python学习之路基础篇(第五篇)
Posted MoHan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python学习之路基础篇(第五篇)相关的知识,希望对你有一定的参考价值。
前四天课程回顾
1.python简介
2.python基本数据类型

类: int:整型 | str:字符串 | list:列表 |tuple:元组 |dict:字典 | set:集合 对象: li = [11,22,33] #列表的一个对象
s = "MoHan" #字符串的一个对象
3.函数式编程
4.装饰器
@装饰器函数名 def func(): pass
其中@装饰器函数名,程序执行到此,会进行如下三步操作:
1.将func当做参数进行传递给装饰器函数并执行 2.将装饰器函数的返回值重新赋值给func 3.执行func函数就相当于执行装饰器函数的返回值
装饰器
通过上一次课程的学习,我们已经知道了什么是装饰器,装饰器内部是如何运行的,上次课程我们说到函数可以被装饰器封装,并且通过作业的练习,已基本掌握简单装饰器的基本操作,我心里有个疑问,一个函数可以被多个装饰器装饰么?答案是肯定。
#执行程序的开关
USER_INFO = {}
USER_INFO[\'is_login\'] = False #通过is_login的值来判断用户是否已经登录
USER_INFO[\'user_type\'] = 2 #通过user_type的值来判断用户是否是管理员
#USER_INFO.get(\'is_login\',None)
def check_login(func):
def inner(*args,**kwargs):
if USER_INFO.get(\'is_login\',None):
ret = func(*args,**kwargs)
return ret
else:
print(\'请登录\')
return inner
def check_admin(func):
def inner(*args,**kwargs):
if USER_INFO.get(\'user_type\',None) == 2:
ret = func(*args,**kwargs)
return ret
else:
print(\'您无权限进行此操作\')
return inner
@check_login
@check_admin
def index():
print(\'inex\')
index()
#双层装饰器的执行顺序:check_log-------check_admin-----index
#装饰器还可有三层、四层......多层
字符串格式化
一、.python字符串格式化有两种方式:% 和 format
This PEP proposes a new system for built-in string formatting operations, intended as a replacement for the existing \'%\' string formatting operator
1.百分号方式
用法:%[(name)][flags][width].[precision]typecode
- (name) 可选,用于选择指定的key
- flags 可选,可供选择的值有:
- + 右对齐;正数前加正好,负数前加负号;
- - 左对齐;正数前无符号,负数前加负号;
- 空格 右对齐;正数前加空格,负数前加负号;
- 0 右对齐;正数前无符号,负数前加负号;用0填充空白处
- width 可选,占有宽度
- .precision 可选,小数点后保留的位数
- typecode 必选
- s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置
- r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置
- c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置
- o,将整数转换成 八 进制表示,并将其格式化到指定位置
- x,将整数转换成十六进制表示,并将其格式化到指定位置
- d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置
- e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)
- E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)
- f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
- F,同上
- g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)
- G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)
- %,当字符串中存在格式化标志时,需要用 %%表示一个百分号
注意:python中百分号格式化是不存在自动将整数转换成二进制表示的方式
#常用的%: %s :字符串 %d:数字 %f:浮点数
tp1 = "i am %s age %d" %("alex",19)
tp2 = "i am %(name)s age %(age)d" %{"name":"alex","age":19}
tp3 = "percent %.2f" %99.9762
tp4 = "percent %(pp).2f" %{"pp":99.9762}
tp5 = "percent %.2f%%" %(99.9762,)
tp6 = "i am %s" %(\'alex\')
print(tp1)
print(tp2)
print(tp3)
print(tp4)
print(tp5)
print(tp6)
程序执行结果如下:
i am alex age 19
i am alex age 19
percent 99.98
percent 99.98
percent 99.98%
i am alex
2.Format方式
[[fill]align][sign][#][0][width][,][.precision][type]
- fill 【可选】空白处填充的字符
- align 【可选】对齐方式(需配合width使用)
- <,内容左对齐
- >,内容右对齐(默认)
- =,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号+填充物+数字
- ^,内容居中
- sign 【可选】有无符号数字
- +,正号加正,负号加负;
- -,正号不变,负号加负;
- 空格 ,正号空格,负号加负;
- # 【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示
- , 【可选】为数字添加分隔符,如:1,000,000
- width 【可选】格式化位所占宽度
- .precision 【可选】小数位保留精度
- type 【可选】格式化类型
- 传入” 字符串类型 “的参数
- s,格式化字符串类型数据
- 空白,未指定类型,则默认是None,同s
- 传入“ 整数类型 ”的参数
- b,将10进制整数自动转换成2进制表示然后格式化
- c,将10进制整数自动转换为其对应的unicode字符
- d,十进制整数
- o,将10进制整数自动转换成8进制表示然后格式化;
- x,将10进制整数自动转换成16进制表示然后格式化(小写x)
- X,将10进制整数自动转换成16进制表示然后格式化(大写X)
- 传入“ 浮点型或小数类型 ”的参数
- e, 转换为科学计数法(小写e)表示,然后格式化;
- E, 转换为科学计数法(大写E)表示,然后格式化;
- f , 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- g, 自动在e和f中切换
- G, 自动在E和F中切换
- %,显示百分比(默认显示小数点后6位)
- 传入” 字符串类型 “的参数
简单小练习:
s1 = "abcdefg{0}abcdefg{0}123{1}".format(\'111\',\'7777\')
#对号入座 {0}---111,{1}----7777
print(s1)
s2 = "-----{name:s}_____{age:d}------{name:s}".format(name=\'alex\',age=12)
#根据名称来进行赋值,可以不按照顺序
print(s2)
s3 = "---{:*^20s}______{:+d}------{:x}".format(\'alex\',23,45)
#*20:占据20个位置,如果传入的参数不足20个字符用*进行填充
#^:居中显示 < 左对齐 >右对齐
#s:字符串 d:数字
#+:正数前面+,负数前面加符号
#x:将十进制自动转换成十六进制数字表示然后进行格式化 :X :b(二进制) :o(八进制)
print(s3)
#
# 程序执行结果如下:
# abcdefg111abcdefg1111237777
# -----alex_____12------alex
# ---********alex********______+23------2d
format实例
tp1 = "i am {}, age {},{}".format("alex",38,\'sir\')
#按顺序进行赋值,{}没有指定要传入的数据类型,可以将传入的任意数值类型进行格式化
tp2 = "i am {},age {},{}".format(*["seven",38,\'sir\'])
#*[]:将列表中的元素按顺序进行赋值,如果不加*则表示整个列表是一个元素,如果直接传入则会报错,所以传入的参数要
#>=前面预留的空间的个数
tp3 = "i am {0},age {1},really {0}".format(\'seven\',18)
tp4 = "i am {0},age {1},really {0}".format(*[\'seven\',18])
tp5 = "i am {name},age {age},really {name}".format(name="seven",age=18)
tp6 = "i am {name},age {age},really {name}".format(**{"name":"seven",\'age\':18})
tp7 = "i am {0[0]},age {0[1]},really {0[2]}".format([1,2,3],[11,22,33])
tp8 = "i am {:s},age {:d}".format(*[\'seven\',18])
tp9 = "i am {:s},age {:d},money {:f}".format(\'seven\',18,18888.111)
tp10 = "i am {name:s},age {age:d}".format(name=\'seven\',age=18)
tp11 = "i am {name:s},age {age:d}".format(**{\'name\':\'seven\',\'age\':18})
tp12 = "numbers:{:b},{:o},{:x},{:X},{:%} ".format(15,23,34,56,78,12.788999,23)
tp13 = "numbers: {0:b},{0:o},{0:d},{0:x},{0:X}, {0:%}".format(15)
tp14 = "numbers: {num:b},{num:o},{num:d},{num:x},{num:X}, {num:%}".format(num=15)
print(tp1)
print(tp2)
print(tp3)
print(tp4)
print(tp5)
print(tp6)
print(tp7)
print(tp8)
print(tp9)
print(tp10)
print(tp11)
print(tp12)
print(tp13)
print(tp14)
程序执行结果如下:
i am alex, age 38,sir
i am seven,age 38,sir
i am seven,age 18,really seven
i am seven,age 18,really seven
i am seven,age 18,really seven
i am seven,age 18,really seven
i am 1,age 2,really 3
i am seven,age 18
i am seven,age 18,money 18888.111000
i am seven,age 18
i am seven,age 18
numbers:1111,27,22,38,7800.000000%
numbers: 1111,17,15,f,F, 1500.000000%
numbers: 1111,17,15,f,F, 1500.000000%
更多格式化操作请参考:https://docs.python.org/3/library/string.html
生成器和迭代器
1.迭代器
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退,不过这也没什么,因为人们很少在迭代途中往后退。另外,迭代器的一大优点是不要求事先准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素,而在这之前或之后,元素可以不存在或者被销毁。这个特点使得它特别适合用于遍历一些巨大的或是无限的集合,比如几个G的文件
特点:
- 访问者不需要关心迭代器内部的结构,仅需通过next()方法不断去取下一个内容
- 不能随机访问集合中的某个值 ,只能从头到尾依次访问
- 访问到一半时不能往回退
- 便于循环比较大的数据集合,节省内存
2.生成器
一个函数调用时返回一个迭代器,那这个函数就叫做生成器(generator);如果函数中包含yield语法,那这个函数就会变成生成器
#生成器的定义:生成器也是一个函数,一个函数中如果出现yield则函数就变成生成器
#具有生成某种数据的能力
#生成器的本质:yield
def func():
yield 1
yield 2
yield 3
ret = func()
for i in ret:
print(i)
#程序执行结果如下:
1
2
3
上述代码中:func是函数称为生成器,当执行此函数func()时会得到一个迭代器。
# def func(): # print(1111) # yield 1 # print(2222) # yield 2 # print(3333) # yield 3 # ret = func() # r1 = ret.__next__() #进入函数找到yield,获取yield后面的值1 # print(r1) # r2 = ret.__next__() #进入函数找到yield,获取yield后面的值2 # print(r2) # r3 = ret.__next__() #进入函数找到yield,获取yield后面的值3 # print(r3) # r4 = ret.__next__() # print(r4) # 程序执行结果如下: # 1111 # 1 # 2222 # 2 # 3333 # 3
3.实例
利用生成器自定义myrange
def myrange(arg):
start = 0
while True:
if start > arg:
return
yield start
start += 1
利用迭代器访问myrange
ret = myrange(3) r = ret.__next__() print(r) r = ret.__next__() print(r) r = ret.__next__() print(r) r = ret.__next__() print(r)
递归
引入:函数的调用
#函数的调用
#执行a()时,a去调用函数b,执行函数b()时,b去调用函数c,执行函数c时,c去调用函数d,
#执行d()时,返回给123
def d():
return \'123\'
def c():
r = d()
return r
def b():
r = c()
return r
def a():
r = b()
return r
ret = a()
print(ret)
程序执行结果如下:
123
从上面的代码我们可以看出,执行一个函数a()时,a去调用函数b,而执行函数b时,b又去调用函数c,这个过程称之为函数的调用。函数在执行的时候可以去调用别的函数,是不是也可以调用自身呢,答案是可以的,执行函数的时候去调用自身来进行执行的过程即是递归,说白了,递归就是函数自己调用自己的过程。
#递归函数
def func(n):
n += 1
if n > 4:
return \'end\'
return func(n)
r = func(1)
print(r)
#程序执行结果如下:
end
模块
模块是一个功能的集合
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
模块的分类:
- 自定义模块:自己编写的模块
- 内置模块(python自带的os sys file json)
- 第三方模块
模块的导入:
Python之所以应用越来越广泛,在一定程度上也依赖于其为程序员提供了大量的模块以供使用,如果想要使用模块,则需要导入。导入模块有一下几种方法:
import module #导入模块下的全部模块 from module.xx.xx import * #导入模块下的全部模块 from module.xx.xx import xx #导入某块下的指定模块 from module.xx.xx import xx as rename #导入指定模块并给他设置别名
导入模块其实就是告诉Python解释器去解释那个py文件
- 导入一个py文件,解释器解释该py文件
- 导入一个包,解释器解释该包下的 __init__.py 文件
那么问题来了,导入模块时是根据那个路径作为基准来进行的呢?即:sys.path
import sys print(sys.path) 输出结果: [\'D:\\\\PythonS13\\\\Day5\\\\class\', \'D:\\\\PythonS13\', \'C:\\\\python35\\\\python35.zip\', \'C:\\\\python35\\\\DLLs\', \'C:\\\\python35\\\\lib\', \'C:\\\\python35\', \'C:\\\\python35\\\\lib\\\\site-packages\']
如果sys.path路径列表没有你想要的路径,可以通过 sys.path.append(\'路径\') 添加。
import sys import os project_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(project_path)
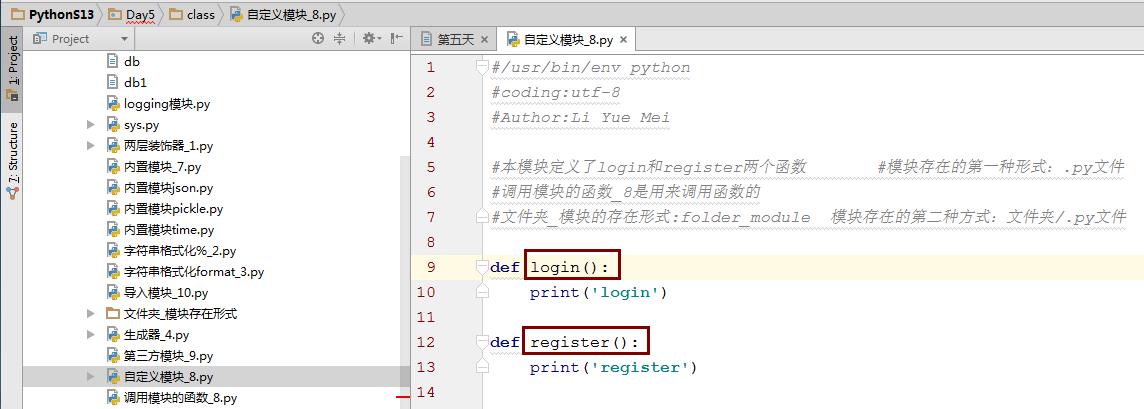
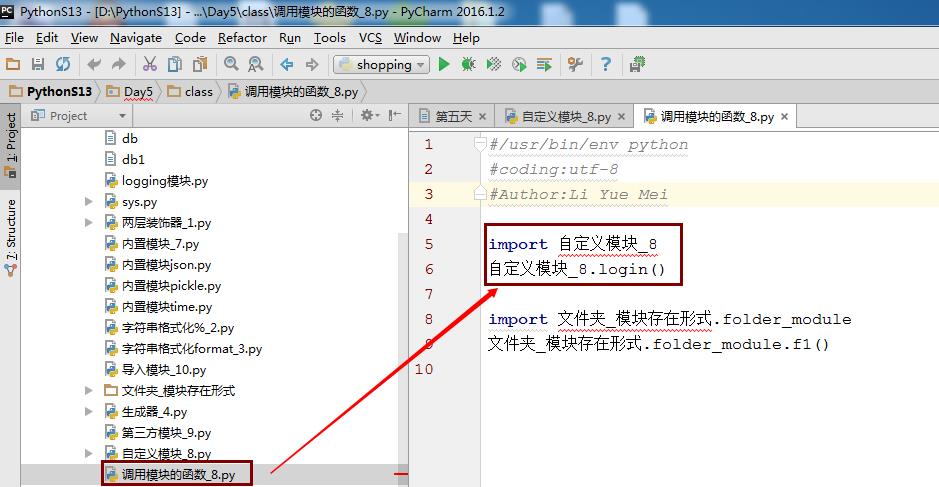
自定义模块
自定义模块一般都是自己写的可以是一个独立的.py文件,也可以是一个文件夹,但是普通的文件夹并不是一个模块,一个模块必须是包含__init__的目录。
自定义一个名为“自定义模块_8”的模块,然后在“调用模块的函数_8”程序里面调用,如果要使用模块里面方法,直接使用模块名 .方法即可
内置模块
内置模块是Python自带的功能,在使用内置模块相应的功能时,需要【先导入】再【使用】
1.sys
用于提供对Python解释器相关的操作:
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdin 输入相关 sys.stdout 输出相关 sys.stderror 错误相关
实例:进度百分比
import sys
import time
def view_bar(num, total):
rate = float(num) / float(total)
rate_num = int(rate * 100)
#r = \'\\r%d%%\' % (rate_num, )
r = \'\\r[%-100s]%d%%\' % (\'=\' * rate_num, rate_num,)
sys.stdout.write(r)
sys.stdout.flush()
if __name__ == \'__main__\':
for i in range(0, 101):
time.sleep(0.1)
view_bar(i, 100)
2.os
用于提供系统级别的操作:
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: (\'.\')
os.pardir 获取当前目录的父目录字符串名:(\'..\')
os.makedirs(\'dir1/dir2\') 可生成多层递归目录
os.removedirs(\'dirname1\') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir(\'dirname\') 生成单级目录;相当于shell中mkdir dirname
os.rmdir(\'dirname\') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(\'dirname\') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","new") 重命名文件/目录
os.stat(\'path/filename\') 获取文件/目录信息
os.sep 操作系统特定的路径分隔符,win下为"\\\\",Linux下为"/"
os.linesep 当前平台使用的行终止符,win下为"\\t\\n",Linux下为"\\n"
os.pathsep 用于分割文件路径的字符串
os.name 字符串指示当前使用平台。win->\'nt\'; Linux->\'posix\'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
第三方模块
下载安装有两种方式:
通过第三方的集成安装
yum pip apt-get ...
通过源码安装
下载源码 解压源码 进入目录 编译源码 python setup.py build 安装源码 python setup.py install
注:在使用源码安装时,需要使用到gcc编译和python开发环境
yum install gcc yum install python-devel 或 apt-get python-dev
下面我们以安装request来进行说明
requests
Python标准库中提供了:urllib等模块以供Http请求,但是,它的 API 太渣了。它是为另一个时代、另一个互联网所创建的。它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务
import urllib.request f = urllib.request.urlopen(\'http://www.webxml.com.cn//webservices/qqOnlineWebService.asmx/qqCheckOnline?qqCode=424662508\') result = f.read().decode(\'utf-8\')
import urllib.request req = urllib.request.Request(\'http://www.example.com/\') req.add_header(\'Referer\', \'http://www.python.org/\') r = urllib.request.urlopen(req) result = f.read().decode(\'utf-8\')
注:更多见Python官方文档:https://docs.python.org/3.5/library/urllib.request.html#module-urllib.request
Requests 是使用 Apache2 Licensed 许可证的 基于Python开发的HTTP 库,其在Python内置模块的基础上进行了高度的封装,从而使得Pythoner进行网络请求时,变得美好了许多,使用Requests可以轻而易举的完成浏览器可有的任何操作。
1、安装模块
python - m pip install requests
# 1、无参数实例
import requests
ret = requests.get(\'https://github.com/timeline.json\')
print(ret.url)
print(ret.text)
# 2、有参数实例
import requests
payload = {\'key1\': \'value1\', \'key2\': \'value2\'}
ret = requests.get("http://httpbin.org/get", params=payload)
print(ret.url)
print(ret.text)

# 1、无参数实例
import requests
ret = requests.get(\'https://github.com/timeline.json\')
print(ret.url)
print(ret.text)
# 2、有参数实例
import requests
payload = {\'key1\': \'value1\', \'key2\': \'value2\'}
ret = requests.get("http://httpbin.org/get", params=payload)
print(ret.url)
print(ret.text)
# 1、基本POST实例
import requests
payload = {\'key1\': \'value1\', \'key2\': \'value2\'}
ret = requests.post("http://httpbin.org/post", data=payload)
print(ret.text)
# 2、发送请求头和数据实例
import requests
import json
url = \'https://api.github.com/some/endpoint\'
payload = {\'some\': \'data\'}
headers = {\'content-type\': \'application/json\'}
ret = requests.post(url, data=json.dumps(payload), headers=headers)
print(ret.text)
print(ret.cookies)
requests.get(url, params=None, **kwargs)
requests.post(url, data=None, json=None, **kwargs)
requests.put(url, data=None, **kwargs)
requests.head(url, **kwargs)
requests.delete(url, **kwargs)
requests.patch(url, data=None, **kwargs)
requests.options(url, **kwargs)
# 以上方法均是在此方法的基础上构建
requests.request(method, url, **kwargs)
更多requests模块相关的文档见:http://cn.python-requests.org/zh_CN/latest/
以上是关于python学习之路基础篇(第五篇)的主要内容,如果未能解决你的问题,请参考以下文章