storm集成kafka的应用,从kafka读取,写入kafka
Posted 小闪电
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了storm集成kafka的应用,从kafka读取,写入kafka相关的知识,希望对你有一定的参考价值。
storm集成kafka的应用,从kafka读取,写入kafka
by 小闪电
0前言
storm的主要作用是进行流式的实时计算,对于一直产生的数据流处理是非常迅速的,然而大部分数据并不是均匀的数据流,而是时而多时而少。对于这种情况下进行批处理是不合适的,因此引入了kafka作为消息队列,与storm完美配合,这样可以实现稳定的流式计算。下面是一个简单的示例实现从kafka读取数据,并写入到kafka,以此来掌握storm与kafka之间的交互。
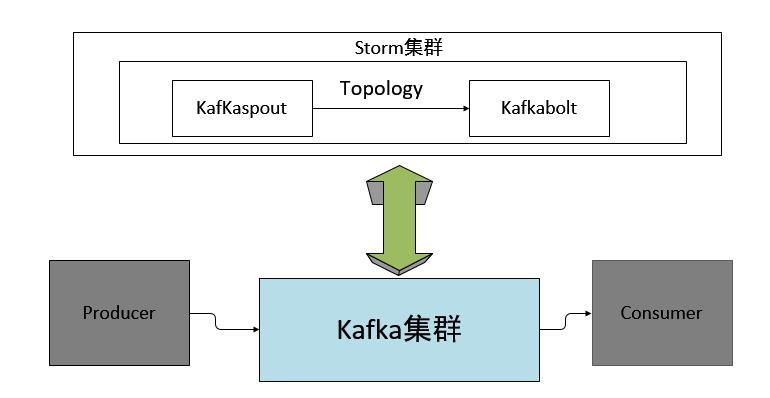
1程序框图
实质上就是storm的kafkaspout作为一个consumer,kafkabolt作为一个producer。
框图如下:
2 pom.xml
建立一个maven项目,将storm,kafka,zookeeper的外部依赖叠加起来。
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.tony</groupId> <artifactId>storm-example</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>0.9.3</version> <!--<scope>provided</scope>--> </dependency> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-kafka</artifactId> <version>0.9.3</version> <!--<scope>provided</scope>--> </dependency> <dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>2.5.0</version> </dependency> <!-- storm-kafka模块需要的依赖 --> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>2.5.0</version> <exclusions> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> <!-- kafka --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.10</artifactId> <version>0.8.1.1</version> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> </exclusions> </dependency> </dependencies> <repositories> <repository> <id>central</id> <url>http://repo1.maven.org/maven2/</url> <snapshots> <enabled>false</enabled> </snapshots> <releases> <enabled>true</enabled> </releases> </repository> <repository> <id>clojars</id> <url>https://clojars.org/repo/</url> <snapshots> <enabled>true</enabled> </snapshots> <releases> <enabled>true</enabled> </releases> </repository> <repository> <id>scala-tools</id> <url>http://scala-tools.org/repo-releases</url> <snapshots> <enabled>true</enabled> </snapshots> <releases> <enabled>true</enabled> </releases> </repository> <repository> <id>conjars</id> <url>http://conjars.org/repo/</url> <snapshots> <enabled>true</enabled> </snapshots> <releases> <enabled>true</enabled> </releases> </repository> </repositories> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <configuration> <source>1.6</source> <target>1.6</target> <encoding>UTF-8</encoding> <showDeprecation>true</showDeprecation> <showWarnings>true</showWarnings> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass></mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
3 kafkaspout的消费逻辑,修改MessageScheme类,其中定义了俩个字段,key和message,方便分发到kafkabolt。代码如下
package com.tony.storm_kafka.util; import java.io.UnsupportedEncodingException; import java.util.List; import backtype.storm.spout.Scheme; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; /* *author: hi *public class MessageScheme{ } **/ public class MessageScheme implements Scheme { @Override public List<Object> deserialize(byte[] arg0) { try{ String msg = new String(arg0, "UTF-8"); String msg_0 = "hello"; return new Values(msg_0,msg); } catch (UnsupportedEncodingException e) { // TODO: handle exception e.printStackTrace(); } return null; } @Override public Fields getOutputFields() { return new Fields("key","message"); } }
4.编写topology主类,配置kafka,提交topology到storm的代码,其中kafkaspout的zkhost有动态和静态俩种配置,尽量使用动态自寻的方式。
package org.tony.storm_kafka.common; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.StormSubmitter; import backtype.storm.generated.AlreadyAliveException; import backtype.storm.generated.InvalidTopologyException; import backtype.storm.generated.StormTopology; import backtype.storm.spout.SchemeAsMultiScheme; import backtype.storm.topology.BasicOutputCollector; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.TopologyBuilder; import backtype.storm.topology.base.BaseBasicBolt; import backtype.storm.tuple.Tuple; import storm.kafka.BrokerHosts; import storm.kafka.KafkaSpout; import storm.kafka.SpoutConfig; import storm.kafka.ZkHosts; import storm.kafka.trident.TridentKafkaState; import java.util.Arrays; import java.util.Properties; import org.tony.storm_kafka.bolt.ToKafkaBolt; import com.tony.storm_kafka.util.MessageScheme; public class KafkaBoltTestTopology { //配置kafka spout参数 public static String kafka_zk_port = null; public static String topic = null; public static String kafka_zk_rootpath = null; public static BrokerHosts brokerHosts; public static String spout_name = "spout"; public static String kafka_consume_from_start = null; public static class PrinterBolt extends BaseBasicBolt { /** * */ private static final long serialVersionUID = 9114512339402566580L; // @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } // @Override public void execute(Tuple tuple, BasicOutputCollector collector) { System.out.println("-----"+(tuple.getValue(1)).toString()); } } public StormTopology buildTopology(){ //kafkaspout 配置文件 kafka_consume_from_start = "true"; kafka_zk_rootpath = "/kafka08"; String spout_id = spout_name; brokerHosts = new ZkHosts("192.168.201.190:2191,192.168.201.191:2191,192.168.201.192:2191", kafka_zk_rootpath+"/brokers"); kafka_zk_port = "2191"; SpoutConfig spoutConf = new SpoutConfig(brokerHosts, "testfromkafka", kafka_zk_rootpath, spout_id); spoutConf.scheme = new SchemeAsMultiScheme(new MessageScheme()); spoutConf.zkPort = Integer.parseInt(kafka_zk_port); spoutConf.zkRoot = kafka_zk_rootpath; spoutConf.zkServers = Arrays.asList(new String[] {"10.9.201.190", "10.9.201.191", "10.9.201.192"}); //是否從kafka第一條數據開始讀取 if (kafka_consume_from_start == null) { kafka_consume_from_start = "false"; } boolean kafka_consume_frome_start_b = Boolean.valueOf(kafka_consume_from_start); if (kafka_consume_frome_start_b != true && kafka_consume_frome_start_b != false) { System.out.println("kafka_comsume_from_start must be true or false!"); } System.out.println("kafka_consume_from_start: " + kafka_consume_frome_start_b); spoutConf.forceFromStart=kafka_consume_frome_start_b; TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", new KafkaSpout(spoutConf)); builder.setBolt("forwardToKafka", new ToKafkaBolt<String, String>()).shuffleGrouping("spout"); return builder.createTopology(); } public static void main(String[] args) { KafkaBoltTestTopology kafkaBoltTestTopology = new KafkaBoltTestTopology(); StormTopology stormTopology = kafkaBoltTestTopology.buildTopology(); Config conf = new Config(); //设置kafka producer的配置 Properties props = new Properties(); props.put("metadata.broker.list", "192.10.43.150:9092"); props.put("producer.type","async"); props.put("request.required.acks", "0"); // 0 ,-1 ,1 props.put("serializer.class", "kafka.serializer.StringEncoder"); conf.put(TridentKafkaState.KAFKA_BROKER_PROPERTIES, props); conf.put("topic","testTokafka"); if(args.length > 0){ // cluster submit. try { StormSubmitter.submitTopology("kafkaboltTest", conf, stormTopology); } catch (AlreadyAliveException e) { e.printStackTrace(); } catch (InvalidTopologyException e) { e.printStackTrace(); } }else{ new LocalCluster().submitTopology("kafkaboltTest", conf, stormTopology); } } }
5 示例结果,testfromkafka topic里面的数据可以通过另外写个类来进行持续的生产。
topic testfromkafka的数据

topic testTokafka的数据

6 补充ToKfakaBolt,集成基础的Bolt类,主要改写Excute,同时加上Ack机制。
import java.util.Map; import java.util.Properties; import kafka.javaapi.producer.Producer; import kafka.producer.KeyedMessage; import kafka.producer.ProducerConfig; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import storm.kafka.bolt.mapper.FieldNameBasedTupleToKafkaMapper; import storm.kafka.bolt.mapper.TupleToKafkaMapper; import storm.kafka.bolt.selector.KafkaTopicSelector; import storm.kafka.bolt.selector.DefaultTopicSelector; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Tuple; /* *author: yue *public class ToKafkaBolt{ } **/ public class ToKafkaBolt<K,V> extends BaseRichBolt{ private static final Logger Log = LoggerFactory.getLogger(ToKafkaBolt.class); public static final String TOPIC = "topic"; public static final String KAFKA_BROKER_PROPERTIES = "kafka.broker.properties"; private Producer<K, V> producer; private OutputCollector collector; private TupleToKafkaMapper<K, V> Mapper; private KafkaTopicSelector topicselector; public ToKafkaBolt<K,V> withTupleToKafkaMapper(TupleToKafkaMapper<K, V> mapper){ this.Mapper = mapper; return this; } public ToKafkaBolt<K, V> withTopicSelector(KafkaTopicSelector topicSelector){ this.topicselector = topicSelector; return this; } @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { if (Mapper == null) { this.Mapper = new FieldNameBasedTupleToKafkaMapper<K, V>(); } if (topicselector == null) { this.topicselector = new DefaultTopicSelector((String)stormConf.get(TOPIC)); } Map configMap = (Map) stormConf.get(KAFKA_BROKER_PROPERTIES); Properties properties = new Properties(); properties.putAll(configMap); ProducerConfig config = new ProducerConfig(properties); producer = new Producer<K, V>(config); this.collector = collector; } @Override public void execute(Tuple input) { // String iString = input.getString(0); K key = null; V message = null; String topic = null; try { key = Mapper.getKeyFromTuple(input); message = Mapper.getMessageFromTuple(input); topic = topicselector.getTopic(input); if (topic != null) { producer.send(new KeyedMessage<K, V>(topic,message)); }else { Log.warn("skipping key = "+key+ ",topic selector returned null."); } } catch ( Exception e) { // TODO: handle exception Log.error("Could not send message with key = " + key + " and value = " + message + " to topic = " + topic, e); }finally{ collector.ack(input); } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
作 者:小闪电
出处:http://www.cnblogs.com/yueyanyu/
本文版权归作者和博客园共有,欢迎转载、交流,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。如果觉得本文对您有益,欢迎点赞、欢迎探讨。本博客来源于互联网的资源,若侵犯到您的权利,请联系博主予以删除。
以上是关于storm集成kafka的应用,从kafka读取,写入kafka的主要内容,如果未能解决你的问题,请参考以下文章
flume-kafka-storm-hdfs-hadoop-hbase
如何在cloudfoundry上使用kafka和storm?