python模块详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python模块详解相关的知识,希望对你有一定的参考价值。
Python的模块在其它语言中通常称为库或类库,也就是lib。它是编程语言的第三级封装,第四级则是包,也就是模块的打包组合,而前两级分别是函数和类。封装的好处,自然不用多言,高内聚,松耦合,减少代码重复。同时,模块也是“轮子”的代表,大多数是前人已经实现并测试好的高效代码组合,它的存在使得我们不必重复“造轮子”,可以使用拿来主义。但是,个人认为一个合格的程序员,虽然不会去重复造轮子,但必须要具备造轮子的能力,至少你要看得懂他人造的轮子。
python模块的种类
在python中,通常是这样的,许多个方法和属性组成了类,许多个类组成了.py文件,许多个.py文件组成了模块。模块一般分为三种:
- 自定义模块
- 内置模块
- 第三方模块(开源模块)
自定义模块:你自己写的.py文件,通过import关键字,在另外的.py中文件被调用,那么它就成为一个自定义模块。
内置模块:python官方提供的一些常用的经典的模块,比如os、sys、time、logging等等,他们很成熟,效率很高,使用广泛。
第三方模块:非python官方提供的模块,例如django、requests。python的流行和其具有较多第三方开源模块是分不开的,这是一个良性的生态圈。
Python模块的导入
在python中,模块的导入方式通常有一下四种:
import module from module.xx.xx import xx from module.xx.xx import xx as rename from module.xx.xx import *
导入一个模块,也就是导入一个.py文件,解释器将会解释该文件;而导入一个包,则会导入该包下的__init__.py文件,解释器将解释这个文件。这里就涉及到了一个包的概念,通常我们会将一些处理某一大类问题的模块放在同一个文件夹下,便于管理和使用,文件夹下可能还有子文件夹,那么如何让解释器搜素到正确的模块呢?python设计了__init__.py这么一个文件(这个文件可以是空的,只要文件名一模一样就可以),它告诉解释器,当前它所属的文件夹内的所有文件都是模块。
以上四种方法各有各的适用场合:
1. 对于内置模块,一般使用第一种就比较好了,例如import os,sys,datetime
2.而对于需要经常调用某个模块内的某个类或函数时,使用第二种就比较合适,可以一定程度减少代码输入,例如:
首先,我们建立了一个模块do_something如下:
def print_welcome():
print("welcome to login!")
然后,我在另一个文件里要大量调用该print_welcome函数。当使用import do_something时,我们是这样调用的:
import do_something do_something.print_welcome() ...... do_something.print_welcome() ...... do_something.print_welcome()
而,如果使用from do_something import print_welcome的话,使用更加简洁方便,我们是这样调用的:
from do_something import print_welcome print_welcome() ...... print_welcome() ...... print_welcome()
3. 当导入的许多模块里有出现相同名称的类或者函数等情况时,from xxx import xxx as xxx这种导入方式就比较好用了,它实际上是给模块取个别名。例如:
在模块module_1中:
def func():
print("this is module_1 !")
在模块module_2中:
def func():
print("this is module_2 !")
在别的文件中,我们可以这样调用,就不会引起冲突了:
from module_1 import func as a from module_2 import func as b a() b()
4. 至于from xxx import *的方法,我们不太提倡。
Python模块的路径
python的模块作为一个独立的文件,在文件系统中必然有其保存路径。我们在导入模块时,解释器不可能针对整个文件系统进行搜索,它必然是维护了一个指定的搜索路径集合,我们只有将python的模块存放在这些路径中才可以被顺利导入。那么,这个路径集合存放在哪里呢?在sys这个模块的path里,可以通过下面的方式查看:
import sys
for i in sys.path:
print(i)
结果:
F:\\Python\\pycharm\\s13
C:\\Python35\\python35.zip
C:\\Python35\\DLLs
C:\\Python35\\lib
C:\\Python35
C:\\Python35\\lib\\site-packages
它的顺序是这样的,先是当前文件的存储目录,然后是python的安装目录,再是python目录里的site-packages,其实说白了就是”自定义”——“官方”——“第三方”目录。同时,由于存在多个目录,因此在自定义模块的时候,对模块的命名一定要注意,不要和官方标准模块和一些比较有名的第三方模块重名,一有不慎,就容易出现模块导入错误的情况发生。(注:site-packages在不同的操作系统里可能名称不一样)
如果sys.path路径列表没有你想要的路径,可以通过 sys.path.append(‘路径‘) 添加。例如:
import sys import os new_path = os.path.abspath(‘../‘) sys.path.append(new_path)
内置模块
一、序列化json和pickle
json和pickle模块主要用于对python的数据进行序列化,保存为字符串的格式。两者的的使用方法和几乎一模一样,都是主要使用下面四个方法:
dump() dumps() load() loads()
import json
s = ‘{"k1":"v1","k2":123}‘ # 类似字典结构的字符串必须以单引号引起来,而大括号里的则需使用双引号
dic = json.loads(s) # loads方法是将json格式字符串转换成python的数据结构
print(dic)
print(type(dic))
运行结果:
{‘k1‘: ‘v1‘, ‘k2‘: 123}
<class ‘dict‘>
import json
dic = {"k1":"v1","k2":123}
s = json.dumps(dic)
print(s)
print(type(s))
运行结果:
{"k1": "v1", "k2": 123}
<class ‘str‘>
与loads和dumps不同的是load和dump方法是将json格式的字符串在文件内进行读写
import json
dic = {"k1":"v1","k2":123}
s = json.dump(dic,open(‘file‘,‘w‘))
运行结果:
在同级目录下生成file文件,并保存了{"k1":"v1","k2":123}字符串
import json
s = json.load(open(‘file‘))
print(s)
print(type(s))
运行结果:
{‘k1‘: ‘v1‘, ‘k2‘: 123}
<class ‘dict‘>
pickle与json基本一样,但是不同的是,它的序列化字符串是不可认读的,不如json的来得直观。
import pickle
dic = {"k1":"v1","k2":123}
s = pickle.dumps(dic)
print(s)
print(type(s))
运行结果:
b‘\\x80\\x03}q\\x00(X\\x02\\x00\\x00\\x00k1q\\x01X\\x02\\x00\\x00\\x00v1q\\x02X\\x02\\x00\\x00\\x00k2q\\x03K{u.‘
<class ‘bytes‘>
二、time及datetime
时间模块是每个程序员必然会用到的。在python中,time和datetime模块为我们提供了大量的时间处理方法。其中的,time.time(),time.sleep(),time.localtime()非常常用。
time提供的功能更加接近于操作系统层面的,大多数函数是调用了所在平台C library的同名函数,并且围绕着 Unix Timestamp 进行,其所能表述的日期范围被限定在 1970 - 2038 之间,如果需要处理范围之外的日期,使用datetime模块会更好。
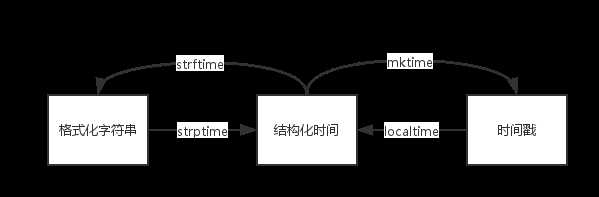
time模块主要包括三种类型时间:struct_time,timestamp和string_time。理解了这三种类型的话,对于time模块里各种方法就会有融汇贯通的感觉。
- 时间戳(timestamp) 1970年1月1日之后的秒 即:time.time()
- 格式化的字符串(string_time) 2016-06-11 12:0, 即:time.strftime(‘%Y-%m-%d‘)
- 结构化时间(struct_time) 包含了:年、日、星期等... 即:time.localtime()
三者之间的关系如下图:
下面是time模块的常用方法介绍:
import time
# time.sleep(1) #让程序睡眠指定秒数,可以是浮点数
print(time.time()) #返回当前系统时间戳
print(time.ctime()) #输出当前系统时间的字符串格式,它可以接受时间戳格式的参数
print(time.ctime(time.time()-86640)) #将时间戳转为字符串格式
print(time.asctime(time.localtime()))#将格式化时间转为字符串格式
print(time.gmtime(time.time()-86640)) #将时间戳转换成struct_time格式,返回的是gmt时间,与北京时间差8小时
print(time.localtime(time.time()-86640)) #将时间戳转换成struct_time格式,返回的是本地时间
print(time.mktime(time.localtime())) #与time.localtime()功能相反,将struct_time格式转回成时间戳格式
print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将struct_time格式转成指定的字符串格式
print(time.strptime("2016-01-28","%Y-%m-%d") ) #将字符串格式转换成struct_time格式
运行结果:
1465194377.782088
Mon Jun 6 14:26:17 2016
Sun Jun 5 14:22:17 2016
Mon Jun 6 14:26:17 2016
time.struct_time(tm_year=2016, tm_mon=6, tm_mday=5, tm_hour=6, tm_min=22, tm_sec=17, tm_wday=6, tm_yday=157, tm_isdst=0)
time.struct_time(tm_year=2016, tm_mon=6, tm_mday=5, tm_hour=14, tm_min=22, tm_sec=17, tm_wday=6, tm_yday=157, tm_isdst=0)
1465194377.0
2016-06-06 06:26:17
time.struct_time(tm_year=2016, tm_mon=1, tm_mday=28, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=28, tm_isdst=-1)
对于时间戳,通常用于算时间的差值,典型的用法是测试程序运行时间,例如:
import time
def func():
pass
t1 = time.time()
func()
t2 = time.time()
result = float(t2) - float(t1)
print(result)
对于格式化字符串:"%Y-%m-%d %H:%M:%S",其中每一个字母所代表的意思可以查看官方文档,这里不一一列举。
而对于一个结构化的时间对象,它的各项属性意义如下:
| 属性 | 意义 |
| tm_year | 年 |
| tm_mon | 月 |
| tm_mday | 日 |
| tm_hour | 小时 |
| tm_min | 分钟 |
| tm_sec | 秒 |
| tm_wday | 星期几,以0开始 |
| tm_yday | 当日在当年的天数 |
| tm_isdst | 是否夏令时,默认-1,表示自动判断 |
可以通过对象调用其各项属性,例如:
import time
s = time.localtime()
print("tm_year: ",s.tm_year)
运行结果:
tm_year: 2016
datetime
datetime 可以理解为基于 time 进行的封装,它提供了更多实用的函数。在datetime 模块中包含了几个类,具体如下:
- timedelta # 主要用于计算时间跨度
- tzinfo # 时区相关
- time # 只关注时间
- date # 只关注日期
- datetime # 同时有时间和日期
在实际实用中,用得比较多的是 datetime.datetime 和 datetime.timedelta。使用datetime.datetime.now()方法可以获得当前时刻的一个datetime.datetime 类的实例,该实例主要有以下属性及常用方法:
- datetime.year
- datetime.month
- datetime.day
- datetime.hour
- datetime.minute
- datetime.second
- datetime.microsecond
- datetime.tzinfo
import datetime ti = datetime.datetime.now() print(ti) print(type(ti)) print(ti.year) print(ti.month) print(ti.day) 运行结果: 2016-06-06 14:36:00.763951 <class ‘datetime.datetime‘> 2016 6 6 0
除了实例化对象后,datetime模块本身还提供了很多有用的方法,例如:
import time,datetime
print(datetime.date.today()) #输出格式 2016-06-06
print(datetime.date.fromtimestamp(time.time()-864400) ) #将时间戳转成日期格式
current_time = datetime.datetime.now() #实例化当前时间
print(current_time) #输出2016-01-26 19:04:30.335935
print(current_time.timetuple()) #返回struct_time格式
#datetime.replace([year[, month[, day[, hour[, minute[, second[, microsecond[, tzinfo]]]]]]]])
print(current_time.replace(2016,7,7)) #输出2016-07-07 14:06:24.074900,返回当前时间,但指定的值将被替换
str_to_date = datetime.datetime.strptime("21/11/06 16:30", "%d/%m/%y %H:%M") #将字符串转换成日期格式
new_date = datetime.datetime.now() + datetime.timedelta(days=10) #比现在加10天
new_date = datetime.datetime.now() + datetime.timedelta(days=-10) #比现在减10天
new_date = datetime.datetime.now() + datetime.timedelta(hours=-10) #比现在减10小时
new_date = datetime.datetime.now() + datetime.timedelta(seconds=120) #比现在+120s
print(new_date)
运行结果:
2016-06-06
2016-05-27
2016-06-06 14:42:21.503262
time.struct_time(tm_year=2016, tm_mon=6, tm_mday=6, tm_hour=14, tm_min=42, tm_sec=21, tm_wday=0, tm_yday=158, tm_isdst=-1)
2016-07-07 14:42:21.503262
2016-06-06 14:44:21.523263
其实,两个 datetime 对象直接相减就能获得一个 timedelta 对象。另外推荐,如果有需要计算工作日的需求,可以使用 business_calendar这个模块。
三、logging日志模块
日志是每个程序都应该具备的一项功能,它能帮你调试代码、查找问题、警告通知等等。Python内置了一个名叫logging的日志模块,提供了标准的日志接口,可以通过它存储各种格式的日志,logging的日志可以分为 debug, info, warning, error and critical五个级别。在logging内部,每个级别由一个数字表示如下:
CRITICAL = 50 ERROR = 40 WARNING = 30 INFO = 20 DEBUG = 10 如果只是简单的将日志输入到屏幕,可以这么做:import logging
logging.warning("user [jack] attempted wrong password more than 3 times")
logging.critical("server is down")
#输出
WARNING:root:user [jack] attempted wrong password more than 3 times
CRITICAL:root:server is down
如果要将日志写入某个文件,那么可以这么做:
import logging
logging.basicConfig(filename=‘log.log‘, #这一行指定日志文件
format=‘%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s‘,## 这一行控制每条日志的格式
datefmt=‘%Y-%m-%d %H:%M:%S %p‘, # 这一行控制时间格式
level=10) # 系统只会将高于level的信息写入文件
logging.debug(‘debug‘)
logging.info(‘info‘)
logging.warning(‘warning‘)
logging.error(‘error‘)
logging.critical(‘critical‘)
logging.log(10,‘log‘)
对于输出的格式,如上面例子中的asctime/name/levelname等,还有其它属性如下图:

而如果想要同时把日志打印在屏幕和保存在文件日志里,则必须对logging模块有更深的了解。
首先,我们需要了解logging模块的四个部分:loggers, handlers, filters, formatters。
loggers:提供让程序代码直接使用的接口
handlers:将logger产生的日志发送到希望的目的地
filter:用于过滤日志,将符合条件的日志输出
formatters:在输出前格式化日志,使之符合你想要的格式。
下面我们根据一个具体的例子来看:
import logging
# 创建logger
logger = logging.getLogger(‘jack‘) # 使用getLogger方法,并指定用户名
logger.setLevel(logging.DEBUG) # 设置全局的日志记录等级为DEBUG
# 创建要发送到屏幕的handler,并设置其局部日志等级为DEBUG
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# 创建要发送到日志文件的handler,并设置其局部日志等级为WARNING
fh = logging.FileHandler("access.log") # 设置日志文件名为access.log
fh.setLevel(logging.WARNING)
# 创建一种formatter格式,你可以根据需要创建任意种
formatter = logging.Formatter(‘%(asctime)s - %(name)s - %(levelname)s - %(message)s‘)
# 为先前创建好的Handlers添加formatter格式
ch.setFormatter(formatter)
fh.setFormatter(formatter)
# 为一开始创建的logger添加Handlers,也就是处理逻辑,有几个Handlers就添加几次
logger.addHandler(ch)
logger.addHandler(fh)
# 下面是应用程序的代码
logger.debug(‘debug message‘)
logger.info(‘info message‘)
logger.warn(‘warn message‘)
logger.error(‘error message‘)
logger.critical(‘critical message‘)
屏幕显示:
2016-06-06 16:53:37,554 - jack - DEBUG - debug message
2016-06-06 16:53:37,555 - jack - INFO - info message
2016-06-06 16:53:37,555 - jack - WARNING - warn message
2016-06-06 16:53:37,555 - jack - ERROR - error message
2016-06-06 16:53:37,555 - jack - CRITICAL - critical message
access.log日志文件中的内容:
2016-06-06 16:53:37,555 - jack - WARNING - warn message
2016-06-06 16:53:37,555 - jack - ERROR - error message
2016-06-06 16:53:37,555 - jack - CRITICAL - critical message
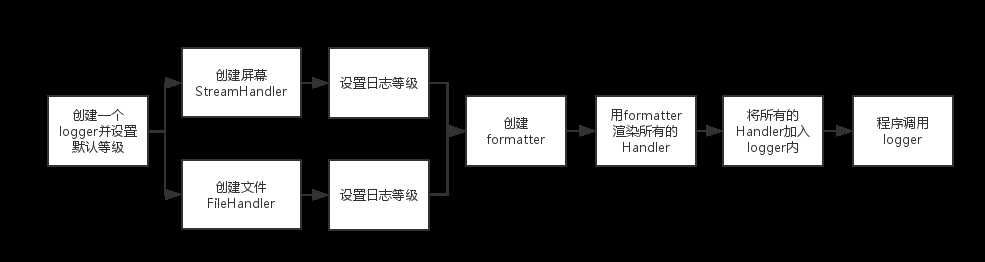
其实就是上面这么个过程,一步一步完成就可以了,逻辑其实很简单,学习模块其实就是学习一个软件,没什么复杂的。
未完待续
以上是关于python模块详解的主要内容,如果未能解决你的问题,请参考以下文章