MapReduce去重
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce去重相关的知识,希望对你有一定的参考价值。
一:背景
很多数据源中的数据都是含有大量重复的,为此我们需要将重复的数据去掉,这也称为数据的清洗,MapReduce从Map端到Reduce端的Shuffle过程天生就有去重的功能,但是这是对输出的Key作为参照进行去重的。所以我们可以将Map端读入Value作为Key输出,就可以很方便的实现去重了。
二:技术实现
#需求 有两个文件file0和file1。将两个文件中的内容合并去重。
#file0的内容如下:
- 1
- 1
- 2
- 2
- 3
- 3
- 4
- 4
- 5
- 5
- 6
- 6
- 7
- 8
- 9
file1的内容如下:
- 1
- 9
- 9
- 8
- 8
- 7
- 7
- 6
- 6
- 5
- 5
- 4
- 4
- 2
- 1
- 2
代码实现:
- public class DistinctTest {
- // 定义输入路径
- private static final String INPUT_PATH = "hdfs://liaozhongmin:9000/distinct_file/*";
- // 定义输出路径
- private static final String OUT_PATH = "hdfs://liaozhongmin:9000/out";
- public static void main(String[] args) {
- try {
- // 创建配置信息
- Configuration conf = new Configuration();
- // 创建文件系统
- FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf);
- // 如果输出目录存在,我们就删除
- if (fileSystem.exists(new Path(OUT_PATH))) {
- fileSystem.delete(new Path(OUT_PATH), true);
- }
- // 创建任务
- Job job = new Job(conf, DistinctTest.class.getName());
- //1.1 设置输入目录和设置输入数据格式化的类
- FileInputFormat.setInputPaths(job, INPUT_PATH);
- job.setInputFormatClass(TextInputFormat.class);
- //1.2 设置自定义Mapper类和设置map函数输出数据的key和value的类型
- job.setMapperClass(DistinctMapper.class);
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(Text.class);
- //1.3 设置分区和reduce数量(reduce的数量,和分区的数量对应,因为分区为一个,所以reduce的数量也是一个)
- job.setPartitionerClass(HashPartitioner.class);
- job.setNumReduceTasks(1);
- //1.4 排序
- //1.5 归约
- job.setCombinerClass(DistinctReducer.class);
- //2.1 Shuffle把数据从Map端拷贝到Reduce端。
- //2.2 指定Reducer类和输出key和value的类型
- job.setReducerClass(DistinctReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- //2.3 指定输出的路径和设置输出的格式化类
- FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
- job.setOutputFormatClass(TextOutputFormat.class);
- // 提交作业 退出
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- public static class DistinctMapper extends Mapper<LongWritable, Text, Text, Text>{
- //定义写出去的key和value
- private Text outKey = new Text();
- private Text outValue = new Text("");
- @Override
- protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
- //把输入的key作为value输出(因为)
- outKey = value;
- //把结果写出去
- context.write(outKey, outValue);
- }
- }
- public static class DistinctReducer extends Reducer<Text, Text, Text, Text>{
- @Override
- protected void reduce(Text key, Iterable<Text> value, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
- //直接把key写出去
- context.write(key, new Text(""));
- }
- }
- }
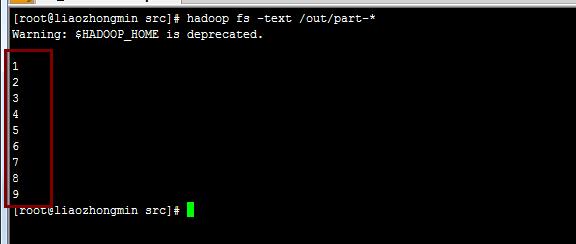
程序运行的结果:
以上是关于MapReduce去重的主要内容,如果未能解决你的问题,请参考以下文章