爬虫实例——爬取1元夺宝用户头像(借助谷歌浏览器开发者工具)
Posted 昨、夜星辰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫实例——爬取1元夺宝用户头像(借助谷歌浏览器开发者工具)相关的知识,希望对你有一定的参考价值。
环境
操作系统:Windows 7
Python版本:2.7.9
过程
- 打开谷歌浏览器;
- 打开1元夺宝商品列表页面;
- 随便点击一个商品,按F12调用开发者工具,选择“Network”标签,筛选“XHR”,再单击页面上的“夺宝参与记录”;
- 观察开发者工具,找到返回JSON格式数据的URL,如下图:
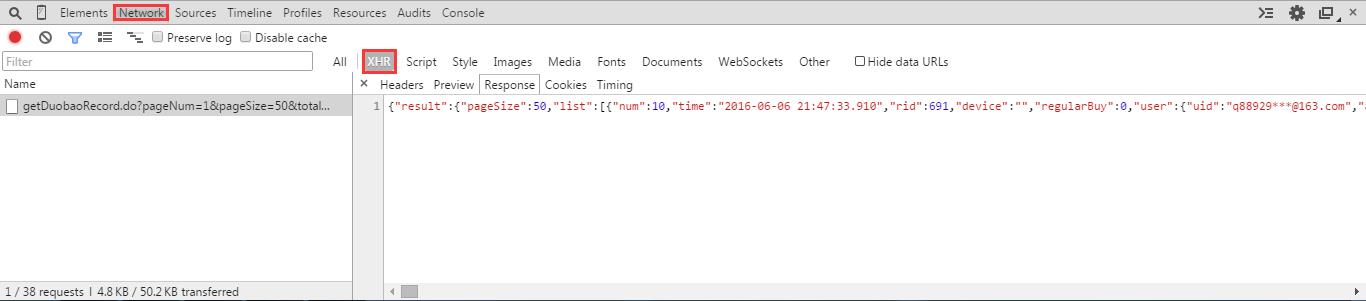
- 从上图的URL返回的JSON格式数据我们可以得知参与夺宝的用户数(totalCnt),每个用户的头像链接前缀(avatarPrefix);
- 随便点击一个用户,从开发者工具中可以得知用户头像的URL是由头像链接前缀和“160.jpeg”组成的。
代码
# -*- coding: utf-8 -*- import sys reload(sys) sys.setdefaultencoding(\'utf-8\') \'\'\' 作者:昨夜星辰 \'\'\' import re import os import requests from bs4 import BeautifulSoup # 创建一个用于存放头像的文件夹 folder = u\'头像\' os.mkdir(folder) # 用于存放用户的cid cidList = [] # 用于头像计数 picCnt = 1 url = \'http://1.163.com/list.html\' bs = BeautifulSoup(requests.get(url).text, \'lxml\') for div in bs(\'div\', \'w-goods w-goods-l w-goods-ing\'): gid = div[\'data-gid\'] period = div[\'data-period\'] url = \'http://1.163.com/record/getDuobaoRecord.do?pageNum=1&pageSize=50&totalCnt=0&gid=%s&period=%s\' % (gid, period) json = requests.get(url).json() totalCnt = json[\'result\'][\'totalCnt\'] for pageNum in range(1, totalCnt / 50 + 1): url = \'http://1.163.com/record/getDuobaoRecord.do?pageNum=%d&pageSize=50&totalCnt=%d&gid=%s&period=%s\' % (pageNum, totalCnt, gid, period) json = requests.get(url).json() for _list in json[\'result\'][\'list\']: cid = _list[\'user\'][\'cid\'] if cid in cidList: continue cidList.append(cid) avatarPrefix = _list[\'user\'][\'avatarPrefix\'] if avatarPrefix: url = avatarPrefix + \'160.jpeg\' filename = folder + \'\\\\\' + re.search(r\'.*/(.*)\', url).group(1) print u\'正在保存第%d个头像...\' % picCnt picCnt += 1 with open(filename, \'wb\') as f: f.write(requests.get(url).content)
以上是关于爬虫实例——爬取1元夺宝用户头像(借助谷歌浏览器开发者工具)的主要内容,如果未能解决你的问题,请参考以下文章