排序。
第四步:Combine
什么是Combine呢?combine其实可以理解为一个mini Reduce过程,它发生在前面Map的输出结果之后,目的就是在结果送到Reducer之前先对其进行一次计算,以减少文件的大小,方便后面的传输。但这一步不是必须的。
按照前面的输出,执行Combine:
split0的partition 1的数据为:
- company 1
- is 2
split0的partition 2的数据为:
- My 2
- name 1
- Pivotal 1
- Tony 1
split1的partition1 的数据为:
- Partition 1:
- company 1
- EMC 1
- is 2
split1的partition 2的数据为:
- Lisa 1
- My 2
- name 1
注:针对前面的输出结果,我们已经局部地统计了is和My的出现频率,减少了输出文件的大小。
第五步:copy
下面就要准备把输出结果传送给Reducer了。这个阶段被称为Copy,但事实上我认为叫它Download更为合适,因为实现的时候,是通过http的方式,由Reducer节点向各个Mapper节点下载属于自己分区的数据。
那么根据前面的partition,下载完的结果如下:
Reducer 节点1的共包含两个文件(split0的partition1和split1的partition1):
- Partition 1:
- company 1
- is 2
- Partition 1:
- company 1
- EMC 1
- is 2
Reducer 节点2也是两个文件(split0的partition1和split1的partition2):
- Partition 2:
- My 2
- name 1
- Pivotal 1
- Tony 1
- Partition 2:
- Lisa 1
- My 2
- name 1
注:通过Copy,相同Partition的数据落到了同一个节点上。
第六步:Merge
如上一步所示,此时Reducer得到的文件是从不同的Mapper那里下载到的,需要对他们进行合并为一个文件,所以下面这一步就是Merge,结果如下:
Reducer 节点1的数据如下:
- company 1
- company 1
- EMC 1
- is 2
- is 2
Reducer节点2的数据如下:
- Lisa 1
- My 2
- My 2
- name 1
- name 1
- Pivotal 1
- Tony 1
注:Map端也有merge的过程,发生在环形缓冲区部分。
第七步:reduce处理
终于可以进行最后的Reduce啦,这步相当简单咯,根据每个文件中的内容最后做一次统计,结果如下:
Reducer节点1的数据:
- company 2
- EMC 1
- is 4
Reducer节点2的数据:
- Lisa 1
- My 4
- name 2
- Pivotal 1
- Tony 1
至此大功告成!我们成功统计出两个文件里面每个单词的数目,同时把他们存入到两个输出文件中,这两个输出文件也就是传说中的part-r-00000和part-r-00001,看看两个文件的内容,再回头想想最开始的Partition,应该是清楚了其中的奥秘吧。
如果你在你自己的环境中运行的WordCount只有part-r-00000一个文件的话,那应该是因为你使用的是默认设置,默认一个Job只有一个Reducer。
如果你想设置两个,你可以:
1.在源代码中加入 job.setNumReduceTasks(2),设置这个Job的Reducer为两个。
或者
2.在mapred-site.xml中设置下面参数并重启服务
- <property>
- <name>mapred.reduce.tasks</name>
- <value>2</value>
- </property>
如果在配置文件中设置,整个集群都会默认使用两个Reducer了。
结束语:
本文大致描述了一下MapReduce的整个过程以及每个阶段所做的事情,并没有涉及具体的Job,resource的管理和控制,因为那个是第一代MapReduce框架和Yarn框架的主要区别。而两代框架中上述MapReduce的原理是差不多的。
注:文章来自 这里。另外这篇文章并没有说清楚Map端环形缓冲区spill的过程,详情请参考:MapReduce Shuffle详解
以上是关于MapReduce过程详解的主要内容,如果未能解决你的问题,请参考以下文章