Hadoop中SecondaryNameNode工作机制
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop中SecondaryNameNode工作机制相关的知识,希望对你有一定的参考价值。
首先来看一下HDFS的结构,如下图:
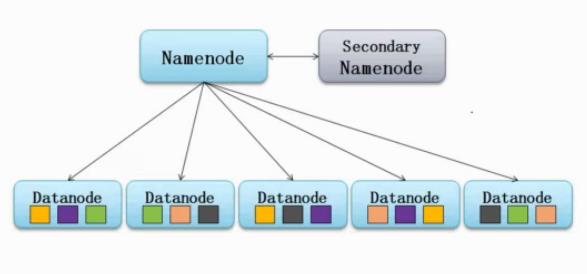
如上图,在HDFS架构中,NameNode是职责是管理元数据信息,DataNode的职责是负责数据存储,那么SecondaryNameNode的作用是什么呢?
其实SecondaryNameNode是hadoop1.x中HDFS HA的一个解决方案,下面我们来看一下SecondaryNameNode工作的流程,如下图:
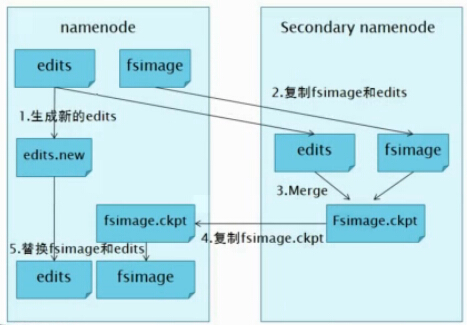
1.NameNode管理着元数据信息,元数据信息会定期的刷到磁盘中,其中的两个文件是edits即操作日志文件和fsimage即元数据镜像文件,新的操作日志不会立即与fsimage进行合并,也不会刷到NameNode的内存中,而是会先写到edits中(因为合并需要消耗大量的资源)。当edits文件的大小达到一个临界值(默认是64MB)或者间隔一段时间(默认是1小时)的时候checkpoint会触发SecondaryNameNode进行工作。
2.当触发一个checkpoint操作时,NameNode会生成一个新的edits即上图中的edits.new文件,同时SecondaryNameNode会将edits文件和fsimage复制到本地。
3.SecondaryNameNode将本地的fsimage文件加载到内存中,然后再与edits文件进行合并生成一个新的fsimage文件即上图中的Fsimage.ckpt文件。
4.SecondaryNameNode将新生成的Fsimage.ckpt文件复制到NameNode节点。
5.在NameNode结点的edits.new文件和Fsimage.ckpt文件会替换掉原来的edits文件和fsimage文件,至此,刚好是一个轮回即在NameNode中又是edits和fsimage文件了。
6.等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
注:checkpoint触发的条件可以在core-site.xml文件中进行配置,如下:
- <property>
- <name>fs.checkpoint.period</name>
- <value>3600</value>
- <description>The number of seconds between two periodic checkpoints.
- </description>
- </property>
- <property>
- <name>fs.checkpoint.size</name>
- <value>67108864</value>
- <description>The size of the current edit log (in bytes) that triggers
- a periodic checkpoint even if the fs.checkpoint.period hasn‘t expired.
- </description>
- </property>
以上是关于Hadoop中SecondaryNameNode工作机制的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop之HDFS(NameNode和SecondaryNameNode)(面试开发重点)
解决 Hadoop3.1.3 SecondaryNamenode 页面不能显示完整信息
解决 Hadoop3.1.3 SecondaryNamenode 页面不能显示完整信息
hadoop2.X如何将namenode与SecondaryNameNode分开配置