Java_JDK_HashMap
Posted 江湖小妞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java_JDK_HashMap相关的知识,希望对你有一定的参考价值。
(二)HashMap
需要注意的无非几点:
- 是什么结构,如何存储的?
- 如何加入元素?既然是hashMap,那么是如何计算hashcode的呢?遇到冲突又是如何解决的呢?
- 如何删除元素?
- 当容量不够时是如何扩容的?
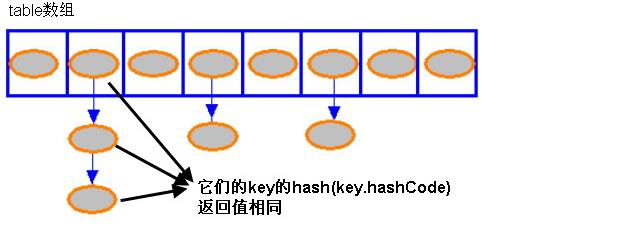
1. 总体的存储结构为一个Node类型的数组:transient Node<K,V>[] table;
其中,Node节点结构为:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
可以看到,Node节点中有next指针,说明数组内部是一个指针,指向下一个元素。
故整个HashMap的存储结构如下图所示:
2.put()方法:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true); //将具体的实现封装在下面的函数中
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don\'t change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) //如果是空表
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) //如果(n - 1) & hash处还没有元素(不会产生冲突),则直接放入即可
tab[i] = newNode(hash, key, value, null);
else { //否则,产生了冲突,且p记录了应该放入的位置
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) //如果确实产生了冲突
e = p; //用e记录冲突位置
else if (p instanceof TreeNode) //p是TreeNode ? 不是太理解,先放这里吧。。
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { //如果就放了一个元素,即链表位置为空
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; //是否可以直接替换
afterNodeAccess(e);
return oldValue;
}
}
++modCount; //修改次数加一
if (++size > threshold)
resize(); //超出了限定容量,则扩容
afterNodeInsertion(evict);
return null;
}
可以看到,其中有很多细节处没有吃透,先有个大概的认识,与后面的分析融汇贯通。
3. resize()函数:扩容
下面我们来分析一下这个长长的扩容函数:
/**
* Initializes or doubles table size. If null, allocates in 初始化或者对原来容量扩大两倍
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { //原来HashMap不空
if (oldCap >= MAXIMUM_CAPACITY) { //如果原来map的容量就很大,则直接设置到Integer的最大值
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY) //如果扩大一倍的新容量仍小于最大容量 && 原始容量大于默认值(16)
newThr = oldThr << 1; // double threshold,则让容量扩大一倍
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// zero initial threshold signifies using defaults,若oldCap = 0 && oldThr = 0,则用默认值对map初始化
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {//如果上面的初始化没有成功
float ft = (float)newCap * loadFactor; //loadfactor为负载因子,初始为0.75
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE); //初始化为0.75倍
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null; //置为null,方便GC进行回收
if (e.next == null) //如果j处只有这一个元素(链表长度为1)
newTab[e.hash & (newCap - 1)] = e;//将e放入新的位置,为何这样计算呢?
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order 如果j处是一个链表,则按照原来的次序进行拷贝
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
4. delete函数
/** * Implements Map.remove and related methods * * @param hash hash for key * @param key the key * @param value the value to match if matchValue, else ignored * @param matchValue if true only remove if value is equal * @param movable if false do not move other nodes while removing * @return the node, or null if none */ final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) { Node<K,V>[] tab; Node<K,V> p; int n, index; if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) { //如果map不为空 Node<K,V> node = null, e; K k; V v; //首先寻找要删除的元素,用node记录 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) node = p; //p/node 就是要删除的元素 else if ((e = p.next) != null) { if (p instanceof TreeNode) node = ((TreeNode<K,V>)p).getTreeNode(hash, key); else { //该位置有很多元素,则找到要删除的那一个 do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { node = e; break; } p = e; } while ((e = e.next) != null); } } //找到用node记录的要删除的元素之后,进行删除操作 if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) { if (node instanceof TreeNode) ((TreeNode<K,V>)node).removeTreeNode(this, tab, movable); else if (node == p) //如果p是要删除的节点,直接指向下一个元素或指向null tab[index] = node.next; else //如果要删除的node在p的一个链表中,则让next指针指向node.next即可 p.next = node.next; ++modCount; //修改次数+1 --size; //size - 1 afterNodeRemoval(node); return node; } } return null; }
5. hashCode
使用了Object类中的hashCode方法,每个对象都会有自己的hashCode, 同时,jdk有自己的根据key值计算hash的方法:
/** * Computes key.hashCode() and spreads (XORs) higher bits of hash * to lower. Because the table uses power-of-two masking, sets of * hashes that vary only in bits above the current mask will * always collide. (Among known examples are sets of Float keys * holding consecutive whole numbers in small tables.) So we * apply a transform that spreads the impact of higher bits * downward. There is a tradeoff between speed, utility, and * quality of bit-spreading. Because many common sets of hashes * are already reasonably distributed (so don\'t benefit from * spreading), and because we use trees to handle large sets of * collisions in bins, we just XOR some shifted bits in the * cheapest possible way to reduce systematic lossage, as well as * to incorporate impact of the highest bits that would otherwise * never be used in index calculations because of table bounds. */ static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
以上是关于Java_JDK_HashMap的主要内容,如果未能解决你的问题,请参考以下文章